
This content originally appeared on DEV Community and was authored by Antoine Veuiller
You probably already heard of Kubernetes, a powerful orchestrator that will ease deployment and automatically manage your applications on a set of machines, called a Cluster.
With great power comes great complexity, even in the eyes of Google. Thus, learning Kubernetes is oftentimes considered as cumbersome and complex, namely because of the number of new concepts you have to learn. On the other hand, those very same concepts can be found in other orchestrators. As a result, mastering them will ease your onboarding on other orchestrators, such as Docker Swarm.
The aim of this article is to explain the most used concepts of Kubernetes relying on basic system administration concepts, then use some of these to deploy a simple web server and showcase the interactions between the different resources. Lastly, I will lay out the usual CLI interactions while working with Kubernetes.
This article mainly focuses on the developer side of a Kubernetes cluster, but I will leave some resources about cluster administration at the end.
Terminology and concepts
Architecture
The Kubernetes realm is the cluster, everything needed is contained within this cluster. Inside it, you will find two types of nodes: the Control Plane and the Worker Nodes.
The control plane is a centralized set of processes that manages the cluster resources, load balance, health, and more. A Kubernetes cluster usually has multiple controller nodes for availability and load balancing purposes.
As a developer, you will most likely interact through the API gateway for interactions.
The worker node is any kind of host running a local Kubernetes agent Kubelet and a communication process Kube-Proxy. The former handles the operations commanded by the control plane on the local container runtime (e.g. docker), while the latter redirects connectivity to the right pods.

Namespaces
After some time, a Kubernetes cluster may become huge and heavily used. In order to keep things well organized, Kubernetes created the concept of Namespace. A namespace is basically a virtual cluster inside the actual cluster.
Most of the resources will be contained inside a namespace, thus unaware of resources from other namespaces. Only a few kinds of resources are completely agnostic of namespaces, and they define computational power or storage sources (i.e. Nodes and PersistentVolumes). However, access to those can be limited by namespace using Quotas.
Namespace-aware resources will always be contained in a namespace as Kubernetes creates and uses a namespace named default if nothing is specified.
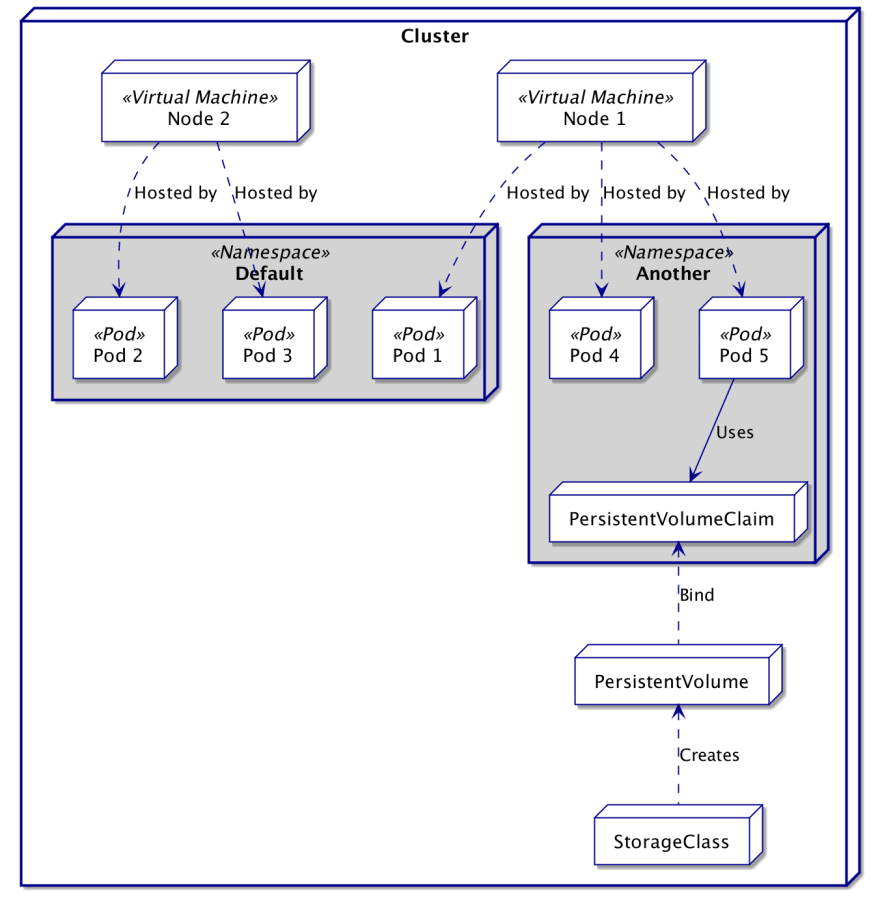
There is no silver bullet on the way to use namespaces, as it widely depends on your organization and needs. However, we can note some usual namespaces usages:
- Divide the cluster by team or project, to avoid naming conflict and help repartition of resources.
- Divide the cluster by environment (i.e. dev, staging, prod), to keep a consistent architecture.
- Deploy with more granularity (e.g. blue/green deployment), to quickly fall back on an untouched working environment in case of issue.
Further reading:
Glossary
Kubernetes did a great work of remaining agnostic of any technology in their design. This means two things: handle multiple technologies under the hood and there is a whole new terminology to learn.
Fortunately, these concepts are pretty straightforward and can most of the time be compared to a unit element of classic system infrastructure. The table below will summarize the binding of the most basic concepts. The comparison might not be a hundred per cent accurate but rather here to help understand the need behind each concept.
| Abstraction Layer | Physical Layer | Uses Namespace | Description |
|---|---|---|---|
| Pod | Container | ✅ | A Pod is the minimal work unit of Kubernetes, it is generally equivalent to one applicative container but it can be composed of multiple ones. |
| Replicaset | Load Balancing | ✅ | A ReplicaSet keeps track of and maintain the amount of instances expected and running for a given pod. |
| Deployment | - | ✅ | A Deployment keeps track of and maintain the required configuration for a pod and replicaset. |
| StatefulSet | - | ✅ | A StatefulSet is a Deployment with insurance on the start order and volume binding, to keep state consistent in time. |
| Node | Host | ❌ | A Node can be a physical or virtual machine that is ready to host pods. |
| Service | Network | ✅ | A Service will define an entrypoint to a set of pods semantically tied together. |
| Ingress | Reverse Proxy | ✅ | An Ingress publishes Services outside the Cluster. |
| Cluster | Datacenter | ❌ | A Cluster is the set of available nodes, including the Kubernetes controllers. |
| Namespace | - | ➖ | A Namespace defines an isolated pseudo cluster in the current cluster. |
| StorageClass | Disk | ❌ | A StorageClass configures filesystems sources that can be used to dynamically create PersistentVolumes. |
| PersistentVolume | Disk Partition | ❌ | A PersistentVolume describe any kind of filesystem ready to be mounted on a pod. |
| PersistentVolumeClaim | - | ✅ | A PersistentVolumeClaim binds a PersistentVolume to a pod, which can then actively use it while running. |
| ConfigMap | Environment Variables | ✅ | A ConfigMap defines widely accessible properties. |
| Secret | Secured Env. Var. | ✅ | A Secret defines widely accessible properties with potential encryption and access limitations. |
Further reading:
Definition files
The resources in Kubernetes are created in a declarative fashion, and while it is possible to configure your application deployment through the command line, a good practice is to keep track of the resource definitions in a versioned environment. Sometimes named GitOps, this practice is not only applicable for Kubernetes but widely applied for delivery systems, backed up by the DevOps movement.
To this effect, Kubernetes proposes a YAML representation of the resource declaration, and its structure can be summarized as follow:
| Field | File type | Content |
|---|---|---|
apiVersion |
All files | Version to use while parsing the file. |
kind |
All files | Type of resource that the file is describing. |
metadata |
All files | Resource identification and labeling. |
data |
Data centric files (Secret, ConfigMap) | Content entry point for data mapping. |
spec |
Most files (Pod, Deployment, Ingress, ...) | Content entry point for resource configuration. |
Watch out: some resources such as StorageClass do no use a single entry point as described above
Further reading:
Metadata and labels
The metadata entry is critical while creating any resource as it will enable Kubernetes and yourself to easily identify and select the resource.
In this entry, you will define a name and a namespace (defaults to default), thanks to which the control plane will automatically be able to tell if the file is a new addition to the cluster or the revision of a previously loaded file.
On top of those elements, you can define a labels section.
It is composed of a set of key-value pairs to narrow down the context and content of your resource. Those labels can later be used in almost any CLI commands through Selectors. As those entries are not used in the core behavior of Kubernetes, you can use any name you want, even if Kubernetes defines some best practices recommendations.
Finally, you can also create an annotations section, which is almost identical to labels but not used by Kubernetes at all. Those can be used on the applicative side to trigger behaviors or simply add data to ease debugging.
# <metadata> narrows down selection and identify the resource
metadata:
# The <name> entry is required and used to identify the resource
name: my-resource
namespace: my-namespace-or-default
# <labels> is optional but often needed for resource selection
labels:
app: application-name
category: back
# <annotations> is optional and not needed for the configuration of Kubernetes
annotations:
version: 4.2
Further reading:
Data centric configuration files
Those files define key-value mappings that can be used later in other resources. Usually, those resources (i.e. Secrets and ConfigMap) are loaded before anything else, as it is more likely than not that your infrastructure files are dependent on them.
apiVersion: v1
# <kind> defines the resource described in this file
kind: ConfigMap
metadata:
name: my-config
data:
# <data> configures data to load
configuration_key: "configuration_value"
properties_entry: |
# Any multiline content is accepted
multiline_config=true
Infrastructure centric configuration files
Those files define the infrastructure to deploy on the cluster, potentially using content from the data files.
apiVersion: v1
# <kind> defines the resource described in this file
kind: Pod
metadata:
name: my-web-server
spec:
# <spec> is a domain specific description of the resource.
# The specification entries will be very different from one kind to another
Resources definition
In this section, we will take a closer look at the configuration of the most used resources on a Kubernetes application. This is also the occasion to showcase the interactions between resources.
At the end of the section, we will have a running Nginx server and will be able to contact the server from outside the cluster. The following diagram summarizes the intended state:

ConfigMap
ConfigMap is used to hold properties that can be used later in your resources.
apiVersion: v1
kind: ConfigMap
metadata:
name: simple-web-config
namespace: default
data:
configuration_key: "Configuration value"
The configuration defined above can then be selected from another resource definition with the following snippet:
valueFrom:
configMapKeyRef:
name: simple-web-config
key: configuration_key
Note: ConfigMaps are only available in the namespace in which they are defined.
Further reading:
Secret
All sensitive data should be put in Secret files (e.g. API keys, passphrases, …). By default, the data is simply held as base64 encoded values without encryption. However, Kubernetes proposes ways of mitigating leakage risks by integrating a Role-Based Access Control or encrypting secrets.
The Secret file defines a type key at its root, which can be used to add validation on the keys declared in the data entry. By default, the type is set to Opaque which does not validate the entries at all.
apiVersion: v1
kind: Secret
metadata:
name: simple-web-secrets
# Opaque <type> can hold generic secrets, so no validation will be done.
type: Opaque
data:
# Secrets should be encoded in base64
secret_configuration_key: "c2VjcmV0IHZhbHVl"
The secret defined above can then be selected from another resource definition with the following snippet:
valueFrom:
secretKeyRef:
name: simple-web-secrets
key: secret_configuration_key
Note: Secrets are only available in the namespace in which they are defined.
Further reading:
Pod
A Pod definition file is pretty straightforward but can become pretty big due to the quantity of configuration available. The name and image fields are the only mandatory ones, but you might commonly use:
-
portsto define the ports to open on both the container and pod. -
envto define the environment variables to load on the container. -
argsandentrypointto customize the container startup sequence.
Pods are usually not created as standalone resources on Kubernetes, as the best practice indicates to use pod as part of higher level definition (e.g. Deployment). In those cases, the Pod file's content will simply be embedded in the other resource's file.
apiVersion: v1
kind: Pod
metadata:
name: my-web-server
spec:
# <containers> is a list of container definition to embed in the pod
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
protocol: TCP
env:
- name: SOME_CONFIG
# Create a line "value: <config_entry>" from the ConfigMap data
valueFrom:
configMapKeyRef:
name: simple-web-config
key: configuration_key
- name: SOME_SECRET
# Create a line "value: <config_entry>" from the Secret data
valueFrom:
secretKeyRef:
name: simple-web-secrets
key: secret_configuration_key
Note: Pods are only available in the namespace in which they are defined.
Further reading:
Deployment
The Deployment is generally used as the atomic working unit since it will automatically:
- Create a pod definition based on the
templateentry. - Create a ReplicaSet on pods selected by the
selectorentry, with the value ofreplicasas a count of pods that should be running.
The following file requests 3 instances of an Nginx server running at all times. The file may look a bit heavy, but most of it is the Pod definition copied from above.
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-web-server-deployment
namespace: default
labels:
app: webserver
spec:
# <selector> should retrieve the Pod defined below, and possibly more
selector:
matchLabels:
app: webserver
instance: nginx-ws-deployment
# <replicas> asks for 3 pods running in parallel at all time
replicas: 3
# The content of <template> is a Pod definition file, without <apiVersion> nor <kind>
template:
metadata:
name: my-web-server
namespace: default
labels:
app: webserver
instance: nginx-ws-deployment
spec:
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
protocol: TCP
env:
- name: SOME_CONFIG
# Create a line "value: <config_entry>" from the ConfigMap data
valueFrom:
configMapKeyRef:
name: simple-web-config
key: configuration_key
- name: SOME_SECRET
# Create a line "value: <config_entry>" from the Secret data
valueFrom:
secretKeyRef:
name: simple-web-secrets
key: secret_configuration_key
Note: Deployments are only available in the namespace in which they are defined.
Further reading:
Service
A pod might be deleted and recreated at any time. When it occurs the pod's IP address will change, which could result in a loss of connection if you are directly contacting it. To solve this issue, a Service provides a stable contact point to a set of Pods, while remaining agnostic of their state and configuration. Usually, Pods are chosen to be part of a Service through a selector entry, thus based on its labels. A Pod is selected if and only if all the labels in the selector are worn by the pod.
There are three types of services that are acting quite differently, among which you can select using the type entry.
The ClusterIP service is bound to an internal IP from the cluster, hence only internally reachable. This is the type of service created by default and is suitable for binding different applications inside the same cluster.
A NodePort service will bind a port (by default in range 30000 to 32767) on the nodes hosting the selected pods. This enables you to contact the service directly through the node IP. That also means that your service will be as accessible as the virtual or physical machines hosting those pods.
Note: Using NodePort can pose security risks, as it enables a direct connection from outside the cluster.
A LoadBalancer service will automatically create a load balancer instance from the cloud service provider on which the cluster is running. This load balancer is created outside the cluster but will automatically be bound to the nodes hosting the selected pods.
This is an easy way to expose your service but can end up being costly as each service will be managed by a single load balancer.
If you are setting up your own Ingress as we will do here, you may want to use a ClusterIp service, as other services are made for specific use cases.
apiVersion: v1
kind: Service
metadata:
name: simple-web-service-clusterip
spec:
# ClusterIP is the default service <type>
type: ClusterIP
# Select all pods declaring a <label> entry "app: webserver"
selector:
app: webserver
ports:
- name: http
protocol: TCP
# <port> is the port to bind on the service side
port: 80
# <targetPort> is the port to bind on the Pod side
targetPort: 80
Note: Services are defined in a namespace but can be contacted from other namespaces.
Further reading:
Ingress
Ingress enables you to publish internal services without necessarily using a load balancer from cloud service providers. You usually need only one ingress per namespace, where you can bind as many routing rules and backends as you want. A backend will typically be an internally routed ClusterIP service.
Please note that Kubernetes does not handle ingress resources by itself and relies on third-party implementations. As a result, you will have to choose and install an Ingress Controller before using any ingress resource. On the other hand, it makes the ingress resource customizable depending on the needs of your cluster.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: simple-web-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
rules:
# Using <host> redirects all request matching the given DNS name to this rule
- host: "*.minikube.internal"
http:
paths:
- path: /welcome
pathType: Prefix
backend:
service:
name: simple-web-service-clusterip
port:
number: 80
# All other requests will be redirected through this rule
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: simple-web-service-clusterip
port:
number: 80
Note: Ingresses are defined in the namespace but may contact services from other namespaces and are publicly accessible outside the cluster.
Further reading:
CLI Usage
Create and manage resources
This section showcases the basic CLI commands to manipulate resources. As said before, while it is possible to manually manage resources, a better practice is to use files.
# <kind> is the type of resource to create (e.g. deployment, secret, namespace, quota, ...)
$ kubectl create <kind> <name>
$ kubectl edit <kind> <name>
$ kubectl delete <kind> <name>
# All those commands can be used through a description file.
$ kubectl create -f <resource>.yaml
$ kubectl edit -f <resource>.yaml
$ kubectl delete -f <resource>.yaml
To ease resources manipulations through files, you can reduce the interactions to the CLI to the two following commands:
# Create and update any resource
$ kubectl apply -f <resource>.yaml
# Delete any resource
$ kubectl delete -f <resource>.yaml
Further reading:
Monitor and Debug
Fetch resources
You can see all resources running through the CLI using kubectl get <kind>. This command is pretty powerful and lets you filter the kind of resources to display or select the resources you want to see.
Note: if not specified, Kubernetes will work on the default namespace. You can specify -n <namespace> to work on a specific namespace or -A to show every namespace.
# Fetch everything
$ kubectl get all
NAME READY STATUS RESTARTS AGE
pod/my-web-server-deployment-58c4fd887f-5vm2b 1/1 Running 0 128m
pod/my-web-server-deployment-58c4fd887f-gq6lr 1/1 Running 0 128m
pod/my-web-server-deployment-58c4fd887f-gs6qb 1/1 Running 0 128m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/simple-web-service-clusterip ClusterIP 10.96.96.241 <none> 80/TCP,443/TCP 60m
service/simple-web-service-lb LoadBalancer 10.108.182.232 <pending> 80:31095/TCP,443:31940/TCP 60m
service/simple-web-service-np NodePort 10.101.77.203 <none> 80:31899/TCP,443:31522/TCP 60m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/my-web-server-deployment 3/3 3 3 136m
NAME DESIRED CURRENT READY AGE
replicaset.apps/my-web-server-deployment-58c4fd887f 3 3 3 128m
# We can ask for more details
$ kubectl get deployment -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
my-web-server-deployment 3/3 3 3 121m web nginx app=webserver
# Some resources are not visible using "all" but available
$ kubectl get configmap
NAME DATA AGE
kube-root-ca.crt 1 38d
simple-web-config 3 3h17m
Dig into a particular resource
This section will show you how to dig into resources. Most of the required day-to-day operations are doable through the three following commands.
The first command will give you the resource's complete configuration, using kubectl describe <kind>/<name>.
# Let's describe the ingress for the sake of example
$ kubectl describe ingress/simple-web-ingress
Name: simple-web-ingress
Namespace: default
Address: 192.168.64.2
Default backend: default-http-backend:80 (<error: endpoints "default-http-backend" not found>)
Rules:
Host Path Backends
---- ---- --------
*.minikube.internal
/welcome simple-web-service-clusterip:80 (172.17.0.4:80,172.17.0.5:80,172.17.0.6:80 + 1 more...)
*
/ simple-web-service-clusterip:80 (172.17.0.4:80,172.17.0.5:80,172.17.0.6:80 + 1 more...)
Annotations: nginx.ingress.kubernetes.io/rewrite-target: /
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal UPDATE 7m6s (x6 over 23h) nginx-ingress-controller Ingress default/simple-web-ingress
Another important command is kubectl logs <kind>/<name>, as you might expect it shows you the resources' logs if applicable. As the logs are produced by Pods, running such a command on a resource above a Pod will dig through Kubernetes to display the logs of a randomly chosen Pod underneath it.
$ kubectl logs deployments/my-web-server-deployment
Found 3 pods, using pod/my-web-server-deployment-755b499f77-4n5vn
# [logs]
Finally, it is sometimes useful to connect on a pod, you can do so with the command kubectl exec -it <pod_name> -- /bin/bash. This will open an interactive shell on the pod, enabling you to interact with its content.
# As for logs, when called on any resource enclosing Pods,
# Kubernetes will randomly chose one to execute the action
$ kubectl exec -it deployment/my-web-server-deployment -- /bin/bash
root@my-web-server-deployment-56c4554cf9-qwtm6:/# ls
# [...]
Conclusion
During this article, we saw the fundamentals behind deploying and publishing stateless services using Kubernetes. But you can do a lot more complex things with Kubernetes. If you want to learn more about it, I can recommend you to look at these resources:
- Read the Kubernetes reference documentation.
- Install a sandbox locally with Minikube, and play with it.
- Watch the video Kubernetes Tutorial for Beginners - TechWorld with Nana.
- Manually bootstrap a Kubernetes cluster: Kubernetes The Hard Way.
Incidentally, there are multiple subjects I could not deeply talk about in this article and that may be of interest.
On the developer side:
On the cluster administrator side:
Furthermore, if you are interested in the ecosystem around Kubernetes, you may want to take a look at the following technologies:
- Openshift is wrapping Kubernetes with production friendly features.
- Helm is a charts manager for Kubernetes helping improve re-usability of configuration files.
- ArgoCD is keeping your Kubernetes Cluster up to date with your configurations from Git.
Appendix
Resources' repository
The resources definitions used in this article are available in the following GitHub repository.
CLI equivalents - Docker and Kubernetes
Managing containers with Docker and pods with Kubernetes is very similar,
as you can see on the following table describing equivalent operations between both technologies.
| Operation | Docker | Kubernetes |
|---|---|---|
| Running containers | docker ps |
kubectl get pods |
| Configuration details | docker inspect <name> |
kubectl describe <name> |
| Show logs | docker logs <name> |
kubectl logs <name> |
| Enter container | docker exec -it <name> /bin/bash |
kubectl exec -it <name> -- /bin/bash |
Thanks to Sarra Habchi, Dimitri Delabroye, and Alexis Geffroy for the reviews
This content originally appeared on DEV Community and was authored by Antoine Veuiller
Antoine Veuiller | Sciencx (2021-05-11T08:05:08+00:00) Kubernetes: Apprentice Cookbook. Retrieved from https://www.scien.cx/2021/05/11/kubernetes-apprentice-cookbook/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.