
This content originally appeared on Level Up Coding - Medium and was authored by Gregory Pabian
Introduction
As a software developer, I have observed various methodologies for choosing the primary key of a table. Some programmers exhibit proclivity for purposefully creating new columns to serve as the aforementioned key, while the others usually look for a solution that involves the already-existing columns. I would like to approach the said problem from an engineering perspective, taking into account available theories and common experiences, especially in the distributed-systems department.
Candidate Keys
When designing a table, database designers should ask themselves the following question — how to identity a particular row inside? The process of finding an answer might in turn reveal existence of multiple ways of providing identification. I find it best to explain the conundrum using an example.
A user of a fictitious system I am building for the purpose of this article has the subsequent obligatory attributes:
- a single e-mail address,
- the ordered list of legal names (it varies from culture to culture, but the Anglosphere widely recognises first, middle and last names),
- the creation timestamp of the user’s entry, encoded in Unix Epoch time.

One could say the very e-mail address can identify a particular user but I disagree. Any user might decide to switch to a different address or the ownership of a certain address can change, accidentally or not. Even though it sounded like a good candidate, the search must continue.
A similar reasoning applies to legal names — under circumstances permitted by law, their holders can change them with relative ease. Two unrelated people might share the same names by accident, not to mention that within every culture, there exists a finite number of legally recognised names. Additionally, family tradition may drive many generations to give their progenies the exact same name (consider junior and senior suffixes in the English-speaking countries).
Lastly, two users may share the same creation timestamp (second-wise), even though some readers might consider collisions unlikely to happen. In order to eliminate feasibility of such a situation, the timestamp must become distinct within the table. This allows me to declare the first candidate for unique identification of a row — the creation timestamp.
Surrogate keys
In case I could not find any reasonable candidates, I would have to create one myself — the infamous ID attribute, with its value either defined by an integer sequence or taken from a random UUID generator. As the value of such an attribute does not come as the result of a function of other attributes’ values, nobody can calculate IDs without asking the database engine first.

Taking distributed systems into account, lack of direct control over ID creation enforces a specific order of information spreading through a system, which adds up to the list of concessions a systems architect must keep aware of when designing software. One could mitigate the aforesaid limitation by using UUIDs and generating them on demand, before sending queries to the database.
At last, I have found two non-nullable columns I could use for identifying rows in my table. Using more academic language, I might say I ended up with two candidate keys. Now I need to choose one to declare it as the primary key of the table.
Primary Key
I have already established there might exist multiple candidate keys for one table. A database designer can promote one of them to the primary key — however, depending on the chosen database engine, it might not necessarily require creating such a key. Having the primary key defined though provides the database consumers with the following benefits:
- ability to identify each row in the table using a fast equality lookup,
- storing the rows in the order influenced by the primary key (this means that the structured index follows the primary key, but every database designer should check the documentation of the chosen engine before relying on this feature),
- ability to use the primary key as a foreign key in a different table,
- (cascading) referential integrity of operations that include foreign keys.
Two obvious types of primary keys predominate in RDBMS databases:
- regular (single-column) keys,
- compound (multiple-column) keys — most database engines limit the effective number of columns included in such a key.
I could easily chose a regular primary key from either the ID column or the creation-timestamp column — the former would act as a surrogate key and the latter as a natural key. Since regular primary keys behave in a very straightforward manner, I would like to discuss the intrinsics of compound primary keys in the next paragraph.
Compound Primary Key
By definition, every compound primary key spans over multiple columns. This means that the very value of such a key contains the concatenated values of all the involved columns (in the predefined order). This goes against a principle which dictates that the very value of any primary key should stay as short as humanly possible.
Additionally, sharing such a key in a distributed system involves passing a tuple of values around, a solution I consider a nuisance on its own. Serialization of multiple values (represented either as an object or as an ordered list) involves more protocol work than serialization of a single value, string or number alike. Fortunately, one can reduce any compound primary key to a regular key using hashing, which I will demonstrate using an example below.
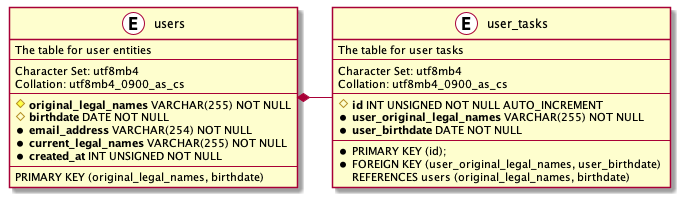
To show hashing in action, I could extend the previously referenced table by providing two new columns:
- current legal names (the previous legal names would require rebranding as original legal names upon registration),
- the birthdate.
I could claim that probability of two people sharing original legal names and their birthdate remains so low that I should treat it as virtually impossible to happen — collisions, anyhow, might occur under various circumstances. This allows for creation of a compound primary key consisting of the original legal names and the birthdate of every user. Sadly, such an approach requires foreign keys in different tables to utilise two columns, as shown in the example underneath:
Hash functions
The following methods allow to reduce a compound primary key to a single-column regular key:
- creating a new column with concatenated values of the selected columns (I would advise the reader to think about possible problems with this solution),
- creating a new column to serve as the hash of the selected columns’ values.
The hash function should evaluate the values in a predefined key order (probably alphanumerical) — this means that pure JSON stringifying might yield undesired data without accounting for the said order. A JavaScript or TypeScript developer could provide the sorted list of keys as the second parameter of the JSON.stringify function, as shown down below:
I could think of one fundamental drawback of this solution — the return value of the aforementioned function has no constant length. For complex objects with several attributes, the return value might consist of hundreds of bytes — therefore, a database designer might not easily find the necessary upper limit for the column length.
Fortunately, anybody can reduce an arbitrary-length string to a constant-length one using a carefully designed hash function. Since renowned mathematicians have built plethora of these functions over the past decades, I invite the reader to research the topic on their own.
Summary
For any distributed system, the ability to calculate the primary key of a particular table (entity) without asking the database engine beforehand could allow some operations to happen before committing the very entity to the selected database. Identifying a row using only one fixed-size column instead of leveraging multiple columns provides many advantages to the system, especially when sharing entity information over numerous subsystems. Lastly, a hash function might reduce values coming from multiple columns into a value writable to a single-column.
Primary Keys in Distributed Systems was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Gregory Pabian
Gregory Pabian | Sciencx (2021-02-22T02:44:51+00:00) Primary Keys in Distributed Systems. Retrieved from https://www.scien.cx/2021/02/22/primary-keys-in-distributed-systems/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.