
This content originally appeared on DEV Community and was authored by Pragati Verma
Git and GitHub are at the core of open source in today’s programming world. However, there are a lot of confusing terms that often seem similar yet can have conflicting meanings and uses. Let’s demystify these confusing terms by decoding their underlying meanings.
NOTE: This article expects some knowledge of Git and GitHub.

Origin and Upstream
From Git Documentation:
When you fork a repo and clone it locally, then there is a default remote called origin that points to your fork on GitHub, not the original repo it was forked from.
To keep track of the original repo, you need to add another remote named upstream.
This confusion arises when you are working on the clone of a forked repo. Upstream is what you would use to fetch from the original repo to keep your local copy in sync with the project you wanted to contribute to. Meanwhile, origin is what you would use to pull and push code to your fork, and thereafter you can contribute back to the upstream repo by making a pull request.

Remember: Remotes like upstream and origin are simply an alias that stores the URL of repositories. They can be named anything, but it’s a convention to set original repo’s remote as upstream.
Fetch and Pull
From Git Documentation:
git fetchcan fetch from either a single named repository or URL or from several repositories at once.
git pullincorporates changes from a remote repository into the current branch.
git fetch is the command that tells your local git to retrieve the latest meta-data info from the original yet doesn’t do any file transferring. It’s more like just checking to see if there are any changes available. git pull, on the other hand, git fetch and applies the changes from the remote repository to the local repository.
Remember: git pull is shorthand for git fetch followed by git merge FETCH_HEAD.
Putting it rather simply, git fetch can be used to know the changes done in the remote repo/branch since your last pull. This is useful to allow for checking before doing a git pull, which could change files in your current branch and working copy and potentially lose your changes, etc.
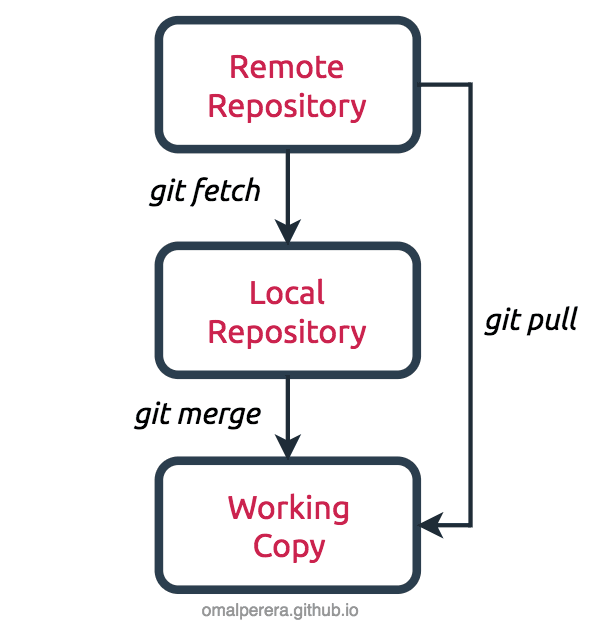
git fetch can be helpful in several scenarios, one of them being slightly optimizing your workflow to reduce network hits. Each git pull involves a git fetch, so if you want to get a pull on five different branches, you have four redundant extra git fetch calls.
Also, git fetch can often save you in situations you are working offline or working on the go, maybe on a train, but you want to make sure that you have all the changes from every branch available to you while working remotely. You can simply git fetch once while you’re on the network, and then leave. Later, without a network connection, you can manually git checkout branch; git merge origin/branch to merge the changes you previously fetched.
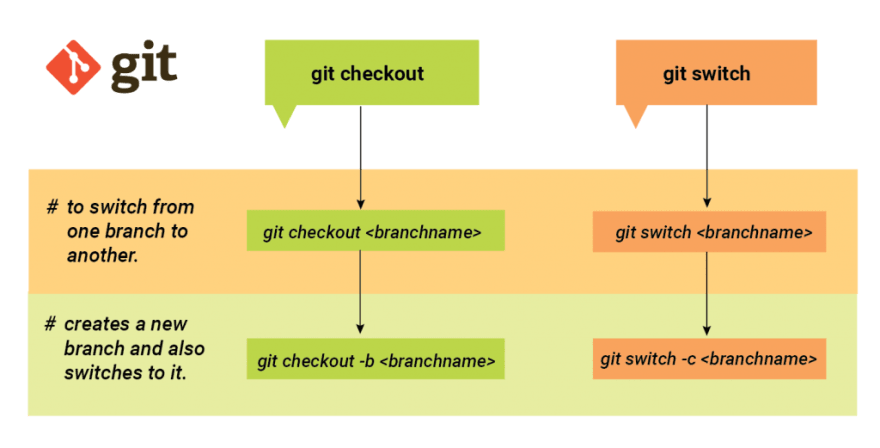
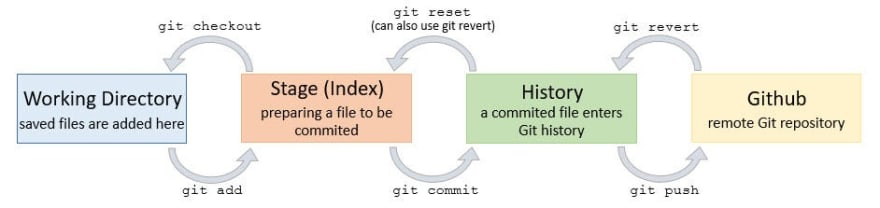
Switch and Checkout
From Git Documentation:
git switchswitches to a specified branch. The working tree and the index are updated to match the branch.
git checkoutupdates files in the working tree to match the version in the index or the specified tree.
git switch is not a new feature but an additional command to switch/change branch feature which is already available in the overloaded git checkout command. Hence, to separate the functionalities, Git 2.23 introduced the new git switch branch command which is an attempt to start to scale back to the responsibilities without breaking backward compatibility.
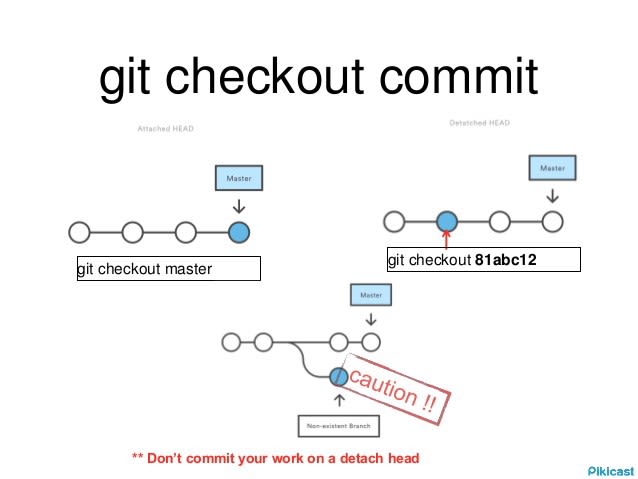
The git checkout command operates upon three distinct entities: files, commits, and branches. To put it simply, if you modify a file but haven’t staged the changes, then git checkout <filename> will discard the modifications and you would remain on the same branch, while git checkout <commit hash> lets you roll back to an older commit, whereas git checkout <branch> would switch the branches, hence, to avoid this confusion, git switch was introduced.
Below are the three most common use cases of git checkout:


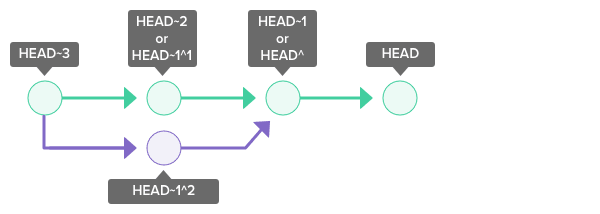
HEAD~ and HEAD^
The ~(tilde) and ^(caret) symbols are used to point to a position relative to a specific commit. The symbols are used together with a commit reference, typically HEAD(represents the current snapshot of a branch) or a commit hash.
-
~nrefers to the nth grandparent.HEAD~1refers to the commit’s first parent.HEAD~2refers to the first parent of the commit’s first parent.
-^n refers to the nth parent. HEAD¹ refers to the commit’s first parent. HEAD² refers to the commit’s second parent. A commit can have two parents in a merge commit.
Revert and Reset
From Git Documentation:
git revertis used to record some new commits to reverse the effect of some earlier commits (often only a faulty one).
git resetresets the currentHEADto the specified state.
The git revert command is used for undoing changes to a repository’s commit history. It is used to invert the changes introduced by a specific commit and append a new commit with the resulting inverse content. This can be useful for tracking down a bug introduced by a single commit so that it can be automatically fixed by a git revert command.
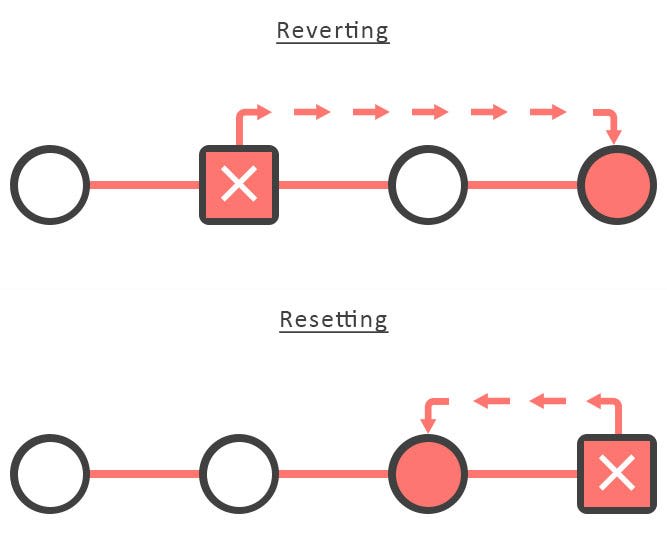
git reset is another complex and versatile git command used for undoing changes, however, git reset will move the HEAD ref pointer and the current branch ref pointer whereas the git revert command doesn’t move the HEAD ref pointer.

Putting it simply, if you have already pushed your branch somewhere or someone pulled from your branch, your only option is to git revert to undo the changes. Meanwhile, if you have kept your commits entirely local and private, you can simply use git reset to undo the changes.
Merge and Rebase
From Git Documentation:
git mergeincorporates changes from the named commits (since the time their histories diverged from the current branch) into the current branch.
git rebasereapplies commits on top of another base tip.
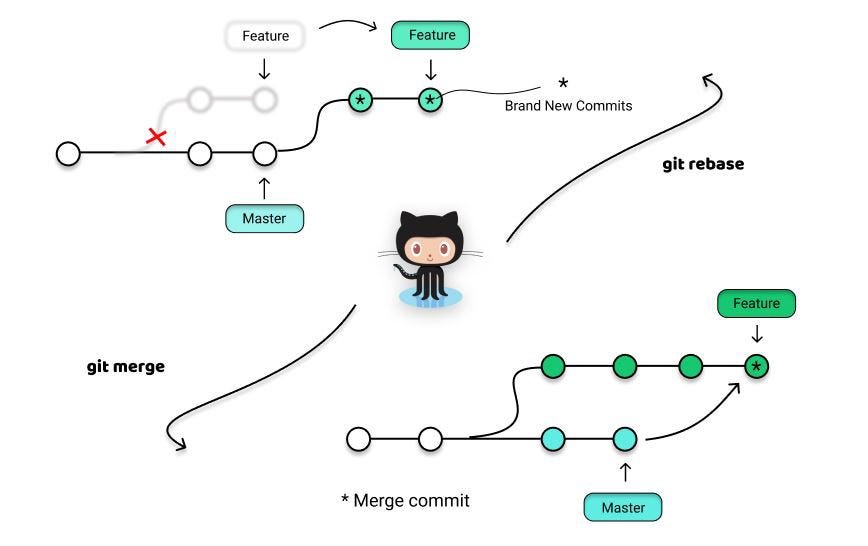
Both of these commands are designed to integrate changes from one branch into another branch, the difference lies in the way they do it. Rebasing is the process of moving or combining a sequence of commits to a new base commit while merging ties the histories of both branches and is always a forward-moving change record, hence, doesn’t change the existing branches in any way.
The major benefit of rebasing is that you get a much cleaner project history as it eliminates the unnecessary merge commits required by git merge.
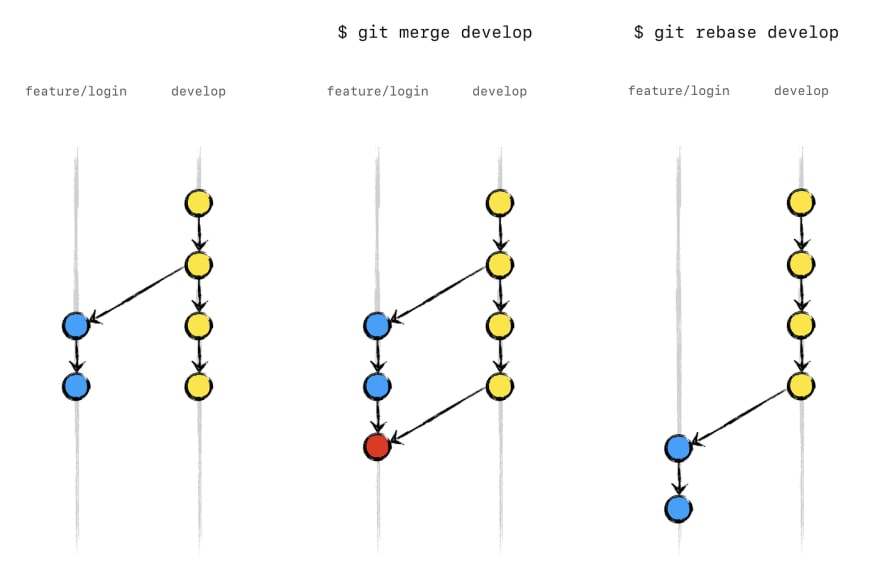
Rebasing works by transferring each local commit to the updated master branch one at a time. This means that you catch merge conflicts on a commit-by-commit basis rather than resolving all of them in one massive merge commit.
Moreover, rebasing makes it easier to figure out where bugs were introduced and if necessary to roll back changes with minimal impact on the project.
Use this handy git cheat sheet guide to enhance your workflow.
That’s all for this article. I hope that it would have helped you demystify some of the confusing terminologies related to git and GitHub. Please comment with your valuable suggestions and feedback.
In case you want to connect with me, follow the links below:
LinkedIn | GitHub | Twitter | Medium
This content originally appeared on DEV Community and was authored by Pragati Verma
Pragati Verma | Sciencx (2021-05-30T10:43:56+00:00) Confusing Terms in the Git Terminology. Retrieved from https://www.scien.cx/2021/05/30/confusing-terms-in-the-git-terminology/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.