
This content originally appeared on Level Up Coding - Medium and was authored by Shikhar Vaish
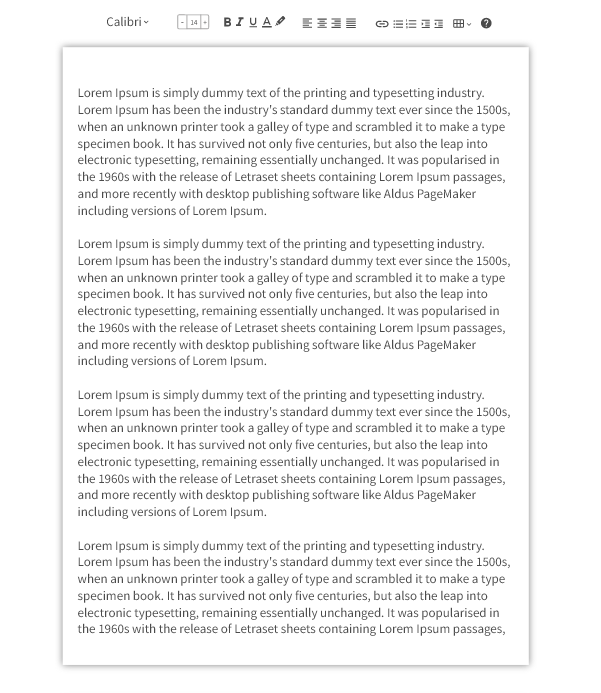
Index
I’m usually mad about the design of everyday things. Ever noticed the caret in MS Word in the recent builds? It animates while typing... I just feel it's amazingly relaxing to the eyes. This is the reason I started building text editors :P. I wanted to build something so soothing to the eyes. My first project in my freshmen year at college was to build an IDE just to remove the dozen extra tools from my view. It taught me innumerable skills in UI animation and development. More importantly, it's the art of breaking down a task objectively to kill the overwhelming feeling of the complex task. Following up in the next 2 years, I built the worst text editor in the world. It was a widget supposed to be used in web pages but couldn’t handle 1000 lines of code. I got the animated caret though!
Well, now what?
I want to optimize the last editor.
This is going to be my third project on editors. Here, I’ll be building an efficient Rich Text Editor that could be used for real-time collaboration later. Through this series, I’ll present the current progress and show the major sub-problems that I encounter while building it.
In this first post, I’ll develop the document’s core data structure and quickly implement some UI to verify my doubts and get an idea of the overall complexity of the project.
To ease the complexity, I’ve chosen to build the editor on top of an HTML web interface. This simplifies the tasks of implementing MouseEvent, KeyboardEvents on the low-level as well as provide a bunch of text-formatting events like underline, bullets and we can focus on how these events are handled on the upper level. I’ll be using Electron that will be running my favorite web framework, Angular. Yes, it's not React, I hate y’all, kbye.
Document Core
I’ll present an overview and a possible solution that comes to mind in the first attempt. I’m going to list a few sub-problems and use-cases and develop the core data structure on the go.
Basic Paginated Document Editor
Starting with the most obvious things, there will be characters. Characters will be wrapped with tags for proper formatting in HTML. Our data presented visually is through HTML. And, characters are contained inside multiple pages in a document. Documents are scrolled through pages.
Starting with basic text input, this can be easily implemented using a contenteditable div. Something like:
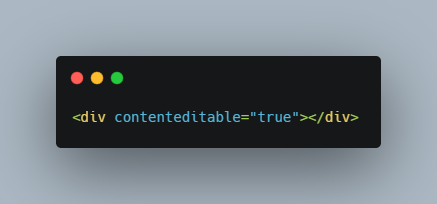
This will also open up basic text-formatting tools that we’ll consider later. Next up, we need pages. This can be done by visually having multiple divs where each div looks like a page.

Considering this, we have the data structure on left.
On the back, is it really an efficient way to store the document?
Let’s understand the basic usage of string in the editor. Our main editing tools are characters, backspace key, delete key, and mouse selection to replace substrings.
We simply want to insert or delete characters at a specific index. Strings need to be split at the index and form new strings as needed to insert the character. This takes O(n). Most of all the operations require this and we rarely need to get the character at index when we talk about higher-level implementation. Rope data structure seems to be the best fit for storing large strings in the document as it handles split in O(log n). However, let us understand our other problems before deciding on this.
Easily Navigate to Specific Locations
This means I should be able to use keyboard arrow keys and mouse clicks intuitively to jump to a location and start editing the text. In a single div, it's fairly easy. It gets a little tricky when multiple pages are added. When you are at end of the div, caret should move to the start of the next page. This can be done easily using Range API. Here is an implementation based on a StackOverflow answer:
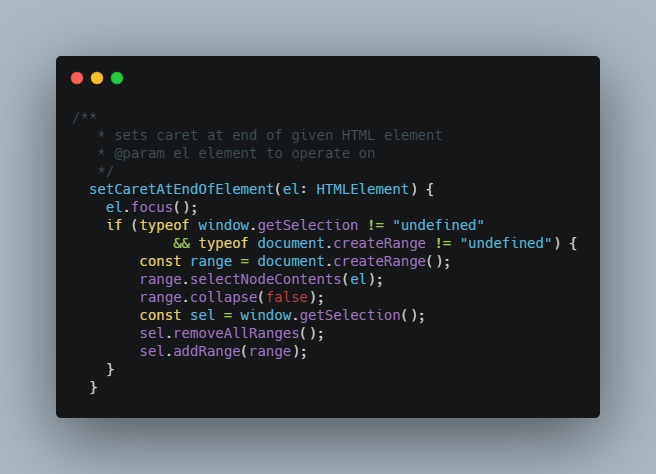
However, there is a problem. It's not easy to jump to a specific index in the div. There are cases when there are a series of line breaks in a document. This is where it gets difficult to find an index of character where the caret is. There have been workarounds that failed in certain test cases and I could not solve it eventually unless I got control on the low level. Keeping in mind that precise location is absolutely necessary for collaboration later, I introduced blocks.
A note on collaboration
Real-time collaboration is extremely complex. Imagine this scenario. Your friend is typing above somewhere while you’re typing. This means when you type at index 5, your friend has inserted few characters above. Technically, you’re typing at index 7. Handling these offsets results in complex edge cases that are currently handled by two famous solutions: CRDT and Optimization Transforms. Imagine the complexity when the deletion is considered, copy, paste, and more of your friends join in.
Apparently, Google Docs starts to break and its delays start showing up visibly when more than 10 real-time users start editing. This IEEE paper on Google Docs reported that 50 users(the upper limit of Google Docs on real-time collaborators) can edit on Docs only when they have a speed of 1 character per second. That’s rarely the case in the real world.
Coming back to the block idea… This is an idea one of my friends, Ritvij, had given me earlier to avoid using any index calculation in the first place. Considering each block as an independent input field inside a page, users can type on individual blocks without causing trouble to others blocks as the data has been “unlinked”. The collaboration algorithms should be used when users are typing in the same block. This could save tons of processing and server delays.

Considering the above scenarios, I decided that each line would be a block.
So, our current model of a document looks is on the left.
I can easily jump to a specific location using page index, block index, and string index. This is more like a dynamic Mo’s algorithm that is used for bulk update operations on arrays. And querying an array is blazingly fast.
Page Formatting
There is a set of attributes for every page usually margins, background color, page dimensions. We’ll add a config attribute on the page.
So, this is the final document core:

Coming back to our earlier discussion on Rope Data Structure. It is definitely the best choice if we were handling long strings. Considering the current document structure, each block is simply a single line in the document. By the term line, I do not point to a line in English Literature that ends on a period. Here, I’m talking about a single line that appears visually, i.e., as soon as a character comes below another character, it will be treated as part of a block that is not the same as the above ones.
To get an estimate of how many characters am I dealing with inside a single block, I set the page size to A4 size dimensions, added padding of 15pt, filled a block, and added some formatting abruptly that I don’t usually use so frequently:
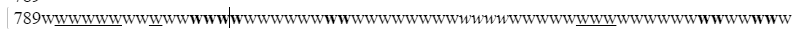
This contains 422 characters and I get this data from innerHTML attribute from the block element. Seeing this, I estimated I will be handling around 500–600 characters per block in worst-case scenarios. This can be handled by strings efficiently with relatively less overhead.
Now, the Rope data structure is meant for handling long strings. In cases of short strings, the extra memory and query delays result in an overhead and perform worse than a normal string. Since I’m able to navigate to manipulate a line quickly using page index to jump to a specific set of blocks and using block index to trim my view to 50–500 characters on every keypress, I’ve chosen not to use Rope for now.
Component Layout
For the simple text editor, we’re going to have a list of scrollable pages and a fixed header for formatting tools.
I’ve added few formatting tools. I went through theexecCommandmethod in Javascript and tested all formatting tools, they worked smoothly with no effort. However, I’ve currently removed bullet points and insert-table operations as I’m uncertain how to implement them with our new Block-Based structure.
I’m open to any suggestions, be it UI or logic :)
Tomorrow, I’ll work on some more sub-problems like scrolling mechanisms, event-handling, structuring Document Component in Code before implementing the Core. I built a prototype here just to test some of my ideas and visualize the project.
Byee.
Next Article
Building a Rich Text Editor Day 0: Designing Document Core was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Shikhar Vaish
Shikhar Vaish | Sciencx (2021-04-20T15:46:12+00:00) Building a Rich Text Editor Day 0: Designing Document Core. Retrieved from https://www.scien.cx/2021/04/20/building-a-rich-text-editor-day-0-designing-document-core/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.