
This content originally appeared on DEV Community and was authored by Igor Lukanin
TL;DR: Cube.js is a popular open-source tool to build analytical APIs. With the release of Cube Store, a performant distributed data store written in Rust, Cube.js is ready to provide high concurrency and sub-second latency for any SQL-compliant database, data warehouse, or query engine (e.g., PostgreSQL, BigQuery, or AWS Athena).
You can use open-source Cube.js and Cube Store to build an analytical API that will respond to highly concurrent requests from your application with sub-second latency regardless of data volume or workload. Even if you have a billion-scale dataset and thousands of concurrent users, Cube.js and Cube Store will get you covered.
Cube Store, the custom pre-aggregation storage layer for Cube.js, is now generally available and strongly recommended for use in production. Let's explore the motivation and design decisions behind Cube Store and learn more about the benefits of using Cube Store for new and existing Cube.js users.
Why Cube Store?
Cube.js is an open-source analytical API platform that allows developers to build an analytical API and a semantic layer based on data schema over any SQL-compliant data store. In the simplest scenario, Cube.js uses in-memory cache and query queue to provide better performance than the data store is able to deliver. However, it's usually the least scalable and cost-effective solution, so it's not recommended for production.

In a real-world scenario, Cube.js speeds up analytical queries using pre-aggregations. These are the condensed representations of source data that are pre-computed, partitioned, stored, and refreshed in a way that allows for super-fast execution of select queries.
Historically, pre-aggregations were stored internally, alongside the source data in a database (e.g., PostgreSQL or MySQL), or externally, in a custom-provisioned instance of PostgreSQL or MySQL, as the only feasible option for read-only or cost-ineffective data sources (e.g., AWS Athena or BigQuery). Usually, they will be renewed asyncronously by a dedicated refresh worker instance. It's an acceptable solution, however, the pre-aggregation database becomes a bottleneck and limits the scalability of the analytical API.
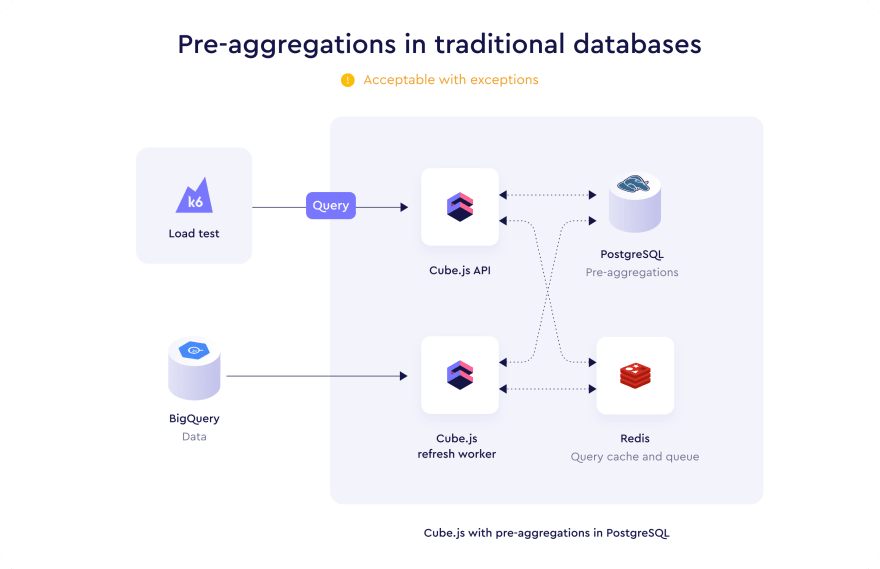
Pre-aggregations in traditional databases often won't allow for high concurrency and low latency of the analytical API. They also were the source of frustration due to poor performance in important use cases (e.g., with high cardinality of pre-aggregated data, with partitioned data, with joins across several databases), unsupported features (e.g., approximate distinct counts via HyperLogLog algorithm), or implementation details (e.g., support for long table names or support for various SQL types).
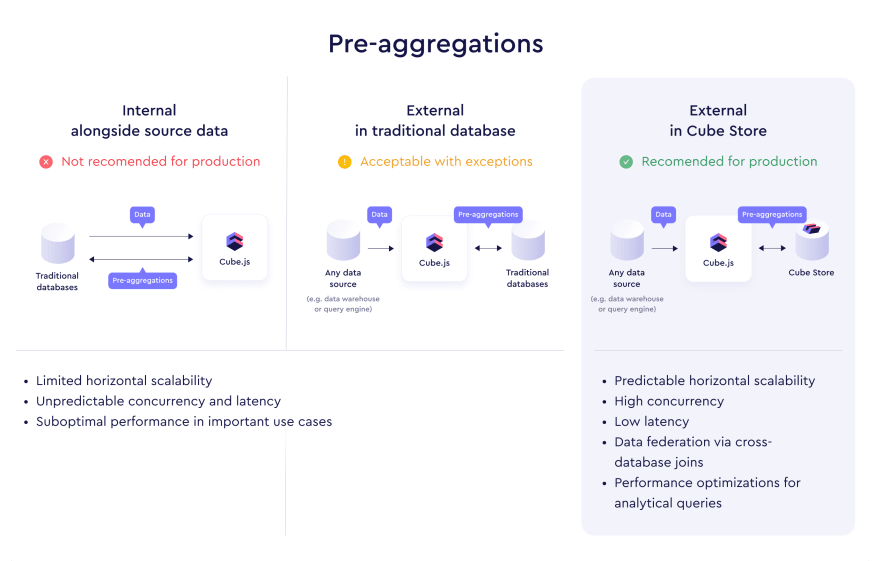
Cube Store is designed to resolve these issues and provide a performant pre-aggregation storage layer for Cube.js. It's a drop-in replacement for any currently used pre-aggregation storage and the go-to solution for new Cube.js apps. Being a distributed data store itself, Cube Store can be scaled horizontally with ease and predictability.

From now on, Cube Store is the recommended pre-aggregation storage layer for production use. It doesn't have the limitations of other databases used to store pre-aggregations. On top of that, Cube Store provides guaranteed high concurrency and sub-second latency, performance optimizations for analytical queries, and additional features such as data federation via cross-database joins. You'll get these advantages of Cube Store regardless of your data source and the data volume.
How Cube Store works
Cube Store uses a well-known and proven distributed query engine architecture. In every Cube Store cluster:
- a single router node handles incoming connections, manages database metadata, builds query plans, and orchestrates their execution
- multiple worker nodes ingest warmed up data and execute queries in parallel
- a local or cloud-based blob storage keeps pre-aggregated data in columnar format
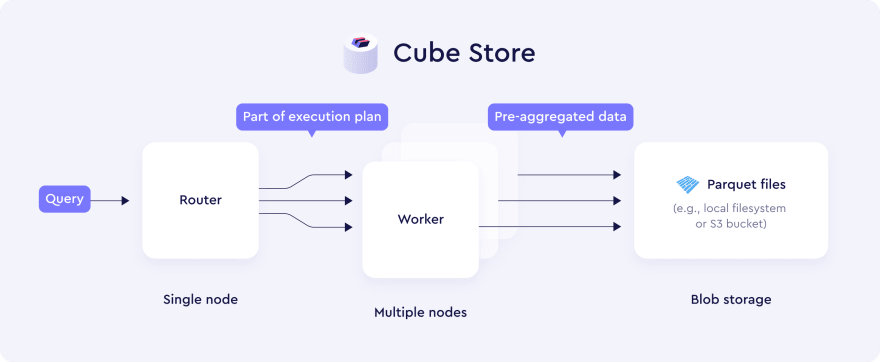
Cube Store was designed with performance in mind. It's written entirely in Rust to leverage low-level optimizations, effectively making Rust the top-1 language by lines of code in Cube.js codebase. Cube Store allows for almost unlimited horizontal scalability by increasing the number of worker nodes. It stores pre-aggregated data in Parquet format which was deliberately chosen for its efficiency and performance.
Cube Store is based on well-known open-source building blocks. Together with Parquet, Cube Store uses Apache Arrow for its efficient in-memory data structures and DataFusion as a query execution framework.
Cube Store has been used in Cube Cloud for more than 6 months. A few select early access users have been exposed to Cube Store in Cube Cloud and experienced substantial performance improvements thanks to Cube Store.
How to use Cube Store
Cube Store is ready to be used while developing new Cube.js applications and also as a drop-in replacement for the pre-aggregation storage layer in existing Cube.js apps.
Development. When Cube.js is run in development mode, a single-node in-process instance of Cube Store is enabled. It requires zero configuration and allows to instantly use the pre-aggregations. All you need is to mark them as external:
cube(`Cube`, {
sql: `select * from table`,
preAggregations: {
main: {
type: `rollup`,
external: true,
// ...
},
},
});
Cube.js will build pre-aggregations and store them in Cube Store. You can review the console output of Cube.js to see if queries are served using pre-aggregations. You can also see matched rollups on the Cache tab in Cube.js Developer Playground available at localhost:4000.
Production. A Cube Store cluster should be run in production and consist of a single router instance and several worker instances. There's an official cubejs/cubestore Docker image as well as a Docker Compose template you can use as a starting point.
Just like Cube.js, Cube Store can be configured via environment variables, e.g., Cube Store nodes assume the worker role when CUBESTORE_WORKER_PORT is set and ingest pre-aggregated data from the blob storage specified with CUBESTORE_GCS_BUCKET or CUBESTORE_S3_BUCKET.
Benchmarks. Depending on the currently used pre-aggregation storage and the data volume, after switching to Cube Store, you can expect your API performance to stay at least at the same level or increase substantially. You can review and use a benchmark template leveraging k6, an open-source load testing tool, to do your own measurements prior to switching to Cube Store.

Next steps
Here at the Cube.js team, we wholeheartedly encourage you to use Cube Store in development and consider migrating your production deployments to Cube Store as well.
Get started with Cube.js today. Review the release notes and documentation, share your experience in the #cube-store channel in Slack or post to Discourse, and don't hesitate to file Cube Store-related issues on GitHub.
Also, feel free to sign up for the waiting list of Cube Cloud which provides a fully managed Cube Store cluster for all deployments. Cube Cloud is currently in early access but will be generally available later this year.
This content originally appeared on DEV Community and was authored by Igor Lukanin
Igor Lukanin | Sciencx (2021-04-29T17:49:14+00:00) Introducing Cube Store: High concurrency and sub-second latency for any database. Retrieved from https://www.scien.cx/2021/04/29/introducing-cube-store-high-concurrency-and-sub-second-latency-for-any-database/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.