
This content originally appeared on raganwald.com and was authored by Reginald Braithwaite
With the demise of Posterous, I was motivated to “get my blogging house in order” and move all of my blogging onto Github. I’ve written about using Jekyll and Github Pages elsewhere,1 but the short form is:
- I have my own domains via registrar gandi.net. They point to Github’s IP.
- Each blog gets a repository.
- The repository has a
CNAMEfile containing the blog’s domain name. For example, this one. - Each repository is set up with various Jekyll things like a
_config.ymlfiles, folders for the_layoutsand_includesthat Liquid Templates need, and so on. - I have some Liquid Template stuff stuff going on to associate post tags with books to “advertise” in the margin and to include a list of the published posts in
index.html. - Atom and RSS feeds are handled by more Liquid markup.
Everything up to this point is a standard blog.
literate coffeescript
Recently, Jeremy Ashkenas released a new feature within CoffeeScript: The ability to parse what he calls “Literate CoffeeScript:” CoffeeScript that lives within a Markdown document. The CoffeeScript transpiler will now ignore the markdown and transpile CoffeeScript in the code sections.2
I recently started writing a serious of posts about an enchanted forest. These posts take the form of a story punctuated with code examples. Literate CoffeeScript is obviously terrific for documenting code, but I thought it might also be ideal for blogging. So I set up a workflow.
First, I include a code sample in my blog. If you’re not 100% familiar with Markdown and code, the raw markdown source is here. It ends up looking like this:
factorial = (n) ->
if n = 0
1
else
n * factorial(n-1)
I then add some jasmine-node specifications. Obviously, I have node.js installed along with jasmine and jasmine-node.
describe "my factorial", ->
it "should return one for zero", ->
expect( factorial(0) ).toEqual 1
I could run these manually, but it’s awkward because while CoffeeScript has been updated to handle “literate” markdown, jasmine-node has not. So jasmine-node is looking for ordinary CoffeeScript and will choke on Literate CoffeeScript. So I’d have to use coffee to compile the Literate CoffeeScript to JavaScript and then run jasmine-node on the JavaScript.
I hacked together the laziest of crappy shell scripts to do it for me:
"
#!/bin/sh
rm -f ~/Dropbox/sites/raganwald.github.com/_specs/*.js
if [ $@ > 0 ]; then
coffee --output ~/Dropbox/sites/raganwald.github.com/_specs --compile $1 $2 $3 $4 $5 $6 $7 $8 $9
else
coffee --output ~/Dropbox/sites/raganwald.github.com/_specs --compile ~/Dropbox/sites/raganwald.github.com/_posts/enchanted-forest/*.coffee.md
fi
jasmine-node ~/Dropbox/sites/raganwald.github.com/_specs --matchall
"
I added the quotes here so that the CoffeeScript compiler will ignore the shell script in this post. The script compiles the post(s) I specify into the _specs folder and then runs them (by default it does the enchanted forest posts in bulk). So whenever I add a new snippet, I write some expectations and then run the post:
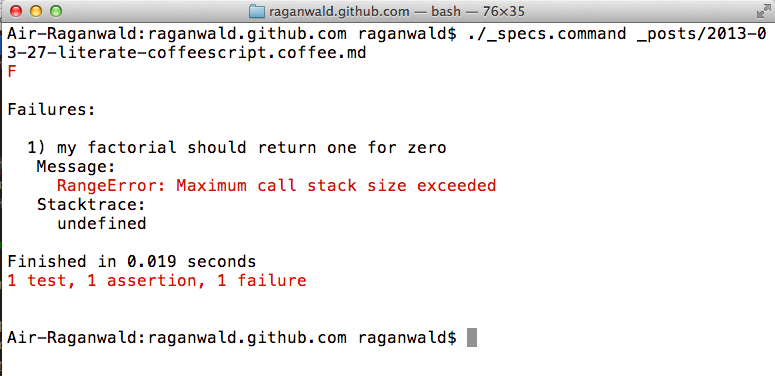
And now I know that I need to change the = to is in the code above.
weighing the benefits
Obviously, it’s a benefit to find bugs and fix them before my readers find them and send me pull requests (this blog is a Github Repo!). But it’s also a benefit to have an incentive to write tests. I don’t do TDD in a blog post, but writing tests after the fact does make me think a little more about the case analysis and I think it’s a benefit for readers.
The downside is that the snippets become quite a bit longer thanks to the expectations. In my stories, I use a little JavaScript to hide the snippets and readers can click a link to expand them. I now use a similar approach to hiding the expectations in any post with a special hide-specs tag.
But in the mean time, I find that when I’m writing CoffeeScript, it’s a win to be able to run my expectations right in my posts. If you’re blogging with Markdown, consider setting up your own Literate CoffeeScript workflow. It’s a time-saver and make sit easy to get the code right.
And if you aren’t using CoffeeScript… Why not use Literate CoffeeScript as an excuse to give it a try?
notes:
-
At this time, Literate CoffeeScript respects code indented with four or more spaces. Hopefully, it will one day respect various other flavours of Markdown code markup such as code fences or even Liquid highlight tags. ↩
This content originally appeared on raganwald.com and was authored by Reginald Braithwaite
Reginald Braithwaite | Sciencx (2013-03-27T00:00:00+00:00) My Literate CoffeeScript Blogging Workflow. Retrieved from https://www.scien.cx/2013/03/27/my-literate-coffeescript-blogging-workflow-2/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.