
This content originally appeared on Level Up Coding - Medium and was authored by Burak Arslan
A Brief Introduction of Web Scraping & Regression Models
For my second project at Data Science Bootcamp at Istanbul Data Science Academy; I tried to find out if it is possible to determine a player’s value by his 2019/2020 season statistics. This project is about getting hands-on experience on web scraping, regression models and cross validation. My target was to predict their values. I scraped data from famous football value and statistics site: transfermarkt.de. There was a problem here about the values. They were currently updated values based on their past and current performance. But the statistics that I used were from the previous season.

Data Fetching by Web Scraping
I fetched player statistics from 2019–2020 Big 5 European Leagues Stats (players) | FBref.com and player values from transfermarkt.de. First I fetched data from multiple pages for various statistics including attacking, defending, creativity, passing, shooting and miscellaneous key performance indicators. With BeautifulSoup I parsed the data.

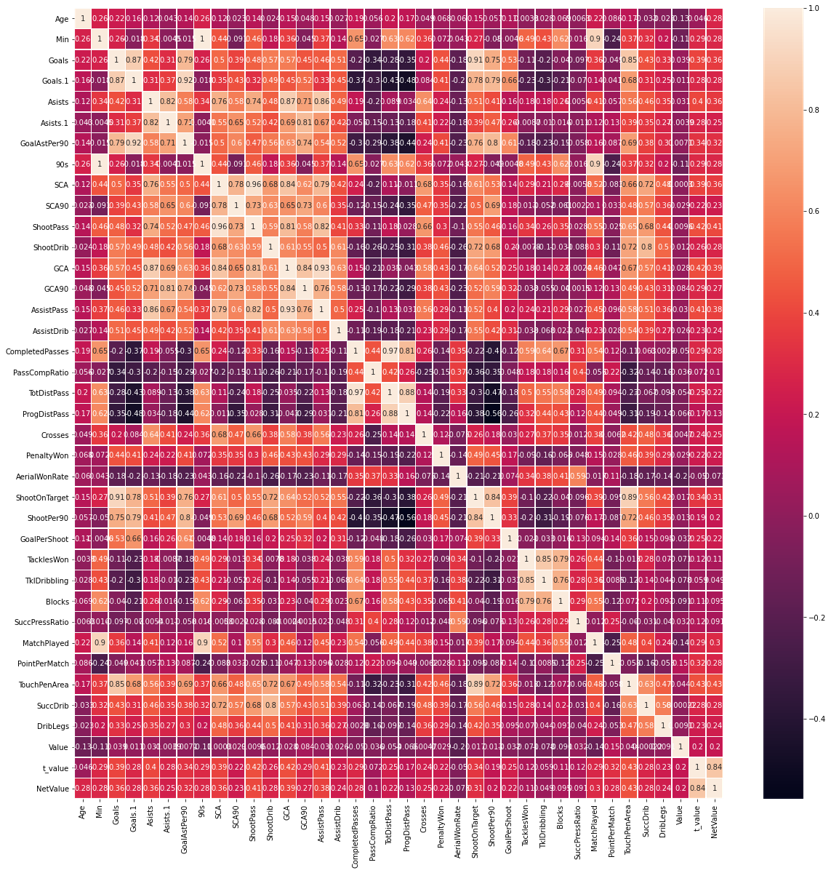
I repeated the code above and then merged all data into one frame. Here is a snapshot of the correlation of each item, that was created by seaborn heatmap function.
Features : Position, Age, Min, Goals, GoalsPerGame, Asists, AsistsPerGame, GoalAstPer90, 90s, SCA, SCA90, ShootPass,ShootDrib, GCA, GCA90, AssistPass, AssistDrib,CompletedPasses, PassCompRatio, TotDistPass, ProgDistPass,Crosses, PenaltyWon, AerialWonRate, ShootOnTarget, ShootPer90,GoalPerShoot, TacklesWon, TklDribbling, Blocks,SuccPressRatio, MatchPlayed, PointPerMatch, TouchPenArea,SuccDrib, DribLegs, PlayerType, League
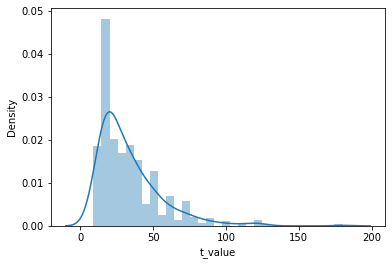
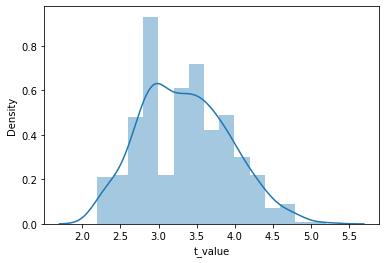
As target I fetched data from transfermarkt.de. Those were estimated values so they were all rounded. The players’ values had a skewed distribution. We know from theory that the symmetrically distributed data will help us got better results when we are building our models. Logarithmic transformation help us to transform skewed player values into a more normalized distribution. You can see how the distribution change after transformation is applied.
New Features for Better Fitting
Age groups instead of Age: I binned the data into groups that would correlate with the player's value.
Winner: Playing in a big club is always positive for the players’ market value. To determine this, I created a kpi called winner that calculated as the following formula:
winner = “Point per Match Played” ^ 2 * Played Match count
Goal Change Creator: I created a kpi to determine players that had an effect on teams’ scoring. Instead of ‘Assist’, ‘Shoot on Target’, ‘Dribbling lead to assist’, ‘pass lead to assist’, ‘Penalty won’, ‘Successful pressing at 3rd Area’.
Features that were converted to categorical variable into dummy/indicator variables: League and Player Position. Some Leagues are more challenging than the others, so the same statistics are more valuable there. And from data set, we know player value is highly correlated with the position he plays.
I also removed features that had a high correlation between one another. For example, players that had touched the ball in the penalty area scored more goals than other players.
I also had to remove players that substituted mostly; because they had no sufficient statistics. Prediction performance of our models heavily depends on data; so removing data means a decrease in model performance.
For modeling, I used various regression models from scikit-learn library. For better fitting, I created separate models for different positions. I trained different models for forward, midfield, and defense players. Because for each position the importance of the features can be different. For example, for a forward position, the number of touching the ball in the opponent penalty area is very correlated with the player’s value, but for a defense player it is not.
Cross validation is key to success. For training the data and testing I highly recommend using cross validation. By having different slices of data and training it, you will be more prepared for real life challenges. Kfold is a great function to automate this process, please check it. You can see a simple code for cross validation using kfold below.
After cross validation and fitting multiple models, Linear Regression is the best one-having min MSE- above the other regression methods. So I used it for training my data.
Result
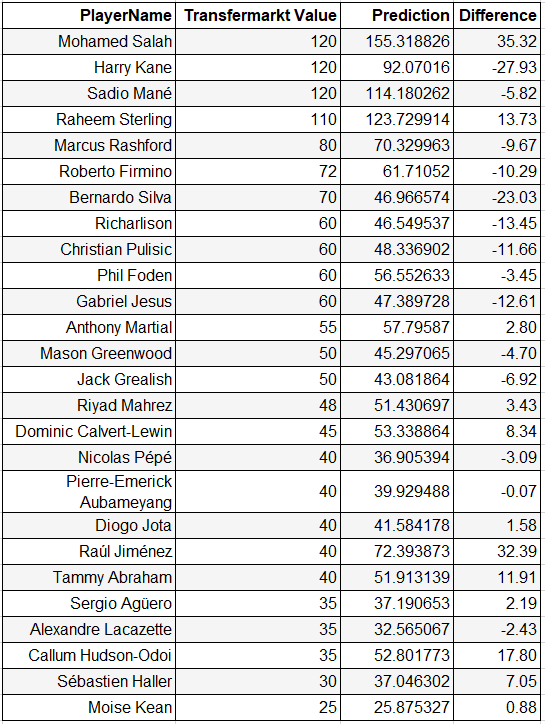
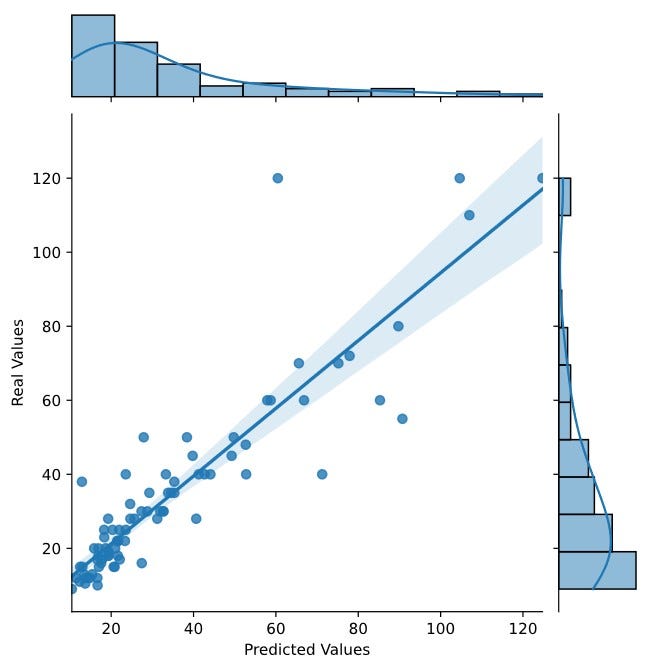
Here is the prediction of some players vs their Transfermarkt values. I retransformed the value back in order to show more human friendly numbers. Here are some top players and their Transfermarkt values versus my prediction values (million Euro) and also a chart that compare player values vs prediction.
Future Work
There are some issues that can not be figured out from statistics. As future work, we need to figure out how to overcome these issues.
- Team members may affect each other’s statistics.
- Substitute players has missing statistics, so we are losing data.
- Some players are injury-prone. Clubs avoid to sign a player who was frequently injured.
- Players’ popularity in their country is important if the they have a few elite players. Keisuke Honda is a good example of this. Clubs can pay then their actual value to gain popularity in that regions.
- Some people can handle stress, others can’t. Big clubs need players that can handle stress and can play big matches.
- Player leadership, work rate, and ethics are essential. Talent is not enough.
- The economic strength and prestige of the club.
Please share your insights about how these issues can be handle. For presentation & codes please check my github.
Thanks for reading.
Is It Possible to Predict Football Players’ Value was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Burak Arslan
Burak Arslan | Sciencx (2021-02-09T04:07:57+00:00) Is It Possible to Predict Football Players’ Value. Retrieved from https://www.scien.cx/2021/02/09/is-it-possible-to-predict-football-players-value/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.