
This content originally appeared on Hugo “Kitty” Giraudel and was authored by Hugo “Kitty” Giraudel
N26 has been using Jenkins for as long as I’ve been part of this company. Over the last few years, I have been responsible for the quality of our delivery, and this involved getting my hands dirty with Jenkins. I learnt a lot, sometimes the hard way, and thought I’d share what I know before I leave the company and loose access to the code.
Please note that I am by no mean a Jenkins expert. I’m a frontend developer at heart, so this is all pretty alien to me. I just wanted to share what I learnt but this might not be optimal in any way.
- Go scripted
- Jenkins fails fast
- Conditional parallelisation
- Mark stages as skipped
- Built-in retry
- Manual stage retry
- Confirmation stage
- Handle aborted builds
- Build artefacts
Go scripted
The declarative syntax is nice for simple things, but it is eventually quite limited in what can be done. For more complex things, consider using the scripted pipeline, which can be authored with Groovy.
I would personally recommend this structure:
// All your globals and helpers
node {
try {
// Your actual pipeline code
} catch (error) {
// Global error handler for your pipeline
}
}For more information between the scripted and the declarative syntaxes, refer to the Jenkins documentation on the pipeline syntax.
Jenkins fails fast
By default, Jenkins tends to resort to fast failing strategies. Parallel branches will all fail if one of them does, and sub-jobs will propagate their failure to their parent. These are good defaults in my opinion, but they can also be a problem when doing more complex things.
When parallelising tasks with the parallel function, you can opt-out to this fast-failing behaviour with the failFast key. I’m not super comfortable with the idea of having an arbitrarily named key on the argument of parallel but heh, it is what it is.
Map<String, Object> branches = [:]
// Opt-out to fail-fast behaviour
branches.failFast = false
branches.foo = { /* … */ }
branches.bar = { /* … */ }
parallel branchesFor programmatically scheduled jobs, you can also opt-out the failures being propagated up the execution tree with the propagate option:
final build = steps.build(
job: 'path/to/job',
parameters: [],
propagate: false
)The nice thing about this is that you can then use build.status to read whether the job was successful or not. We use that when scheduling sub-jobs to run our end-to-end tests, and reacting to tests having failed within terminating the parent job.
Conditional parallelisation
For performance reasons, we have a case where we want to run two tasks in parallel (foo and bar for sake of simplicty), but whether or not one of these tasks (bar) should run at all depends on environment factors. It took a bit of fidling to figure out how to skip the parallelisation when there is only one branch:
def branches = [:]
// Define the branch that should always run
branches.foo = { /* … */ }
if (shouldRunBar) {
branches.bar = { /* … */ }
parallel branches
} else {
// Otherwise skip parallelisation and manually execute the first branch
branches.foo()
}Mark stages as skipped
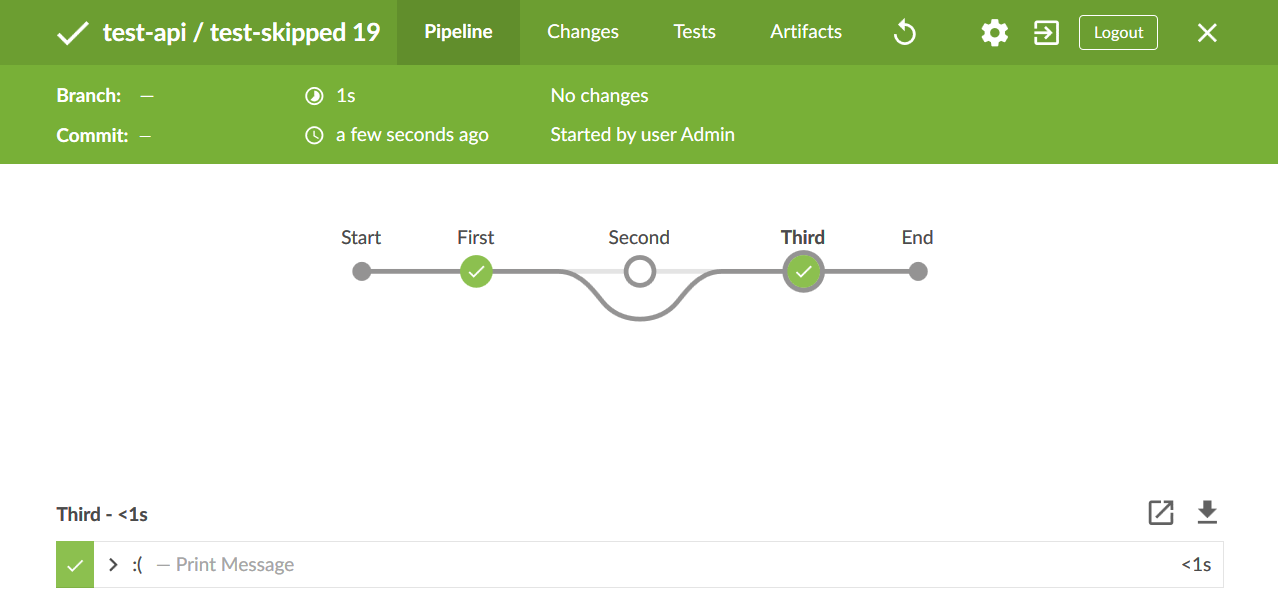
I don’t know how universal this is, but if you would like to mark a stage as actually skipped (and not just guard your code with a if statement), you can use the following monstrosity. This will effectively change the layout in BlueOcean to illustrate the skip.
org.jenkinsci.plugins.pipeline.modeldefinition.Utils.markStageSkippedForConditional("${STAGE_NAME}")For instance:
stage('Second') {
if (env == 'live') {
skipStage()
} else {
// Test code
}
}
Built-in retry
It can happen that some specific tasks are flaky. Maybe it’s a test that sometimes fail, or a fragile install, or whatnot. Jenkins has a built-in way to retry a block for a certain amount of times.
retry (3) {
sh "npm ci"
}Manual stage retry
Our testing setup is pretty complex. We run a lot of Cypress tests, and they interact with the staging backend, so they can be flaky. We cannot afford to restart the entire build from scratch every time a request fails during the tests, so we have built a lot of resilience within our test setup.
On top of automatic retrying of failing steps (both from Cypress behaviour and from a more advanced home made strategy), we also have a way to manually retry a stage if it failed. The idea is that it does not immediately fail the build—it waits for input (“Proceed” or “Abort”) until the stage either passes or is manually aborted.
stage('Tests') {
waitUntil {
try {
// Run tests
return true
} catch (error) {
// This will offer a boolean option to retry the stage. Since
// it is within a `waitUntil` block, proceeding will restart
// the body of the function. Aborting results in an abort
// error, which causes the `waitUntil` block to exit with an
// error.
input 'Retry stage?'
return false
}
}
}Confirmation stage
When you are not quite ready for continuous deployment, having a stage to confirm whether the build should deploy to production can be handy.
stage('Confirmation') {
timeout(time: 60, unit: 'MINUTES') {
input "Release to production?"
}
}We use the input command to await for input (a boolean value labeled “Proceed” or “Abort” by default). If confirmed, the pipeline will move on to the next instruction. If declined, the input function will throw an interruption error.
We also wrap the input command in a timeout block to avoid having builds queued endlessly all waiting for confirmation. If no interaction was performed within an hour, the input will be considered rejected.
To avoid missing this stage, it can be interesting to make it send a notification of some sort (Slack, Discord, email…).
Handle aborted builds
To know whether a build is aborted, you could wrap your entire pipeline in a try/catch block, and then use the following mess in the catch.
node {
try {
// The whole thing
} catch (error) {
if ("${error}".startsWith('org.jenkinsci.plugins.workflow.steps.FlowInterruptedException')) {
// Build was aborted
} else {
// Build failed
}
}
}Build artefacts
It can be interesting for a build to archive some of its assets (known as “artefacts” in the Jenkins jargon). For instance, if you run Cypress tests as part of your pipeline, you might want to archive the failing screenshots so they can be browsed from the build page on Jenkins.
try {
sh "cypress run"
} catch (error) {
archiveArtifacts(
artifacts: "cypress/screenshots/**/*.png",
fingerprint: true,
allowEmptyArchive: true
)
}Artefacts can also be retrieved programmatically across builds. We use that feature to know which tests to retry in subsequent runs. Our test job archives a JSON file listing failing specs, and the main job collects that file to run only these specs the 2nd time.
final build = steps.build(job: 'path/to/job', propagate: false)
// Copy in the root directory the artefacts archived by the sub-job,
// referred to by its name and job number
if (build.status = 'FAILURE') {
copyArtifacts(
projectName: 'path/to/job',
selector: specific("${build.number}")
)
}That’s about it. If you think I’ve made a gross error in this article, please let me know on Twitter. And if I’ve helped you, I would also love to know! ?
This content originally appeared on Hugo “Kitty” Giraudel and was authored by Hugo “Kitty” Giraudel
Hugo “Kitty” Giraudel | Sciencx (2020-11-17T00:00:00+00:00) Everything I know about Jenkins. Retrieved from https://www.scien.cx/2020/11/17/everything-i-know-about-jenkins/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.