
This content originally appeared on Level Up Coding - Medium and was authored by Trung Anh Dang
Thought Architect
Enables a system to continue operating properly in the event of the failure of some of its modules
Many monitoring and fault tolerance techniques have been developed, applied, and improved over the past four decades to represent general solutions to recurring problems in the design of system architectures. And In this article, I will focus on the techniques you should use when communicating with other modules to make your modules fault-tolerant and monitoring in a distributed system.
What’s a distributed system?
A distributed system is a system whose components are located on different networked computers, which communicate and coordinate their actions by passing messages to one another from any system¹.
Fault Tolerance
This is an important term in the distributed system. It is the ability of a system to continue functioning in the event of a partial failure but overall performance may get affected.
Since distributed systems are comprised of various components, developing a system that is approximately a hundred percent fault-tolerant is practically very challenging.
Why systems fail
There are two main reasons for the occurrence of fault as follows.
- Node failure: hardware or software failure.
- Malicious error: caused by unauthorized access.
A system fails when the system cannot meet its promises.
Why we need fault tolerance in distributed systems?
Using fault tolerance in distributed systems, we can get advantages of quality as follows.
- Reliability: focuses on a continuous service with out any interruptions.
- Availability: concerned with read readiness of the system.
- Security: prevents any unauthorized access.
A distributed system is one in which the failure of a computer you didn’t even know existed can render your own computer unusable — Leslie Lamport.
It is hard to avoid failures, so embrace them…!!!
How to implement — fault tolerance patterns?
There are three aspects of fault tolerance techniques that are divided into error detection, error recovery, and error masking.
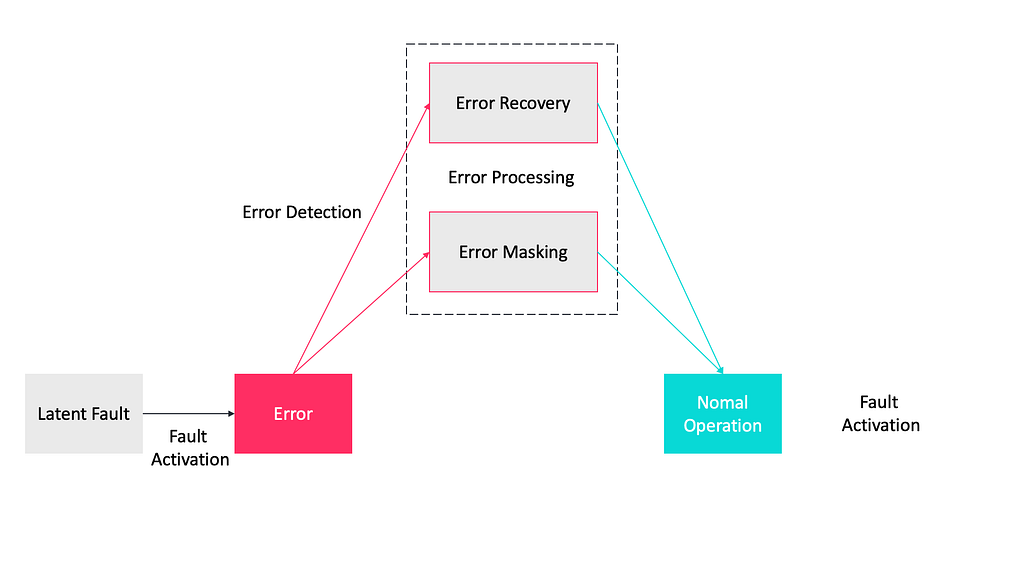
- Error Detection: Acknowledgement, “Are You Alive”, Circuit Breaker, Fail-Stop Processor, “I Am Alive”.
- Error Recovery: Backup, Roll Forward and Roll Back.
- Error Masking: Active Replication, Semi-Active Replication, Semi-Passive Replication, Passive Replication Replication.
There are many patterns but we will only focus on important patterns that be applied popularly in practice.
Acknowledgement
The idea² is to detect errors in a system by acknowledging the reception of an input within a specified time interval.
Context and Problem
The Acknowledgement pattern applies to a system that the frequency of interactions between the monitored system and monitoring system may vary a lot and in a known time.
- Minimizing the time overhead introduced by the detection technique.
- Decreasing the communication between the monitored system and the monitoring system.
Solution
The idea is to detect errors in a system by acknowledging the reception of input within a specified time interval.
Structure
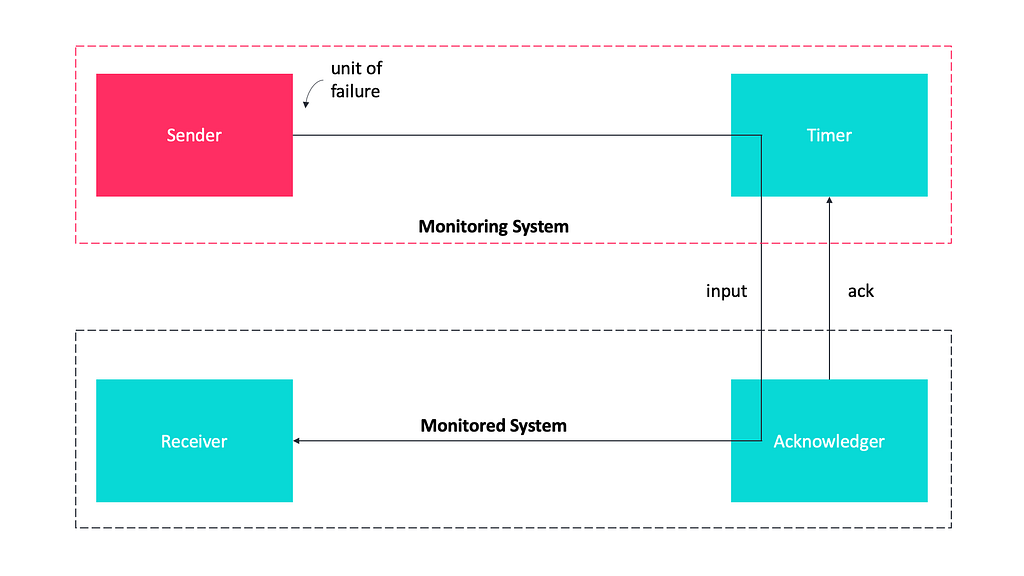
In the Acknowledgement pattern, the Sender in conjunction with the Timer constitutes the Monitoring System and the Receiver in conjunction with the Acknowledger entity constitutes the Monitored System.
- The Sender is individually responsible for contacting the Monitored System.
- Whenever the Sender has sent the input to the Receiver, the Timer that is responsible for counting down the timeout period every time an input is provided to the Monitored System, is activated.
- Upon receiving an input by the Sender, the Receiver notifies the Acknowledger. The Acknowledger is then responsible for sending an acknowledgment to the Timer for the received input. If the timeout period of the Timer expires for N consecutive times without receiving an acknowledgment from the Monitoring System, the Timer detects an error on the Monitored System and notifies the Sender.
Consequences
The Acknowledgement pattern has the following advantages:
- The design complexity introduced is very low.
- Does not introduce any space overhead.
But the Acknowledgment pattern also has some disadvantages:
- Does not provide means to tolerate faults in a system. Rather, it provides means to detect errors.
- It introduces relatively elevated space overhead that is proportional to the number of simultaneous errors it can deal with
Circuit Breaker Pattern
If you’re in any way familiar with the way fuses work in your home’s electrical panel, you’ll understand the principles of a circuit breaker pattern.
Context and Problem
How to prevent a network or components failure from flowing to other components?
Solution
The solution to the above problem proposed by the ‘Circuit Breaker’ pattern is based
Structure
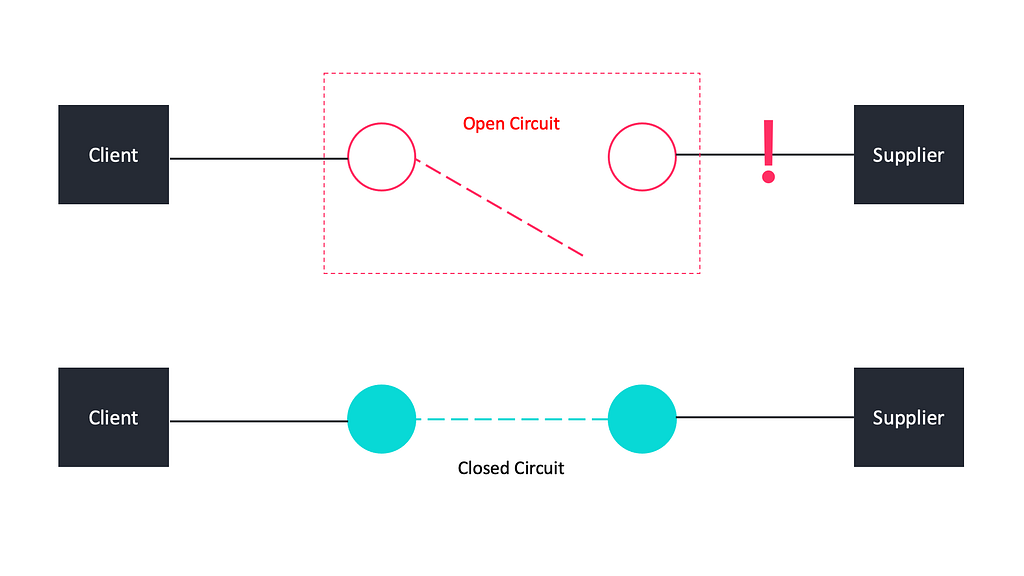
The circuit breaker has 3 distinct states, closed, open, and half-open.
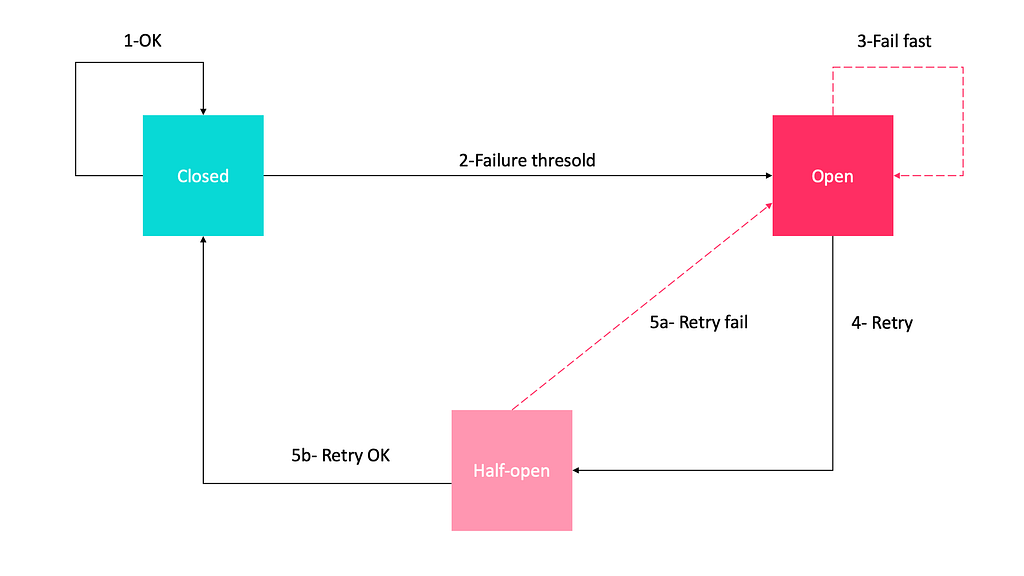
- Closed State: the closed state is the default “everything is working as expected” state. Requests pass freely through. When certain failures happen, they cause a circuit break and closed moves to open.
- Open State: the open state rejects all requests for a fixed amount of time without attempting to send them. Once the breaker trips, it enters the open state. At this point, any requests to the service will fail automatically.
- Half-open State: the breaker allows a set number of requests through in order to test the status of the resource. The half-open state determines if the circuit returns to closed or open.
Use cases
We use this pattern to prevent an application from trying to invoke a remote service or access a shared resource if this operation is highly likely to fail.
But this pattern is not recommended for the following two use cases.
- For handling access to local private resources in an application, such as in-memory data structure. In this environment, using a circuit breaker would add overhead to your system.
- As a substitute for handling exceptions in the business logic of your applications.
How it’s used in practice?
There are three various implementation approaches for the circuit breaker pattern: client-side circuit breaker, server-side circuit breaker and proxy circuit breaker.
One of the most famous implementations of circuit breakers is provided by the Hystrix³ library, which allows to wrap Java code in a procedure that will be controlled by a circuit breaker.
Consequences
The circuit breaker pattern requires additional requests and responses to perform some sort of handshaking before each communication.
Roll Forward
Once we detect an error the system must recover from it in order to qualify as fault-tolerant.
Context and Problem
We apply this pattern when the errors are detectable and the system is capable of saving its current state and loading a new state⁴.
Solution
The roll-forward pattern avoids loss of work by using checkpoints to recover the components to a stable state immediately before the error or failure event.
Structure
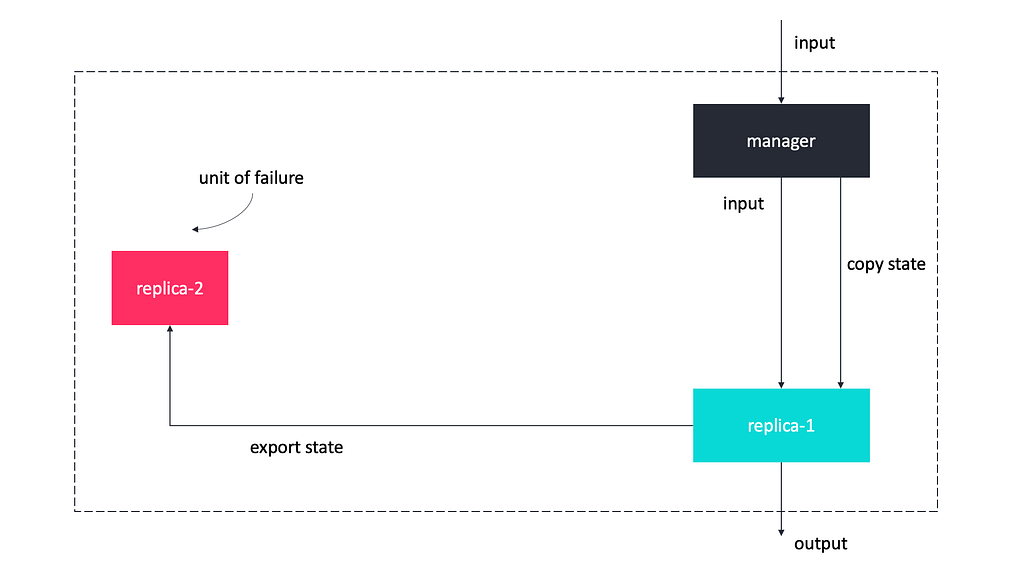
The roll-foward pattern consists of elements as follows.
- The replicas, which are copy versions of the original system, each replica is capable of exporting their state and importing a new state upon request. Each replica also must to mapped to a different unit of failure.
- The manager, which is responsible for receiving all input meant for the fault-tolerant system and forwarding it to the appropriate replica. in the absence of errors, the manager triggers the copy of the new state from the replica that processed the latest input to the other replicas that kept a previously error-free state.
- The manager also relies on an error detection mechanism to detect errors that may occur on the replicas. When such an error occurs on a replica, the manager is responsible for discarding that replica.
- The manager must be mapped to a different unit of failure than any of the replicas.
Consequences
The design complexity and the time overhead in this pattern are relatively low but the patterns also have some of the following disadvantages.
- The space overhead is relatively elevated and the entire system is replicated.
- The time overhead is in the absence of errors is high because it must copy its new state to another replica before the current replica is able to receive and process new input.
Roll Back
This pattern is another technique to recover from the occurrence of errors using system replicas. It has similar functionality as the roll forward mechanism; however, one replica rolls back to the last error-free state if a failure occurs.
Context and Problem
We apply this pattern when the errors are detectable and the system is capable of saving its current state and loading a new state.
This pattern solves the problem of recovering from an error by minimizing the time overhead for error-free system execution and assurance that the error-free state restored after an error occurred is as close as possible to the last error-free state the failed replica.
Solution
Solving these above problems is based on the use of two replicas of the system and a storage to save the checkpoints.
Structure
The rollback pattern consists of elements as follows.
- The replicas, which are copies of the original system identical to each other and which are monitored for errors.
- The storage, which is used to store the checkpoints that contain the state that the replica that processes the input exports at certain moments.
- The replicas may replace the storage in the following way: when the checkpoints are created, each replica exports them to the other replicas and imports from them the checkpoints these replicas have created.
Keep in mind that if the storage is used then it must not be subject to errors.
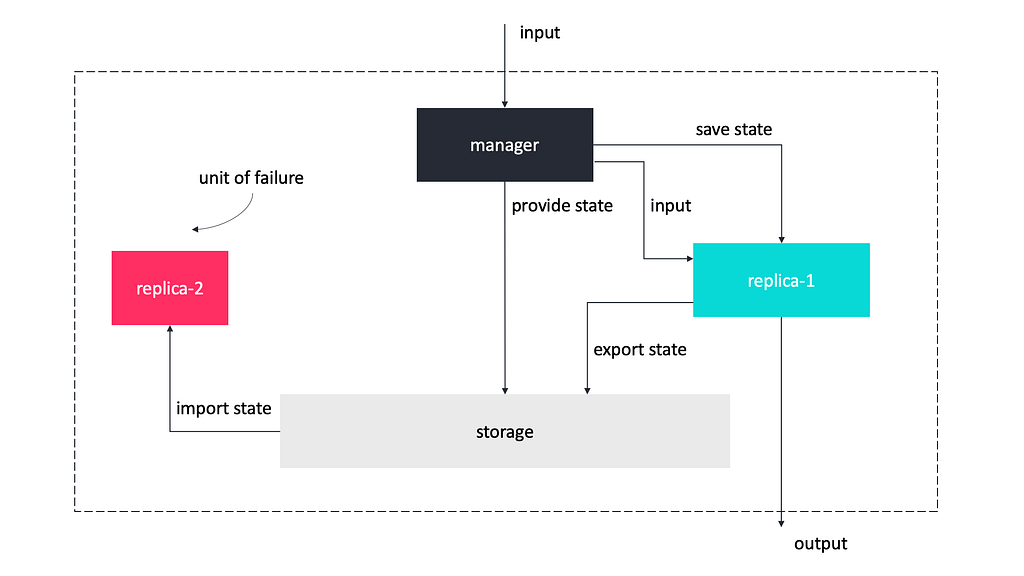
- The manager is responsible for receiving all input meant for the fault-tolerant system and forward it to the appropriate replica.
- In the absence of errors, the manager triggers the copy of the new state from the replica that processed the last input to the storage.
- The manager also relies on an error detection mechanism to detect errors that may occur on the replicas. When such an error occurs on a replica, the manager is responsible for discarding that replica. The manager must be mapped to a different unit of failure than any of the replicas.
Consequences
The advantages and disadvantages of this pattern are equally like the roll-forward pattern.
Active Replication Pattern
The Active replication pattern is the enhancement of the Fail-Stop Processor⁵ pattern from error detection to errror masking.
Context and Problem
Applications or critical systems that are deterministic and which can experience errors that are not related to the input they receive. The system should be able to experience errors that could lead to failures.
How to mask errors in a system so as to avoid system failure. Some applications, in particular, airline and health care systems require the masking of errors so as to avoid system failure that can lead to errors.
Solution
The solution to this problem is affected by the following forces:
- The input received by the system must be processed and deliver the designated output independently of whether an error occurs on the system.
- The error-free execution of the system must suffer minimum time penalties.
- The time penalty introduced by the solution in the presence of errors must be kept very low.
- The system must be deterministic.
We will use a set of processors which receive the same input and delivery order and conduct processing on their inputs independently and simultaneously. The output from each processor will be compared and the correct output will be selected and delivered to the system.
Structure
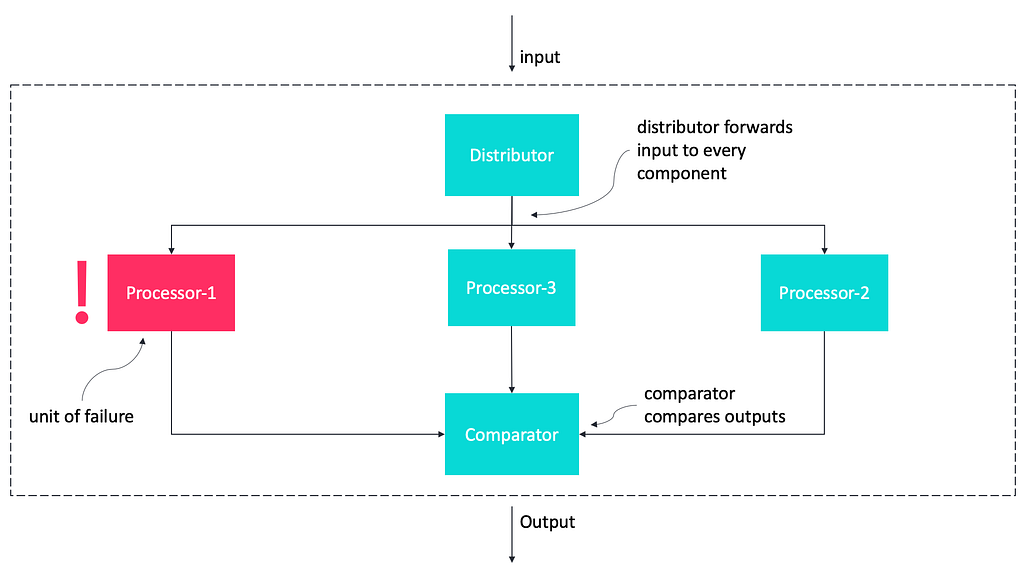
The entities introduced by the Active Replication pattern are as follows.
- The Sender sends an input to the distributor and not directly to the system.
- The Distributor initializes all processors and delivers the same input to each respective processor for processing.
- Processor 1, Processor 2 and Processor 3 receive input from the distributor and each performs the same operation on the input however they do so independently.
- All three processors deliver their output to the Comparator when they have completed processing on the input. The Comparator receives the outputs from the Processors and compares (e.g. Majority voting) on the three outputs. It selects one output and discards the processor that provided no output or an incorrect output that is, an output that is different from the one it selected as correct.
- The Comparator delivers the correct output to the system. The System represents the protected application or environment that gets the correct output from the comparator.
Consequences
The Active Replication Pattern has advantages as follows.
- The time overhead introduced by this pattern in error-free system execution is low. In the presence of errors, the time overhead introduced by this pattern is also low.
- The design complexity is relatively low.
The Active Replication Pattern has the following disadvantages.
- The space overhead of this pattern is very high, it takes 2N+1 replicas to mask N errors.
- The distributor and the comparator also are single points of failure in the system.
Conclusion
Concluding this article, we can say that the objective of creating a fault-tolerant system is to prevent disruptions arising from a single point of failure, ensuring the high availability of mission-critical applications or systems. It helps the business is still going well.
Easy, right?
References
[1] Tanenbaum, Andrew S.; Steen, Maarten van (2002). Distributed systems: principles and paradigms. Upper Saddle River, NJ: Pearson Prentice Hall. ISBN 0–13–088893–1.
[2] I. A. Buckley and E.B. Fernandez, “Three patterns for fault tolerance” , Procs. of the OOPSLA MiniPLoP, October 26, 2009.
[3] https://github.com/Netflix/Hystrix
[4] Saurabh Hukerikar, Christian Engelmann, Pattern-based Modeling of High-Performance Computing Resilience. Oak Ridge National Laboratory.
[5] Schneider, Fred. (2001). The Fail-Stop Processor Approach.
Design Patterns: Top 5 Techniques for Implementing Fault Tolerance in Distributed Systems was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Trung Anh Dang
Trung Anh Dang | Sciencx (2021-06-09T02:28:04+00:00) Design Patterns: Top 5 Techniques for Implementing Fault Tolerance in Distributed Systems. Retrieved from https://www.scien.cx/2021/06/09/design-patterns-top-5-techniques-for-implementing-fault-tolerance-in-distributed-systems/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.