
This content originally appeared on DEV Community and was authored by Kyle Johnson
Running out of memory is not fun.
Unfortunately, when working with larger datasets its bound to happen at some point.
For example, I tried to run a Django management command that updated a value on a model with a large amount of rows in the database table:
python manage.py my_update_command
Killed
That was inside of Kubernetes which killed the process when it exceeded its memory limit. In a more traditional environment, you can completely freeze up the server if it runs out of memory.
Context
You're probably wondering why I'm trying to run a management command like this in the first place. When working with large datasets, its best to avoid anything that is O(n) or worse. In this case, I had a JSONField with a bunch of data. I also had an IntegerField on the model that stored a calculation based on some of the data in the JSONField.
Of course, requirements change and the calculation I had been using needed to use different values from the JSONField. This also needed to happen for all the existing data in the database (the large amount of rows). Luckily I had everything stored in the JSONField and making this change was as simple as running the management command and patiently waiting.
from django.core.management import BaseCommand
from ...models import SomeModel
from ...utils import some_calculation
class Command(BaseCommand):
help = "Updates SomeModel.field based on some_calculation"
def handle(self, *args, **options):
self.stdout.write("Starting")
try:
queryset = SomeModel.objects.all()
for obj in queryset:
obj.field = some_calculation(obj)
obj.save(update_fields=["field"])
except KeyboardInterrupt:
self.stdout.write("KeyboardInterrupt")
self.stdout.write("Done")
Killed, now what?
Naturally, it wasn't that simple. Method 1 was using enough memory to have Kubernetes stop it. I tried a few different things here including moving the code into a data migration and running multiple asynchronous tasks. I had difficulties getting these approaches working and struggled to monitor progress.
Really, I just wanted a simple, memory-efficient management command to iterate through the data and update it.
QuerySet.iterator
Django's built-in solution to iterating though a larger QuerySet is the QuerySet.iterator method. This helps immensely and is probably good enough in most cases.
However, method 2 was still getting killed in my case.
# simplified command using QuerySet.iterator
class Command(BaseCommand):
def handle(self, *args, **options):
queryset = SomeModel.objects.all().iterator(chunk_size=1000)
for obj in queryset:
obj.field = some_calculation(obj)
obj.save(update_fields=["field"])
Behold the Paginator
I needed to iterate through the QuerySet by using smaller chunks in a more memory-efficient manner then the iterator method. I started to roll out my own solution before I realized that this sounded very familiar. Django has pagination support built-in which is exactly what I was about to implement. I ended up using the Django Paginator to iterate through the QuerySet in chunks.
Method 4 works great.
# simplified command using Paginator
class Command(BaseCommand):
def handle(self, *args, **options):
queryset = SomeModel.objects.all()
paginator = Paginator(queryset, 1000)
for page_number in paginator.page_range:
page = paginator.page(page_number)
for obj in page.object_list:
obj.field = some_calculation(obj)
obj.save(update_fields=["field"])
Memory Usage
At this point there are the three methods described above, plus another two I added that use QuerySet.bulk_update:
- Regular QuerySet
- QuerySet.iterator
- QuerySet.iterator and QuerySet.bulk_update
- Paginator
- Paginator and QuerySet.bulk_update
I ran comparisons on these approaches with 50,000 items in the database. Here is memory usage for all five methods with three runs each:
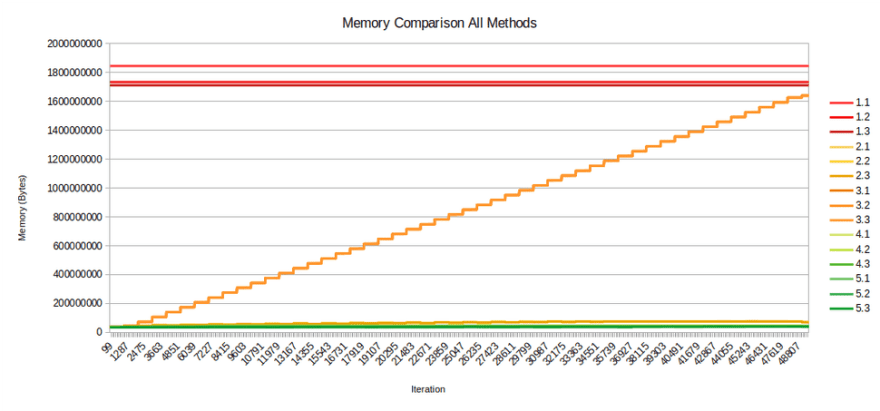
The plot clearly shows that method 1 is not a good choice since the entire QuerySet is loaded into memory before it can be used. Method 3 is also showing a steady increase in memory (note: it appears there is a memory leak here that I was unable to resolve). Zooming in on methods 2, 4 and 5 it becomes more clear that methods 4 and 5 are the winners:

I don't claim that the Paginator solution is always the best or even the best for my problem. More importantly it solved my problem and gave me the opportunity to dive into the memory differences between these approaches described above. If you have a similar problem, I recommend diving in and seeing how the comparison pans out for the specific problem.
A shortened version of the method 5 management command is:
# simplified command using Paginator and QuerySet.bulk_update
class Command(BaseCommand):
def handle(self, *args, **options):
queryset = SomeModel.objects.all()
paginator = Paginator(queryset, 1000)
for page_number in paginator.page_range:
page = paginator.page(page_number)
updates = []
for obj in page.object_list:
obj.field = some_calculation(obj)
updates.append(obj)
SomeModel.objects.bulk_update(updates, ["field"])
This article was originally posted on our blog.
This content originally appeared on DEV Community and was authored by Kyle Johnson
Kyle Johnson | Sciencx (2021-05-06T19:24:27+00:00) Efficient Iteration of Big Data in Django. Retrieved from https://www.scien.cx/2021/05/06/efficient-iteration-of-big-data-in-django/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.