
This content originally appeared on Level Up Coding - Medium and was authored by Patrick Bovard

Back in Fall 2020, I watched, like many Americans, as the Presidential debate between then-President Donald Trump and current president Joe Biden in a mixed state of disbelief and shock, as the debate devolved into back and forth quips.
For some reason, I tended to remember the debates pre-2015ish as a much more civilized discussion between two candidates, where they had more time to hash out the issues amongst themselves. More policy, more ideas, less back and forth quips and barbs.
But was that true? Or was it just me remembering those debates with rose colored glasses?
In order to better understand how presidential debates have changed over time, I decided to use my Natural Language Processing project during Metis’ 12 week immersive Data Science bootcamp as an opportunity to explore and learn more about the Presidential debates. Here, I’ll run through the steps of my project, and leave you with some of the main findings I came away with.
Data Collection
When I began collecting data for this project, I wanted to find transcripts that I could format into tabular form that I needed to complete the machine learning tasks necessary for this project. Luckily for me, the Commission on Presidential Debates and The American Presidency Project at UC Santa Barbara have an incredible collection of debate transcripts, going all the way back to the first presidential debates, between Kennedy and Nixon in 1960.
With the transcripts available, I utilized the web-scraping tool BeautifulSoup to collect the transcript data from each debate, organizing it into a Pandas dataframe utilizing Python. Each row of data represented one paragraph from the debate transcripts, roughly representing one speaking line.
Once the data was collected, I added a few pieces of information to each row, so I could properly analyze and organize it down the road. Each row was tagged with the following:
- Debate Name, Date, and Year
- Debate Type (General Election Presidential, General Election Vice Presidential, Republican Primary, or Democrat Primary)
- Speaker Name, Party and Election Result (i.e. did they win or lose the election the debate was for)
- Speaker Type (Republican, Democrat, Moderator/Other, and in the case of Ross Perot, Independent)
This took some time, but taking the time up front to properly organize and tag text data up front leads to a better ability to analyze it later, so certainly a time cost worth paying.
The end result was about 75,000 debate lines, organized, tagged, and ready to proceed.
Exploratory Data Analysis
Once my text was cleaned, formatted, and properly tagged, I got going on some exploratory data analysis before diving into topic modeling and further NLP tasks.
Right out of the gate, I noticed a major shift in the debate structure, with the help of a simple line chart — the average response length had decreased by almost six times from 1960 to 2020!
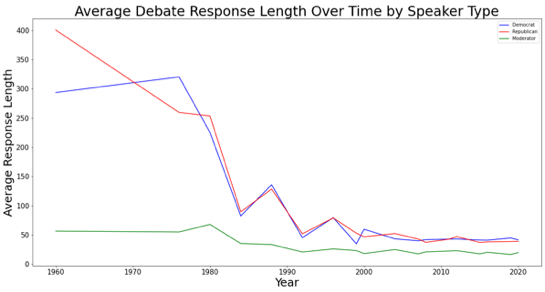
On one hand, it wasn’t too surprising to see this — it was abundantly clear debates have become more about theater than long-form policy discussion. It was fulfilling to see a visualization that held up a hypothesis of mine early on in the analysis of this data.
Text Pre-Processing
Like with any algorithm, the modeling result will only be as good as the data you feed it. And while the organization above certainly helped, Natural Language Processing requires a little extra up front work, in the form of text pre-processing.
Utilizing the NLTK toolkit, I went through a few distinct steps here:
Lowercase-ization, Number and Punctuation Removal
This is pretty straightforward — since the goal of Natural Language processing is to evaluate text, this step just involved removing numbers and punctuation, and then making everything lowercase. Next.
Stopword Removal
If you’re not familiar with the term “stopwords”, they are basically common words that don’t add any special semantic value to a set of text data. In English, think words like “I”, “me”, “it”, “what”, and so on. Most every document will have plenty of these words, so they don’t contribute much in the way of topics.
With my project, I did need to remove additional stopwords from my text. These were words that were very specific to debates, that wouldn’t necessarily add to any specific topics. These were words like “president”, “senator”, and “governor” that would be from one candidate or a moderator addressing each other. Additionally, I added the names of each speaker in the data set, so those would not be confused with topics.
The end result was a set of words in each row of data that would lead to much cleaner, distinct analysis of the topics being discussed.
Lemmatization
Lemmatization is a bit of a more complex term, that isn’t always necessary in projects like these. Simply put, lemmatization is grouping words together by cutting them down to morphological bases. Words like “walking” will be changed to “walk”, and “better” goes to “good”. Basically, the lemmatization process will try to provide context for where the word is used, and cut it down accordingly.
I found this helped the analysis of my project down the road when it came time for topic modeling, so I rolled with it.
TF-IDF Vectorization
The last major step of my preprocessing was to use term frequency-inverse document frequency (TF-IDF) vectorization to separate the words. Because a computer program can’t properly understand words, the text needs to be converted to numbers.
One simple way is to simply count how many times each word appears within the line (“count vectorization”), so you end up with a count value for each word. I did originally try that, but it led to topic modeling reducing to many similar topics that didn’t quite differentiate from each other, and didn’t really allow me to analyze debates.
I then tried utilizing TF-IDF vectorization, which worked much better in this application. Unlike raw counts, TF-IDF is able to contextualize the word counts. Utilizing the frequency of the word within the document (in my case, speaking line) and the inverse frequency of how frequently a word appears across all of the text data (i.e., is the word rare or not?), I was able to develop more specialized, distinct topics that aided my analysis.
With some more specialized words and topics here that related to politics and policy, this approach gave me the best results, different topics that were more easily interpretable.
Topic Modeling
With the data collection, organization, and modeling prep done, I moved onward into topic modeling. In order to better understand the content within debates, I used non-negative matrix factorization (NMF) to conduct topic modeling on my corpus. From this exercise (and with plenty of trial and error), eight major topics emerged.
Here is a quick rundown on those, with the major words associated with each topic:
- General Campaign Issues: people, know, one, right, time, thing, issue
- Taxes: tax, cut, percent, income, pay, plan, rate, middle, code, increase
- Healthcare: health, care, insurance, plan, cost, medicare, company, system, universal
- Education: school, child, education, need, teacher, kid, parent, college, public
- Social Security & Similar Domestic Programs: security, social, medicare, money, program, benefit, cut, budget, national, senior, retirement
- Foreign Policy / War: state, united, war, world, need, iraq, military, nuclear, iran, weapon, policy, troop
- Domestic Economy: job, economy, business, million, work, create, new, energy, small, trade, people, manufacturing
- Generic “Debate Speak”: going, make, go, know, back, change, able, pay, take
After reading that list of topics of presidential debate topics, you may be thinking “of course!”. After all, these are all things that we’d expect to see in a debate between presidential candidates in the United States.
With that in mind, the topics because extremely interesting to monitor over time. While there were some ebbs and flows in the topics over time, nothing changed more drastically than Foreign Policy’s place in debates.
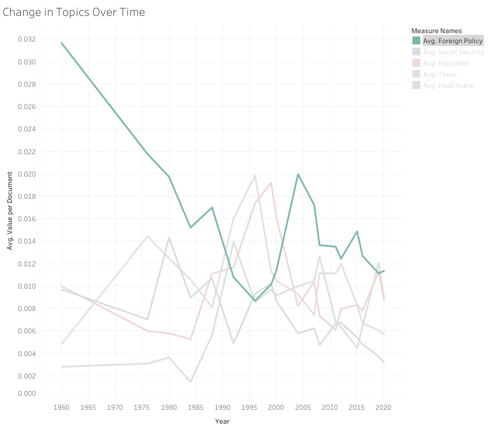
Back in 1960, at the peak of the Cold War, none of the other topics were talked about nearly as much.
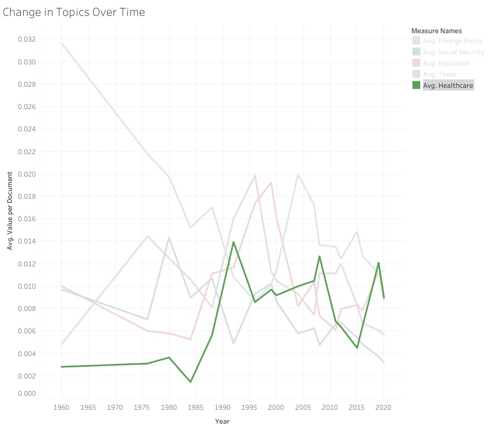
On a similar note, the focus on Healthcare has increased more than anything else over the years, going from being an afterthought in 1960 to being a core topic in several election cycles from 1992 onward.
Finally, and perhaps to no one’s surprise, the rise of the generic “Debate Speak” topic has also risen steadily from 1980 to today.
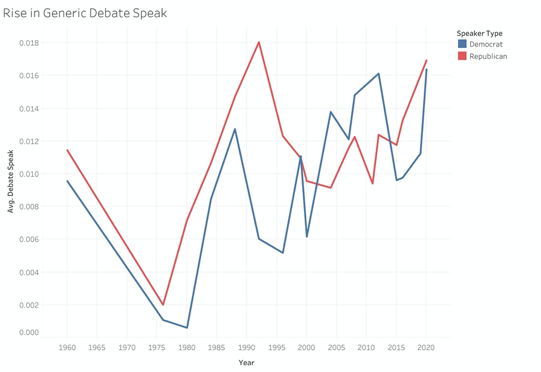
The way I interpret this observation, is that debates have been shifting steadily away from those rigid, long-form policy discussion towards a more back and forth on more vague ideals or aspects of a candidacy. Thinking about how recent debates have gone, especially in 2020, this seems to reflect what I remember watching.
Primary Specific Topic Modeling
After examining the entirety of debate transcripts, I thought it would be a worthwhile exercise to similarly explore debates from Republican and Democratic Primary debates. With the primaries offering a different type of arena, where each party has to win over their own base and not the middle of the road undecided voters, it would stand to reason that each party would have slightly different takes on the major topics.
After similar topic modeling via NMF, this hypothesis stood up. Of the eight topics that emerged individually for the party primary debates, both parties shared Foreign Policy, Taxes, Healthcare, Education, and Domestic Economy. As these are major issues that face the country as a whole, this makes sense.
The interesting part of this was the key words each party used when discussing these topics. For example, for Taxes, the second most common word used by Republicans was “cut”, while for Democrats it was “pay”. Likewise, in the Healthcare
A subtle difference, but certainly one that makes sense.
In an interesting twist, a few unique topics also emerged among the two parties. For Republicans, this included a topic focused on immigration and border security, as well as a topic that merged Education and Religion:
- Immigration: need, border, law, system, military, immigration, secure
- Education/Religion: life, school, child, right, pro, believe, god
While both sides had an education topic, it was certainly interesting to see how this blended with religious and socially conservative topics within the Republican primaries.
On the Democratic side, more unique topics were a secondary healthcare topic more focused on Big Pharma, as well as a more vague topic that was centered around Progressive Change/Ideas:
- Big Pharma: company, insurance, drug, prescription, cost, profit, big, industry, lobbyist, pharmaceutical
- Progressive Change/Ideas: going, know, make, change, together, people, forward, bring, talk
While these topics were interesting to see, from my own memory of watching debates they all made sense. From there, something I wanted to consider is what type of topic focus makes a successful Republican candidate, and what type of focus makes a successful Democratic candidate. Luckily, these topics and their focus within debates gave a way to compare this over time.
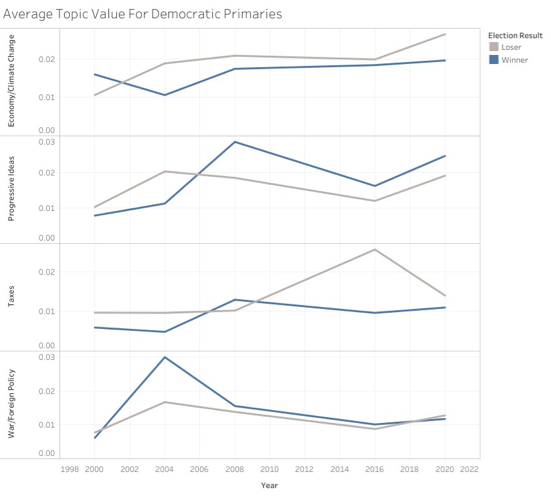
For Democrats, I noticed a distinct shift from 2008 onward, which coincided with Barack Obama’s nomination for the presidency. While Al Gore in 2000 and John Kerry in 2004 tended to focus as much or more on foreign policy than their opponents, they did shy away from that Progressive Ideals category.
In 2008, future President Obama really flipped a switch with his focus on that topic, focusing much more on this category than his opponents, and less on the topic more based around the economy. This trend has continued since, with Hillary Clinton and Joe Biden showing similar patterns, relative to their opponents.
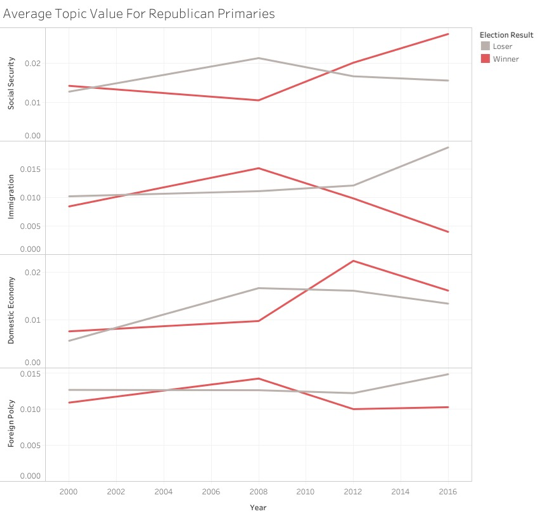
On the Republican side, there was also a distinct shift after 2008, when John McCain lost in the general election to President Obama. After that primary cycle, the next two winners, Mitt Romney in 2012 and Donald Trump in 2016, shifted from the GOP’s previous nominees and began focusing more and more on core domestic issues — domestic benefit programs like Social Security, and the Domestic Economy in general (jobs, manufacturing, etc.).
While several of the core topics have stayed the same over time, the changes are truly what makes the evolution of debates interesting. By understanding these topics via Natural Language Processing, you can quickly understand what issues were important to the voters during that election cycle. By extension, you can determine which candidates may have better captured that importance, based on how they focused their time during debates.
Thanks for reading along, and I hope you were able to find something insightful to take away from this. If you’d like to check out my code on this project or learn more about it, you can find it in my GitHub repo here!
Using Natural Language Processing to Understand Presidential Debates was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Patrick Bovard
Patrick Bovard | Sciencx (2021-03-30T00:33:59+00:00) Using Natural Language Processing to Understand Presidential Debates. Retrieved from https://www.scien.cx/2021/03/30/using-natural-language-processing-to-understand-presidential-debates/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.