
This content originally appeared on Bits and Pieces - Medium and was authored by Fernando Doglio
Saying you’re using REST is not good enough anymore
After working for a while with Node.js I’ve come to the conclusion that there is no better tool to use when writing microservices. Of course, that is my opinion, completely biased by my preference for JavaScript as a language. But hey, even without me pushing my own opinion into your eyes, I bet you can’t say Node.js isn’t a great tool for building microservices.
It provides very fast development times, lots of pre-existing frameworks and the async I/O allows for fantastic performance when dealing with a multitude of simultaneous requests.
And while Node.js by itself is a great tool, it’s going to come down to however you end up using it. With that in mind, here are some useful and interesting design patterns for your microservices. The idea is that you stop creating a single service for all your projects, there are many ways of splitting them up depending on the type of benefit you’re after. So let’s take a quick look at them.
Aggregator pattern
The main idea behind this pattern is to create a service, based on other, minor and individual services. An aggregator service would be the one that provides the common public API which is consumed by the clients.
It would only have the required logic needed to use all other services, which in turn, would be the ones with the highest business logic load.
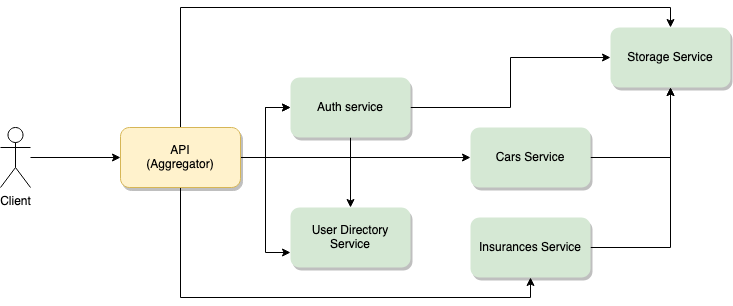
Take a look a the above image. It tries to depict a theoretical can insurance microservice. The client only cares about the main API, for all intents and purposes that is the only microservice available and that is where all the client Apps will point to. However, behind the curtain you can see there are multiple, individual APIs working together orchestrated by the aggregator.
This approach provides several benefits:
- Growing the architecture is easier and more transparent to the end client. After all, API will never change and if it changes, there is only one URL to adjust. However, in the background you could be adding, removing or any combination of both as much as you want. In fact, if you don’t change the public-facing API, you can adjust the internal architecture as much as you want without affecting your clients.
- Security tends to be simpler. The main focus of all your API-based security efforts should be the public-facing API. The rest of them could be behind a VPN only accessible by the aggregator. This makes inter-API communication a lot simpler.
- You can scale these microservices individually. By measuring resource utilization you can detect which ones are the most affected by the current workload and create more copies of it. Then place them all behind a load balancer and make sure everyone interacting with that service hits the load balancer. As long as you keep your services stateless (such as you would if you were using REST for instance), the communication mechanics would not be affected.
Small microservices like this can be built around Restify for instance, which provides everything you need to create a REST microservice. It works great and its API is very similar to that of Express, also a very well-known and easy-to-use framework that can be used to create these services.
Chain of responsibility
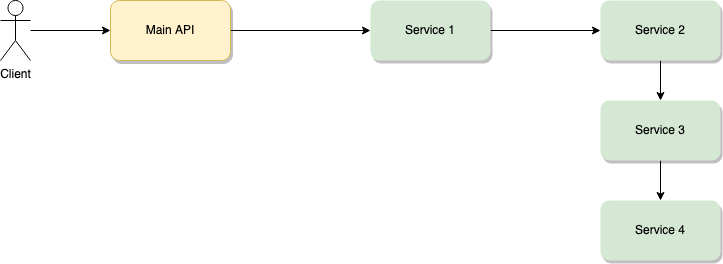
This approach is very similar to the previous one. You’re essentially hiding the complex microservice-based architecture behind a single service that takes care of centralizing the orchestration logic.
The main difference here, is that your business logic — for some divine reason — requires you to serially link multiple services together. This means that for the Client-Main API interaction to be done, the request has to go from Main API to Service 1, then from Service 1 to Service 2, from Service 2 to Service 3, it then has to start over from Service 3 to Service 4 only for Service 4 to provide the actual response, which in turn will travel back service by service all the way to the main API.
It’s long to explain, but it’s WAY longer to execute. This type of interaction is not recommended unless you change the communication channel for a more agile one. You could be using REST over HTTP for the Client-Main API interaction and then switch to sockets for inter-service communication. That way the added delay from HTTP would not add up on every request. Sockets will already have the communication channels open and active between the internal microservices.
This approach provides similar advantages to the previous one, however, it has one huge flaw, the longer you make the chain, the more delay it’ll add to the response. This is why making sure you use the right communication protocol is crucial to the success of this pattern.
Take a look at Socket.io if you’re wondering how to handle inter-microservice comms through sockets. That is the de-facto library for handling sockets in Node.js.
Asynchronous messaging
An interesting way of improving upon the mechanics of the chain of responsibility pattern is to make it all asynchronous.
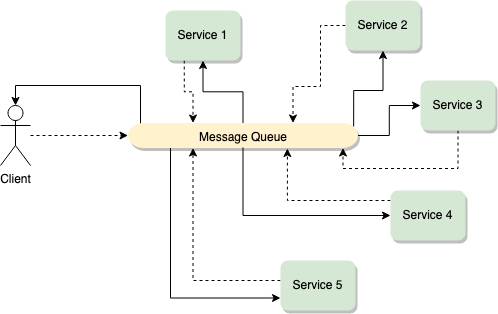
I personally love this pattern. Getting a microservice-based architecture to work around asynchronous events can give you a lot of flexibility and performance improvements.
It’s not easy, since the communication can get a little bit tricky and debugging problems around it even more so. Since now there is no clear data flow from Service 1 to Service 2.
A great solution for that is to have an event ID created when the client sends its initial request, and then propagated to every event that stems from it. That way you can filter around the logs using that ID and understand every message generated from the original request.
Also, note that my diagram above shows the client directly interacting with the message queue. This can be a great solution if you provide a simple interface or if your client is internal and managed by your dev team. However, if this is a public client that anybody can code, you might want to provide them with an SDK-like library they can use to communicate with you. Abstracting and simplifying the communication will help you secure the workflow and provide a much better developer experience for whoever is trying to use them.
The alternative however, would be to provide a gateway-like service that interacts with the client. That way the client is only worried about the gateway and the rest is transparent to it. This however does not negate the requirement of the client to be aware of the asynchronous nature of the communication. You still need to provide a way to subscribe to the events and to send new ones into the queue. Mind you, it’ll be through the gateway, but it still needs to happen.
Main benefits of such an approach:
- Much faster response times. The communications are opened with an initial subscription to the events, and then every subsequent request is fire & forget. This means that it doesn’t have to wait for the entire business logic to end to close the connection and provide a response to its user. The data will come once it’s ready and that is how the user-facing UI needs to handle it.
- Information is harder to lose due to a stability problem. If one of the microservices fails for the other architectures, the currently active requests will fail and cause data loss. However, as long as the Message Queue stays up, this approach ensures that data is not only stored, but once the failing microservices are restored, the pending requests can be finished.
- Much easier to scale. Having multiple copies of the same microservice no longer requires a load balancer. Now every service becomes an individual consumer/producer and events are treated independently.
Good options for message queues that work great with Node.js are Redis and Kafka. The former having features such as Pub/Sub, Key-space notifications, and even Streams making it a great and efficient message queue. My suggestion would be:
- If you have huge traffic and expect to generate hundreds of thousands of events per minute, then Kafka might be a better option.
- Otherwise, go with Redis, it’s much faster to set up and maintain.
Of course, if you’re on a cloud-based ecosystem, then also make sure to check the cloud-native solutions such as AWS SQS which also work great and can scale automatically out of the box.
Circuit breaker
Have you ever had your service fail due to a very unstable 3rd party service you’re consuming?
What if you could somehow detect when that happens and then update your internal logic dynamically? That would be great, wouldn’t it?!
The Circuit Breaker pattern does exactly that, it provides a way for you to detect a failing dependency and stop the data flow from going there and causing delays and a terrible user experience.
Mind you, you can also use this pattern internally for your own services but if your services are failing, chances are you’re going to want to try to fix them. However, there is very little you can do with 3rd party services that are failing, isn’t there?
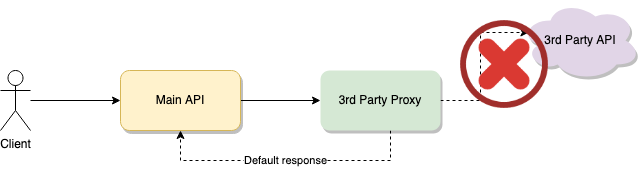
Essentially what you want here is to have a proxy service for your 3rd Party API. That way, the proxy can do two things:
- Redirect the communication from and to your services to the 3rd Party API.
- Track failing request. If the number goes past a threshold within a pre-defined window of time, then stop sending the requests for a while.
When the error state appears you’ll have to handle it however you need depending on your internal logic’s needs. I added a “default response” in my diagram, assuming you could provide some kind of default data that would allow the flow to continue, even with basic information. But you could also opt for disabling that feature for the time being, or defaulting to a secondary service that provides the same information.
The alternatives are as varied as the business logic associated with them, so you should decide for yourself what is the best course of action. This pattern only provides you with the ability to understand when it happens, what you do afterward is completely up to you.
A better internal architecture for your Microservices
While at a macro architecture level, the above patterns are great to create very extensible and highly efficient architectures, the internal structure of your microservices also needs to be taken into consideration.
This is why I also wanted to quickly cover the idea of common components for your microservices.
All the patterns listed here show you how to break the monolith pattern into multiple services. We all know the benefits: it simplifies the task of working with multiple teams, extending or updating a single service doesn’t have to affect the rest (like it would with a monolithic service), and scaling individual services is also faster and easier.
However, having many teams working in parallel in several microservices can be a real logistics challenge if you don’t take the required precautions. Essentially:
- Don’t repeat code, try to keep the coding efforts between different teams as homogeneous as possible. Don’t force them to re-invent the wheel when others already have it.
- Make sure all teams work in the same way. Keep the same standards across different teams to make sure sharing people between them is easier.
- Have an easy mechanism to use other’s code. In line with the first point, it should be very simple to use other team’s code simplifying the development efforts and reducing times.
- Make sure it’s easy to discover what others are working on. When several teams are working in parallel, sharing their work with each other to help re-use is not trivial. Sometimes teams end up re-implementing the same libraries simply because they don’t know what others are already doing.
If you don’t pay attention to these points, you’ll end up with increased development times due to re-implementing solutions multiple times (like logging libraries, common validations, etc), difficulty sharing knowledge between teams because they don’t follow the same standards, and increased onboarding times when moving people from team to team due to the same fact.
How can you plan for this?
My suggestion is to keep this in mind from day one, all your efforts should be towards providing your developers with the required tooling to enable this.
Bit: The platform for the modular web
Personally, I really like using Bit (Github) to centralize everything, it allows me to:
- Define a single working development environment to share between all teams.
- Share common modules either through standard installs, as well as full source code importing them. Both cases will give you access to the module like any npm-based installation would, but the second also gives you access to the source code in case you want to extend it and export it back to the central repository. This is a major win over other Node.js package managers, which only let you install modules.
- Discover what other teams are working on and if you can re-use their modules through a central marketplace which can be both public (if you’re hoping to open-source your company’s work) or private, giving you the exact same list of features.
- Compose and deploy microservices. When using Bit, you decide which independent components are shared and used across microservices, and which components are full microservices that are deployed independently.
Through Bit, you can abstract concepts such as “linter”, “package manager”, “bundler” and others and only focus on the actual workflow. Instead of checking whether you’re using npm or yarn or pnpm, just worry about using bit install . This bridges the gap between team members who know one tool or the other, and standardizes the way all teams work.
Granted, you can do the same through a set of well-defined standards and individual tools. That is entirely possible and I’ve seen it work myself. However, why would you go through the extra effort of writing and setting all those standards yourself if a single tool can do it for you?
What are your favorite microservices patterns? Did I cover them here?
And what about the internal architecture of your microservices? How do you handle the work of multiple teams to make sure they don’t create the same common libraries many times over?
Learn More
- Independent Components: The Web’s New Building Blocks
- Create Your Own Customized Bit Node Environment for a Standardized Node Modules Development
- Bit Harmony: A New Tool To Create and Collaborate on Independent Node.js Components
My Favorite Microservice Design Patterns for Node.js was originally published in Bits and Pieces on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Bits and Pieces - Medium and was authored by Fernando Doglio
Fernando Doglio | Sciencx (2021-04-26T20:04:18+00:00) My Favorite Microservice Design Patterns for Node.js. Retrieved from https://www.scien.cx/2021/04/26/my-favorite-microservice-design-patterns-for-node-js/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.