
This content originally appeared on DEV Community and was authored by Jewel Muraledharan
When it comes to data processing, Pandas is one of the most handy and sophisticated libraries in Python. It has functions which can read and write structured data efficiently from and to a wide variety of data sources (csv, databases, flat files, etc).
But when the data in the source grows, it can throw a memory error. Pandas has a nice way of dealing with this by reading the data in chunks and returning a TextFileReader object which can be iterated to access data. This data can then be read chunk by chunk and processed.
Let's take an example of data load from csv to MySQL. In this example we will be loading a csv five with 500,000 rows and 3 columns to a MySQL table
We will use pandas module to read data from csv and sqlalchemy module in python to insert data to the MySQL.
Firstly, let's load the data to Pandas DataFrame as chunks

Processing data in chunk is still linear which means each data chunk will be processed or loaded one after the other.
1. Linear data upload
Let's look at the linear way to insert data.
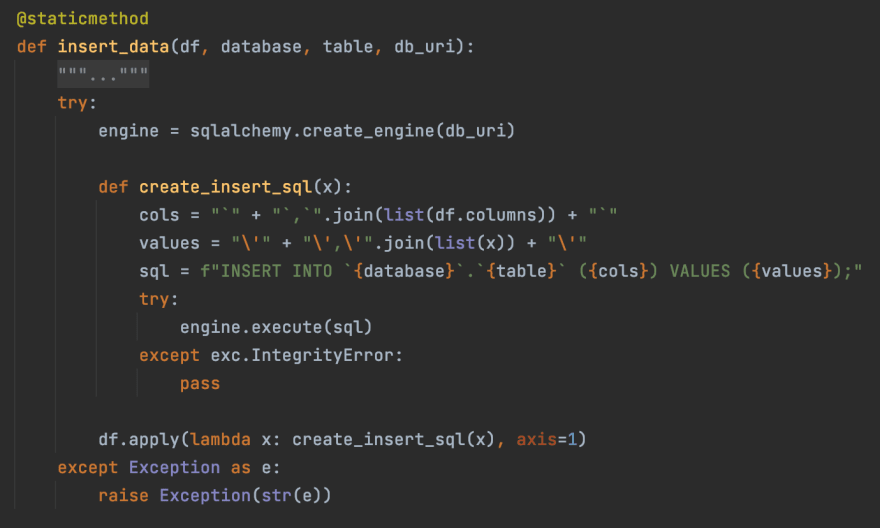
- Create an sqlalchemy engine using the database uri
- Create an insert query for each row in the csv file
- Use the sqlalchemy engine to load the data to MySQL table.
So how do we speed things up?
Multiprocessing is one way.
2. Parallel load of data using multiprocessing
Python's multiprocessing module is one of the easiest way to spin up multiple processes for parallel computing.
We will be using apply_async from multiprocessing module.
The apply_async function is a variant of apply() which applies the provided function over data but does not wait for the function run to be completed. In this way the code does not have to wait for a particular chunk of data to be processed before starting to process the next.
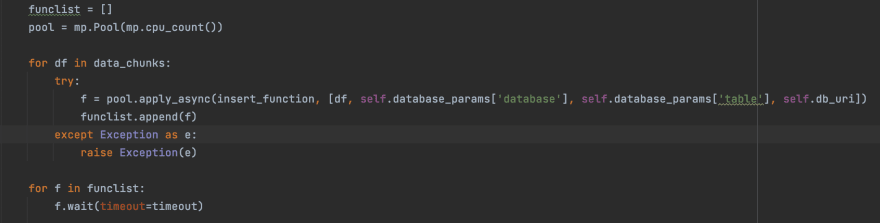
Steps
- Create a pool of workers. The workers will work on each of the data chunk load.
- For each of the data chunks, apply the insert function using the parameters
- The wait method will wait for the insert function to finish till the timeout is reached
With 4 cores and for a csv file with 50,000 rows and 3 columns, the code using multiprocessing was able to load the data in 45 seconds while the linear code was almost 10x slower
 jewelkm
/
large-data-processor
jewelkm
/
large-data-processor
A Python code for parallel insert of csv data to transactional database table.
This content originally appeared on DEV Community and was authored by Jewel Muraledharan
Jewel Muraledharan | Sciencx (2021-04-14T10:33:35+00:00) How to speed up csv data load to database using Multiprocessing. Retrieved from https://www.scien.cx/2021/04/14/how-to-speed-up-csv-data-load-to-database-using-multiprocessing/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.