
This content originally appeared on DEV Community and was authored by Sm0ke
Hello Coders,
This article explains how to parse and extract components from a LIVE website using open-source libraries and tools. Personally, I'm using HTML parsing to convert automatically components from one technology (Bootstrap) to others like React, Vue, Svelte with less manual work and better quality.
Thanks for reading! - The article is heavily inspired from here: Parse HTML Components
Parsing LIVE websites or lifeless HTML files might be useful in many scenarios. I will mention only a few:
- code a pricing scanner to detect changes
- check health for a LIVE system
- extract components and reuse previous work for evolutions
- extract texts from a LIVE website and check text errors
In the end, I will mention an open-source Django product that uses a UI built with components extracted from a Bootstrap 5 Kit using parsing code quite similar to the one presented in this article.
Tools we need
- Python - the interpreter
- Beautiful Soup - a well-known parsing library
- Lxml - used to compensate BS4 limitations
The process
- Load the HTML content - this can be done from a local file or using a LIVE website
- Analyze the page and extract XPATH expression for a component
- Use Lxml library to extract the HTML using Xpath selector
- Format the component and save it on disk
Install tools
$ pip install requests
$ pip install lxml
$ pip install beautifulsoup4
Once all tools and libraries are installed and accessible in the terminal, we can start coding using Python console.
$ python [ENTER]
>>>
The HTML content can be a local file or a remote one, deployed and rendered by a LIVE system.
Load the HTML from a local file (a simple file read)
>>> f = open('./app/templates/index.html','r')
>>> html_page = f.read()
Load content from a live website - Pixel Lite
>>> import requests
>>> page = requests.get('https://demo.themesberg.com/pixel-lite/index.html')
>>> html_page = page.content
At this point, html_page variable contains the entire HTML content (string type) and we can use it in BS4 or Lxml to extract the components. To visualize the page structure we can use browser tools:

The target component will be extracted using an XPATH expression provided by the browser:
//*[@id="features"]
Once we have the selector, let's extract the components using LXML library:
>>> from lxml import html
>>> html_dom = html.fromstring( html_page )
>>> component = html_dom.xpath( '//*[@id="features"]' )
If the XPATH selector returns a valid component, we should have a valid LXML object that holds the HTML code - Let's use it:
>>> from lxml.etree import tostring
>>> component_html = tostring( component[0] )
To have a nice formatted component and gain access to all properties like nodes, css style, texts .. etc, the HTML is used to build a Beautiful Soup object.
>>> from bs4 import BeautifulSoup as bs
>>> soup = bs( component_html )
>>> soup.prettify()
The component is now fully parsed and we can traverse all information and proceed further with a conversion to React.
<section class="section section-lg pb-0" id="features">
<div class="container">
<div class="row">
...
<div class="col-12 col-md-4">
<div class="icon-box text-center mb-5 mb-md-0">
<div class="icon icon-shape icon-lg bg-white shadow-lg border-light rounded-circle icon-secondary mb-3">
<span class="fas fa-box-open">
</span>
</div>
<h2 class="my-3 h5">
80 components
</h2>
<p class="px-lg-4">
Beatifully crafted and creative components made with great care for each pixel
</p>
</div>
</div>
...
</div>
</div>
</div>
</section>
This tool-chain will check and validate the component to be a valid HTML block with valid tags.
The extracted component
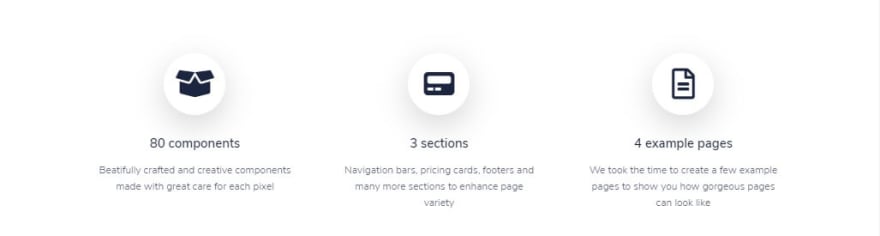
React component
class Comp extends React.Component {
render() {
return COMPONENT_HTML_GOES_HERE;
}
}
React Component usage
ReactDOM.render(<Comp />, document.getElementById('root'));
This process can be extended for more tasks and automation:
- detect page layouts
- validate links (inner and outer)
- check images size
To see a final product built using a component extractor please access Pixel Lite Django, an open-source product that uses a Bootstrap 5 design.
The project can be used by anyone to code faster a nice website using Django as backend technology and Bootstrap 5 for styling.
- Django Pixel Lite - LIVE Demo
- Pixel Lite - the original HTML design
Thanks for reading! For more resources please access:
- Use XPath in Beautiful Soup - related article published on StackOverflow
- Web Scraping - the right way (with sample)
This content originally appeared on DEV Community and was authored by Sm0ke
Sm0ke | Sciencx (2021-05-21T17:04:57+00:00) Parse LIVE Website – Extract component and convert to React. Retrieved from https://www.scien.cx/2021/05/21/parse-live-website-extract-component-and-convert-to-react/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.