
This content originally appeared on DEV Community and was authored by Halcolo
Xpath use path syntax to search parts of a XML document but as well allows you to find data identifying matches in an HTML file, if I compares with something similar are regular expressions but in trees later you will understand, in this case we will learn how to search data in a Webpage or scrap any web page with this syntax from scratch.
Before starts, is important you learn something about web scraping, you can't scrap all web pages because all web pages have a rules (Legal reules for bots), almost all web pages need be scraped, as you imagine Google is a king of scraping, web scrapin is only one of the tools they use in their big algorithm.
Now ¿How can I recognice which rules have a webpages?
All web pages need to have a robots.txt file in their root directory, if you don't believe me try search after any URL the robots.txt, some examples:
- https://www.google.com/robots.txt
- https://unsplash.com/robots.txt
- https://stackoverflow.com/robots.txt
- https://www.facebook.com/robots.txt
Basically the robots.txt provides some rules to any bot which parts of your page are accesible and which will be disabled.
If you want learn more about how can you create a robots.txt you can see it in this Google tutorial.
NOTE
This tutorial search teach you or gives you a simple guide of basic web scraping with a global syntax no matter if you codes in python, javascript or any programing language.
Now, let's start!
In your browser is possible use Xpath inside the console using this expression.
$x('')
This expression allows you to start Xpath and start a HTML tree search, in this case we will be do inside the Web page.
It is possible to see the tree structure of this page by viewing its HTML source code in the F12 browser console.
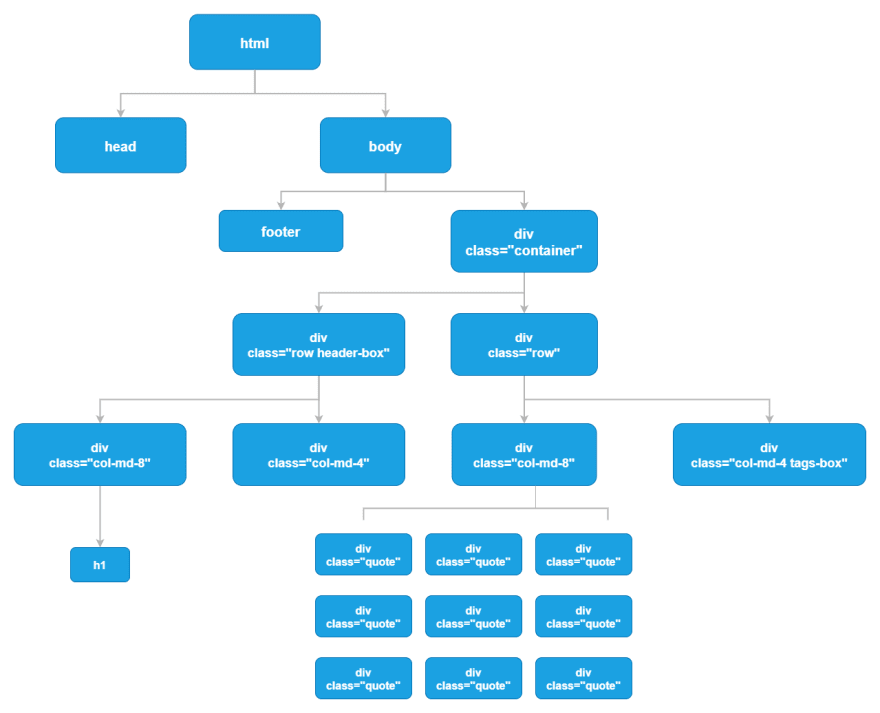
With the following it will return the information of the div with class = "container"
Now try
$x('/html/body/div')
Calling the tree in this way will be limited to bringing the information it finds and if we want to reach the branch that is class =" quote " we could arrive in this way.
$x('/html/body/div/div/div/div')
However, it will be unreliable and on many occasions it is very difficult to reach some of the children of the trees.
It is for this reason that we will begin to create filters to make sure what we are looking for what we want, we will start filtering by classes.
It is possible to filter the classes of each of the HTML tags that exist in the web page.
$ x ('//div[class = "container"]')
If you compare the expression with the previous ones you will notice that it has many changes, initially // that allows us skip all elements to be able to reach a specific tag in HTML in this case a div later with the squares brackets [] we can select a property of the tag either a class, an id, a src or any other by referencing it with an @ e.g. [@class], [@href], [@id]
$ x ('//div[@class="quote"]')
In the previous script we can identify that we arrive in a few words at the div tags with class quote, now we reduce it to a few words but we can be even more specific.
$ x ('//div[@class="quote"]/..')
The previous expression allows to bring the parent of a tag.
$ x ('/html/body/div/self::div')
$ x ('/html/body/div/.')
These two expressions allow to bring the current node, the . is only syntactic sugar or a way to simplify the self::<tag> this expresion refers to the axes later i will talk about it
Wildcards
There are some wildcards that we can use to indicate that we want any object in which we know its position but we do not know.
$x('/*')
With an asterisk (*) we can bring nodes of which we know their name but their position, in this case we will bring the HTML tag but without their nodes.
$x('//*')
Using the double slash as in the previous example, we are going to tell Xpath that we want all the nodes and it will bring us an array with the requested nodes.
$x('//span[@class="text"]/@*')
In this example it is possible to see something new at the end of the line, the first thing is that it is possible to call attributes outside the '[]' and with * you can bring all the attributes that have the text class spans.
Other examples can be
$x('/html/body//div/@*')
Let us now compare the following expressions.
$x('//span[@class="text"and@itemprop="text"] / node ()')
$x('//span[@class="text" and @itemprop="text"]/*')
The * is not going to help us if the node we are consulting does not have child nodes, however the expression node () identifies not only the child nodes that the queried node has but also everything that is not nodes.
$x('//small[@class="author" and starts-with(., "A")] / text()').map(x => x.wholeText)
$x('//small[@class="author" and contains(., "Ro")]/text ()').map(x => x.wholeText)
# The ends-with and matches expression only works with Xpath versions 2.0 of XPATH,
# current browsers only support up to version 1.1
$x('//small[@class="author" and ends-with(., "t")]/text ()').map(x => x.wholeText)
$x('//small[@class="author" and matches(., "A.*n")] / text ()'). map (x => x.wholeText)
AXES
The axes allow the nodes to be obtained in all directions, from the child that has this node, the ansesters that follow, even bringing both the ansesters as the node itself and the parents.
$x('/html/body/div/self::div')
$x('/html/body/div/child::div')
$x('/html/body/div/descendant::div')
$x('/html/body/div/descendant-or-self::div')
Challenge
From the WebPage http://books.toscrape.com/ obtain the titles and preciousness of each book, and within one of the books obtain the categories and their descriptions and if it is in stock, in the next chapter we will obtain the information with a script of all these books with Python.
Other links.
This content originally appeared on DEV Community and was authored by Halcolo
Halcolo | Sciencx (2021-04-07T01:49:02+00:00) XPATH for Scraping. Retrieved from https://www.scien.cx/2021/04/07/xpath-for-scraping/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.