
This content originally appeared on Level Up Coding - Medium and was authored by Ivan Zakharchuk
Data preprocessing and normalization become very important when it comes to the implementation of different Machine Learning Algorithms. As data preprocessing can affect the outcome of the learning model significantly, it is very important that all features are on the same scale. Normalization is important in such algorithms as k-NN, support vector machines, neural networks, principal components. The type of feature preprocessing and normalization that’s needed can depend on the data.
Preprocessing types
There are several different methods for data rescaling. The images below shows the four most common that could be used in machine learning algorithms.
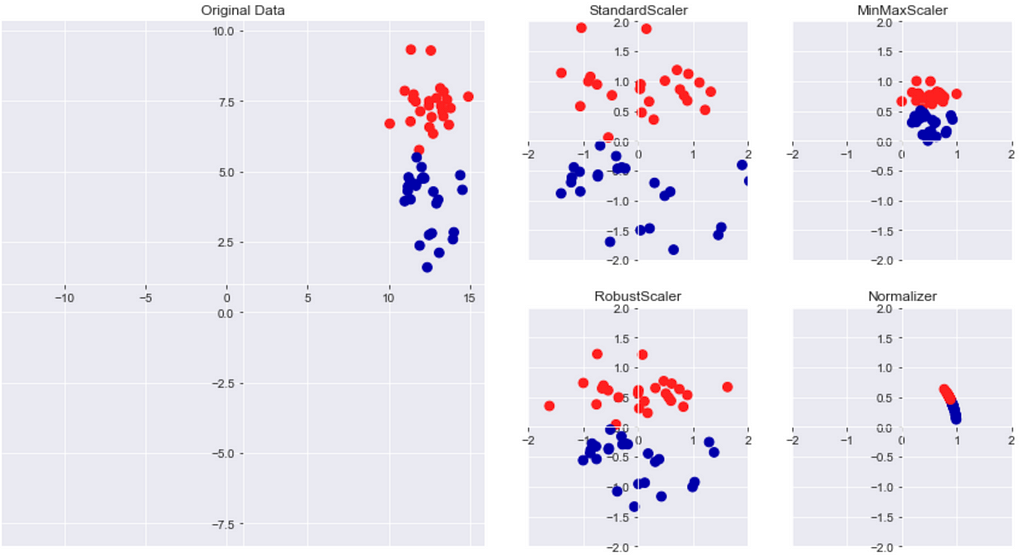
The first plot under original data shows a synthetic two-class classification dataset with only two features. The first feature (the x-axis value) is in the range 10 and 15. The second feature (the y-axis value) is between 1 and 9. Four plots on the right show different ways to transform the data that yield more standard ranges.
StandardScaler ensures that for each feature in the dataset mean is 0 and variance is 1 and brings all features to the same magnitude. This scaling doesn’t ensure any minimum and maximum values for the features.
RobustScaler works similar to StandardScaler but uses the median and quartiles instead of mean and variance. This makes scaler ignore data points that are very different from the rest (measurement errors).
Normalizer scales each data point such that the feature vector has a Euclidian length of 1. Every data point is scaled by a different number (by the inverse of its length). This normalization used when the only direction of the data matters, not the length of the feature vector.
MinMaxScaler transforms all the input variables, so they’re all on the same scale between zero and one. The method computes the minimum and maximum values for each feature on the training data, and then applies the min - max transformation for each feature.

Applying Scaling in ML
The following example shows how to apply MinMaxScaler to features. First create the scalar object, and then call the fit method using the training data X_train. This will compute the min and max feature values for each feature in this training dataset. Then to apply the scalar, call its transform method, and pass in the data you needed to rescale. The output will be the scale version of the input data. In this case, we want to scale the training data and save it in a new variable called X_train_scaled. And the test data, saving that into a new variable called X_test_scaled. Then, we just use these scaled versions of the feature data instead of the original feature data.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
clf = SVC().fit(X_test_scaled, y_train)
r2_score = clf.score(X_test_scaled, y_test)
There are two very important things here. First, that same scalar object has to be applied to both the training and the testing. And second, that scalar object has to be trained on the training data and not on the test data.
Important aspects need to be followed while preprocessing data in ML algorithms:
- Fit the scaler using the training set, then apply the same scaler to transform the test set.
- Do not scale the training and test sets using different scalers: this could lead to random skew in data.
- Do not fit the scaler using any part of the test data: referencing the test data can lead to a form of data leakage.
The Effect of Preprocessing on Supervised Learning
The following example demonstrates the importance of data preprocessing in the real-world example cancer dataset. Fitting SVC on the original data:
# import SVC classifier
from sklearn.svm import SVC
# split data
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, random_state=0)
# initialize classifier and fit data
svm = SVC(C= 100)
svm.fit(X_train, y_train)
# checking accuracy for classifier
print("Test set accuracy: {:.2f}".format(svm.score(X_test, y_test)))
>>>>> Test set accuracy: 0.63
The following code represents scaling data with MinMaxScaler before fitting the SVC classifier :
# preprocessing using 0-1 scaling
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
# learning an SVM on the scaled training data
svm.fit(X_train_scaled, y_train)
# checking accuracy for classifier
print("Test set accuracy: {:.2f}".format(svm.score(X_test_scaled, y_test)))
>>>>> Test set accuracy: 0.97
As we can tell based on accuracy results, the effect of scaling data is quite significant.
Conclusion
Data Transformation is very important for many Machine Learning Methods. The type of features normalization that’s best to apply can depend on the data set, learning task, and learning algorithm to be used. There is no hard and fast rule to tell when to normalize or standardize data. It is good to start by fitting the model to raw data, normalized and standardized data, and compare the performance for the best results.
Importance of Data Preprocessing and Scaling in Machine Learning was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Ivan Zakharchuk
Ivan Zakharchuk | Sciencx (2021-02-25T01:19:39+00:00) Importance of Data Preprocessing and Scaling in Machine Learning. Retrieved from https://www.scien.cx/2021/02/25/importance-of-data-preprocessing-and-scaling-in-machine-learning/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.