
This content originally appeared on Level Up Coding - Medium and was authored by Anello
An open-source framework for big-data processing and sophisticated analytics.

Humanity has never generated as much data as in the last 20 years. This vast data demands new technologies, new software, new tools, and new ways to process faster, from different sources, so much heterogeneous data. The concept of Big Data is the main reason for the emergence of applications such as Apache Hadoop and Apache Spark.
Big Data applications propose solutions capable of storing, processing, and analyzing large databases, processing heavy calculations, identifying behaviors in data, and providing specialized solutions that almost always run into the computational power of today’s machine in conventional architectures. All this for what?
Extract helpful knowledge and, at best, generate wisdom to impact and add value in a blunt way to the business.
We’ll cover the Apache Spark Ecosystem and its components. Like Apache Hadoop, Apache Spark can be integrated with several other tools, enabling creating a robust and accessible solution for big data processing.
In addition to the Spark API, additional libraries are part of this Ecosystem and provide other capabilities for Big Data analysis and Machine Learning.
In Apache Hadoop, we have two directions, Hadoop HDFS for distributed storage and Hadoop MapReduce for distributed processing. Many people get confused thinking that Apache Spark replaces Hadoop; in fact, Apache Spark is a competitor to Hadoop MapReduce; both process large datasets. Regardless of the processing, we have to store this data, and for this, we can use, for example, Hadoop HDFS.
Almost the entire Spark Ecosystem is free. We were able to set up an infrastructure for Big Data storage and processing at no license cost, but there is the cost of learning the tools. Using Apache Spark, Hadoop, and other products is not simple. There is a learning trajectory that has to be considered by the company and its professionals.
Because these are open-source solutions, in general, we do not have a single company offering support. No tool is perfect; we will always find pros and cons, and it is up to each company and professional to consider what is most relevant to each project. What we can see in the market is the increasing growth in the adoption of Apache Spark.
Apache Spark modules
We have two major modules: the Spark Core API, the main engine of Spark, the heart of the product, which we can use in the different languages listed, such as SQL, R, Python, Scala, and Java. And we also have the individual modules. Spark has four modules in addition to its main Spark Core API module:
• Spark Streaming
Apache Spark can use spark Streaming to process real-time data based on micro-batch computing, using DSTreaming, a series of Resilient Distributed Datasets — RDDs over time.
For example, the Twitter timeline that doesn’t stop, that is, millions and millions of people around the world making posts every minute — this is an example of real-time generated data. We can collect these tweets and store them in a database and perform a batch analysis, i.e., an offline analysis.
The advantage of performing a real-time analysis, for example, is a retail company tracking the study of its customers’ feelings in real-time, allowing you to change a marketing strategy during a specific time.
• Spark MLlib
It is a library consisting of machine learning algorithms, statistical tools, classification algorithms, regression, collaborative filters, clustering, dimensionality reduction, attribute extraction, optimization, etc.
Therefore, we may use Spark Streaming to collect and process data in real-time, and as we collect that data, we may apply one of the Spark MLlib libraries to apply Machine Learning to the data in real-time.
• Spark SQL
An Apache Spark module for processing structured data — 80% of what is generated in Big Data is unstructured. However, there is no analysis of unstructured data, but there is structured data analysis.
Therefore, when we collect data that most likely has no structure, we have to apply some form to this data, placing it in a tabulated, organized way, with rows and columns. We analyze through the many machine learning and statistical tools that work exclusively with structured data from its structuring.
With this module, we can easily integrate Apache Spark into other Hadoop Ecosystem products, such as Apache Hive — a kind of Data Warehouse for Hadoop.
• Spark GraphX
It allows Spark to perform graphical processing quickly and in memory, using parallel computing as well. GraphX supports computational graph computing (the essence of Deep Learning) and is one of today’s leading tools.
An excellent example of a graph is what we have on Facebook. Facebook has many connected nodes (people) — this is a computational graph. I have a friend who has a friend and who has another friend, this is generating a network, and this network is what we call a computational graph.
We can then perform a series of analyses, extract information, calculate statistics so that from there, Facebook can suggest a new friend, a product, or service and try to sell something to users.
These Spark modules are interchangeable, which means we can pass the data from one module to another. For example, Spark can pass streaming data to the SQL module.
The professionals who developed Apache Spark founded a startup called databricks. This startup offers advanced solutions for cluster management, one of the leading cloud products with Apache Spark. This combination has worked so well that companies like Amazon (web services) and Microsoft (Azure) also make it available in their cloud environments.
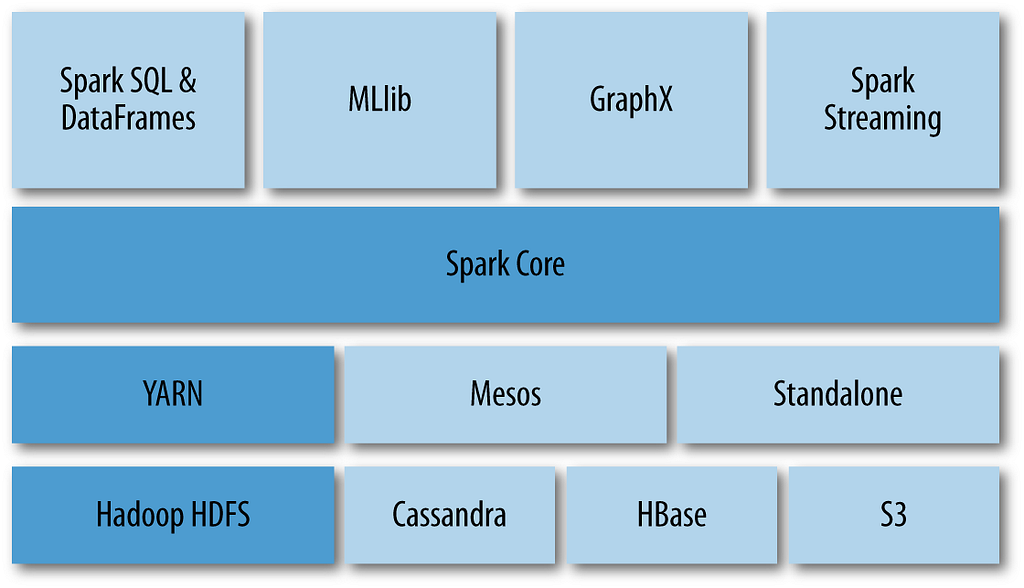
Apache Spark Ecosystem and Components
• Programming Layer
The programming layer is the highest layer of Apache Spark composition. To build an analysis process, we use one or more languages supported by Apache Spark: Python, R, Scala, Java. The best option would be for the Scala language because Apache Spark is to be developed and maintained in the Scala language.
The JAVA language is an excellent option since the Scala language is a kind of modification of the Java language. Python and R languages have an advantage because they are more straightforward. Therefore, there is no ideal world, and we should consider ease of application at the expense of performance and vice versa.
• Libraries Layer
Above the Spark Core engine, we have its libraries: SparkSQL, MLlib, GraphX, and Spark Streaming that have been described earlier. So we can use one of the libraries, or we can use them interchangeably, collecting the data in real-time with Spark Streaming, processing the structured data with SparkSQL, and applying machine learning with Spark MLlib, for example.
• Engine Layer
The main component of Apache Spark is Spark Core, the operating engine where we find the Resilient Distributed Datasets — RDDs, transformations, actions, etc.
• Management Layer
Below Spark Core, we have some products for management, such as Sparck Scheduler to schedule execution jobs with SPARK, YARN to manage clusters, and Mesos for cluster management.
• Storage Layer
Although Apache Spark does in-memory processing, the result has to be stored somewhere. Data is read and located on the disk, processed in memory, and writing is done again to the disk. It is worth noting that we have some data storage options. We can store data:
- Locally in our machine;
- Hadoop HDFS which is the distributed file storage system;
- RDBMS database or NoSQL non-relational database;
- S3, which is the Amazon Cloud Storage.
It is possible to create an entire local analysis procedure with Apache Spark, directly accessing the cloud data in S3.
Why Learn Apache Spark?
Big Data is already a concrete reality. Data is generated by people and machines never before seen by humanity, whether in clicks on websites, web searches, systems logs, social media posts, mobile phones, images, videos, messages between servers, IoT sensors; all this is data generated by billions of people worldwide.
Much of this data is generated in an unstructured way; about 80% of all data generated is unstructured. To handle this unstructured data, we use ETL processes for extracting, transforming, and loading data to make the data available for analysis and store all that volume of data generated at high speed and great variety — the main features of Big Data.
How to store and process all this data?
It is virtually impossible to store all this data on one machine. For this reason, we increasingly use clusters, that is, sets of connected computers (servers), which run as if they were a single system.
Each computer in the cluster is called a node, and each node performs the same task, being controlled by software. Typically, each component in a cluster is connected over local networks, and each node runs its operating system instance.
Distributed Analysis System
Apache Spark is a highly scalable, distributed data analysis system that enables in-memory processing and application development in Java, Scala, and Python and language in R.
Apache Spark extends the Hadoop MapReduce functionality by supporting more efficient computing tasks such as iterative queries and data streaming processing.
Speed is essential when we process large data sets, and one of the main features of Spark is its speed, enabling in-memory data processing, and is still quite efficient when we need to process data on disk. Spark uses memory distributed across multiple computers (nodes in a cluster).
The price of computers’ memory has been falling year after year, and in-memory processing is much faster than disk processing, so Spark is a promising technology.
Hadoop vs. Spark
While Hadoop stores the intermediate results of disk processing, Spark stores the intermediate results in memory. Memory is the significant differential of Apache Spark, being a scalable and efficient Big Data analysis tool.
Therefore, Apache Spark has an architecture built for sophisticated analysis, processing speed, and ease of use. It unifies critical data analysis functionality into a single framework (SQL, advanced analytics, machine learning, and data streaming).
More and more companies adopt Big Data infrastructure, which has Apache Spark as one of the main components. There is increasing support from other companies. There is still a high demand for professionals who know data processing, especially real-time data processing; putting Apache Spark in a Data Scientist’s toolbox is a brilliant decision. Because it is a powerful tool, it has its price — virtually all operations with Apache Spark are done via command line, without a graphical and intuitive interface. Because it is an advanced theme, few professionals dominate Apache Spark to create real-time data analysis solutions.
When to use Apache Spark?
• ETL Data Integration
ETL is the essence of any technology area; it’s extracting data from somewhere, transforming it, and loading it elsewhere. For example, Apache Hadoop can extract the data, transform it, and load it into an RDBMS database — Spark can do this with its features, much like any other ETL tool.
• Interactive Analysis
As much as Spark is for big data processing, we can use it for other fronts, even more so that everything in Apache Spark is programming and thus customizing the tool according to the needs of data scientists.
We can also perform interactive analyses, opening a terminal and run a direct query to the data. It is unnecessary to open an interface or browser; we have to open the terminal, run a query and collect information about the data — not every tool offers this possibility. With Apache Spark, we do this in a relatively simple way.
• High-Performance Batch Computing
High-performance Batch computing is the opposite of real-time computing. In real-time computing, we collect data, process, analyze and deliver the result, all in real-time.
Batch computing is to collect the data, store, process, and explore at another time; we do not have the real-time factor; that is, the goal is to compute and process the data at another time. Real-time data analysis is not yet the rule of the market, and in the vast majority of cases, computing is in Batch.
• Advanced Machine Learning Analytics
We can also perform advanced machine learning analysis. We can process the Machine Learning model on large data sets, which are distributed across computers. Apache Spark offers this possibility by bringing the main algorithms through MLlib component (regression, classification, clustering, recommendation systems, collaborative filters); if an application that uses this type of analysis is required, Apache Spark will do all this processing distributed way.
• Real-Time Data Processing
We collect the data in real-time with Spark Streaming and apply the machine learning algorithm to collect information, generate a type of analysis, or make some predictions (sentiment analysis, sales, maintenance of machines) depending on the use case.
These are the main scenarios where we can use Apache Spark. As we learn Spark, we should try to think about applying it to other situations, which will undoubtedly help us find new ways to use its power.
And there we have it. I hope you have found this helpful. Thank you for reading. ??
Apache Spark Ecosystem was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Anello
Anello | Sciencx (2021-04-30T01:35:54+00:00) Apache Spark Ecosystem. Retrieved from https://www.scien.cx/2021/04/30/apache-spark-ecosystem/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.