
This content originally appeared on DEV Community and was authored by
With Spring Boot + Kotlin + Coroutines + GraphQL-java-kickstart, you can build a GraphQL Gateway with a minimum of boilerplate.
Up and Running
The code is available at
 jmfayard
/
spring-playground
jmfayard
/
spring-playground
A playground of Spring projects
spring-playground
Projects
- graphql-gateway based on kotlin + spring-webflux + graphql-java-kickstart
- spring-fu based on coroutines + spring-kafu
Run the server like this:
git clone https://github.com/jmfayard/spring-playground
cd spring-playground/graphql-gateway
./gradlew bootRun
Open GraphiQL at http://localhost:8080/
Animal facts
With this project up and running, you can fetch animal facts using a GraphQL Query.
Enter this query:
query {
dog {
fact
length
latency
}
cat {
fact
length
latency
}
}
Run the query, and you will see something like this:
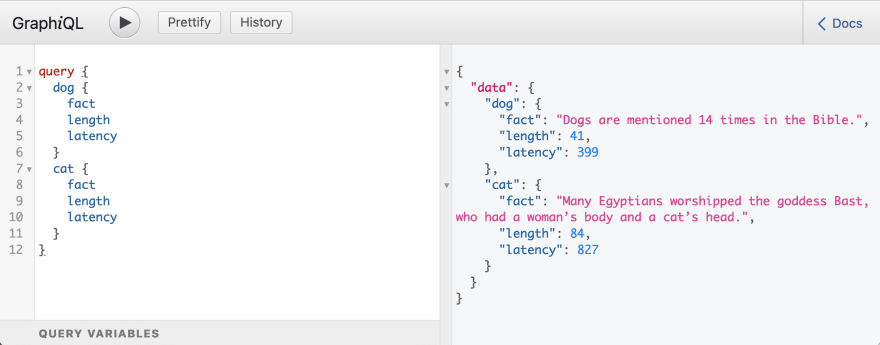
If you are new to GraphQL, read this introduction from @methodcoder, I will wait

Cat facts and dog facts
Where do the animal facts come from?
The server knows about two REST APIs.
The first is about cat facts:
$ http get https://catfact.ninja/fact
{
"fact": "Isaac Newton invented the cat flap. Newton was experimenting in a pitch-black room. Spithead, one of his cats, kept opening the door and wrecking his experiment. The cat flap kept both Newton and Spithead happy.",
"length": 211
}
And the second about dog facts:
$ http get https://some-random-api.ml/facts/dog
{
"fact": "A large breed dog's resting heart beats between 60 and 100 times per minute, and a small dog breed's heart beats between 100-140. Comparatively, a resting human heart beats 60-100 times per minute."
}
By building a simple gateway, we take on complexity so that the front-end developers have one less thing to worry about:
- we take care of calling the multiple endpoints and combining them, becoming a backend-for-frontend.
- we offer a nice GraphQL schema to the front-end(s).
- we normalize the response format - dog facts have no length attribute, but we can compute it!
- we can potentially reduce the total response time. Without the gateway, the front-end would do two round-trips of let say 300 ms, so 600ms. With the gateway, there is one round-trip of 300 ms and two round-trips between the gateway and the facts server. If those are located on the same network, those could be done in 10 ms each, for a total of 320 ms.
So how do we build that gateway?
Dependencies
If you start a new project from scratch via https://start.spring.io/, you will need to add those dependencies:
- Spring webflux
- GraphQL-java
- GraphQL-java-kickstart libraries
Note that I'm using gradle refreshVersions to make it easy to keep the project up-to-date. Therefore, the versions are not defined in the build.gradle files, they are centralized in the versions.properties file. RefreshVersions is bootstrapped like this in settings.gradle.kts:
plugins {
// See https://jmfayard.github.io/refreshVersions
id("de.fayard.refreshVersions") version "0.10.1"
}
GraphQL-schema first
GraphQL-java-kickstart uses a schema-first approach.
We first define our schema in resources/graphql/schema.grqphqls :
type Query {
cat: Fact!
dog: Fact!
}
type Fact {
fact: String!
length: Int!
}
We then tell Spring where our GraphQLSchema comes from:
@Configuration
class GraphQLConfig {
@Bean
fun graphQLSchema(animalsQueryResolver: AnimalsQueryResolver)
: GraphQLSchema {
return SchemaParser.newParser()
.file("graphql/schema.graphqls")
.resolvers(animalsQueryResolver)
.build()
.makeExecutableSchema()
}
}
Spring wants at least a GraphQLQueryResolver, the class responsible for implementing GraphQL queries.
We will define one, but keep it empty for now:
@Component
class AnimalsQueryResolver() : GraphQLQueryResolver {
}
GraphQLQueryResolver
If we start our application with ./gradlew bootRun, we will see it fail fast with this error message:
FieldResolverError: No method or field found as defined in schema graphql/schema.graphqls:2
with any of the following signatures
(with or without one of [interface graphql.schema.DataFetchingEnvironment] as the last argument),
in priority order:
dev.jmfayard.factsdemo.AnimalsQueryResolver.cat()
dev.jmfayard.factsdemo.AnimalsQueryResolver.getCat()
dev.jmfayard.factsdemo.AnimalsQueryResolver.cat
The schema, which is the single source of truth, requires something to implement a cat query, but we didn't have that in the code.
To make Spring happy, we make sure our Query Resolver has the same shape as the GraphQL schema:
@Component
class AnimalsQueryResolver : GraphQLQueryResolver {
suspend fun dog(): Fact = TODO()
suspend fun cat(): Fact = TODO()
}
data class Fact(
val fact: String,
val length: Int
)
Notice that you can directly define a suspending function, without any additional boilerplate, to implement the query.
Run again ./gradlew bootRun and now Spring starts!
We go one step further by forwarding the calls to an AnimalsRepository:
@Component
class AnimalsQueryResolver(
val animalsRepository: AnimalsRepository
) : GraphQLQueryResolver {
suspend fun dog(): Fact = animalsRepository.dog()
suspend fun cat(): Fact = animalsRepository.cat()
}
How do we implement this repository? We need an HTTP client.
Suspending HTTP calls with ktor-client
We could have used the built-in reactive WebClient that Spring provides, but I wanted to use ktor-client to keep things as simple as possible.
First we have to add the dependencies for ktor, http and kotlinx-serialization, then configure our client.
See the commit Configure ktor-client, okhttp & kotlinx.serialization
The most interesting part is here:
@Component
class AnimalsRepository(
val ktorClient: HttpClient
) {
suspend fun dog(): Fact {
val dogFact = ktorClient.get<DogFact>(DOG_FACT_URL)
return Fact(fact = dogFact.fact, length = dogFact.fact.length)
}
suspend fun cat(): Fact {
val catFact = ktorClient.get<CatFact>(CAT_FACT_URLS)
return Fact(fact = catFact.fact, length = catFact.length)
}
}
Simple or non-blocking: why not both?
When I see the code above, I am reminded that I love coroutines.
We get to write code in a simple, direct style like in the old days when we were writing blocking code in a one-thread-per-request model.
Here it's essential to write non-blocking code: the gateway spends most of its time waiting for the two other servers to answer.
Code written using some kind of promise or reactive streams is therefore clearly more efficient than blocking code.
But those require you to "think in reactive streams" and make your code looks different indeed.
With coroutines, we get the efficiency and our code is as simple as it gets.
Resilience via a Circuit Breaker
We have a gateway, but it's a bad gateway.
More precisely, it's as bad as the worst of the servers it depends on to do its job.
If one server throws an error systematically or gets v e r y s l o w, our gateway follows blindly.
We don't want the same error to reoccur constantly, and we want to handle the error quickly without waiting for the TCP timeout.
We can make our gateway more resilient by using a circuit breaker.
Resilience4j provides such a circuit breaker implementation.
We first add and configure the library.
See the commit: add a circuit breaker powered by resilience4j.
The usage is at simple as it gets:
@Component
class AnimalsRepository(
val ktorClient: HttpClient,
+ val dogCircuitBreaker: CircuitBreaker,
+ val catCircuitBreaker: CircuitBreaker
) {
suspend fun dog(): Fact {
+ val dogFact = dogCircuitBreaker.executeSuspendFunction {
ktorClient.get<DogFact>(DOG_FACT_URL)
+ }
return Fact(
fact = dogFact.fact,
length = dogFact.fact.length,
)
}
suspend fun cat(): Fact {
+ val catFact = catCircuitBreaker.executeSuspendFunction {
ktorClient.get<CatFact>(CAT_FACT_URLS)
+ }
return Fact(
fact = catFact.fact,
length = catFact.length,
)
}
}
I want to learn more
See spring-playground/graphql-gateway
jmfayard
/
spring-playground
A playground of Spring projects
spring-playground
Projects
- graphql-gateway based on kotlin + spring-webflux + graphql-java-kickstart
- spring-fu based on coroutines + spring-kafu
The talk that inspired this article: KotlinFest2019「Future of Jira Software powered by Kotlin」 #kotlinfest - YouTube
Documentation of the libraries used in this project:
- Getting started with a Ktor client | Ktor
- About GraphQL Spring Boot - GraphQL Java Kickstart
- About GraphQL Java Tools - GraphQL Java Kickstart
- graphql-java/graphql-java: GraphQL Java implementation
- Resilience4j
- Another approach: Creating a Reactive GraphQL Server with Spring Boot and Kotlin
If you want to contact me, there is a standing invitation at https://jmfayard.dev/contact/.
This content originally appeared on DEV Community and was authored by
| Sciencx (2021-06-14T16:04:55+00:00) How to build a GraphQL Gateway with Spring Boot and Kotlin. Retrieved from https://www.scien.cx/2021/06/14/how-to-build-a-graphql-gateway-with-spring-boot-and-kotlin/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.