
This content originally appeared on DEV Community and was authored by Kathan Vakharia
My Assumptions before you continue...
- You know basic data structures(
list,dict,tupleandset) in python. - You are familiar with NumPy Basics. If not, check out my colab notebook where I have explained it from the ground up :)
- You have already setup your Data Science environment.
Why Pandas if we already have NumPy?
- Numpy has the following limitations:
- No support for column names.
- datatype of all elements must be the same.
- No pre-built methods for common analysis tasks.
- Pandas can handle a large amount of data at ease!
Pandas library overcomes the limitations of NumPy, and sometimes it is also referred to as a swis army knife of Data Analysis!
And don't you worry about losing the vectorization power, Pandas is built upon NumPy so internally, it makes use of NumPy code extensively!
 By the way, the above image is not an over-exaggeration of pandas' capabilities!
By the way, the above image is not an over-exaggeration of pandas' capabilities!
Enough of the theory, let me show you some code otherwise you might leave this blog ? So fire up your Jupyter notebook/lab or whatever IDE you use for Data Science and let's start!
Lastly, we are going to use a dataset on pokemon to keep things fun and interesting ? You can find it on kaggle.
Introducing the Pandas Dataframe
It is the primary data structure provided by pandas. Formally, a Dataframe is a 2-Dimensional labeled tabular data structure. It is a 2D NumPy array on steroids ?? in a way.
Here's how you read a CSV file as a pandas Dataframe by passing the file path to the read_csv() function.
#it's a convention to import pandas as 'pd'
import pandas as pd
#read a dataset on pokemon stats
pokemon_stats = pd.read_csv("pokemon_stats.csv")
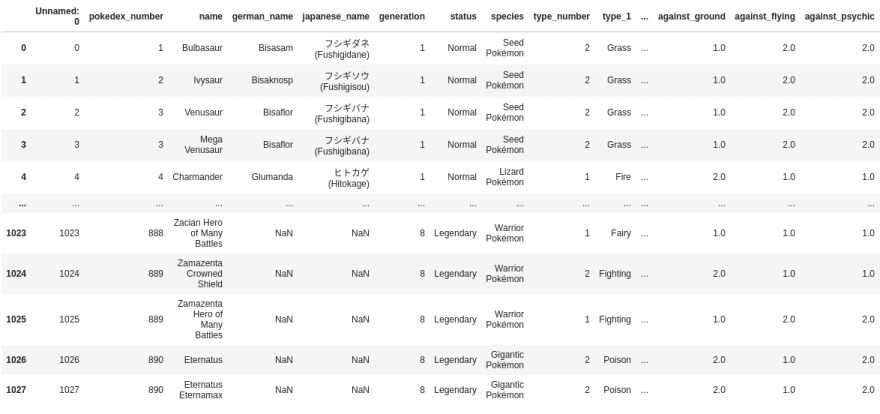
pokemon_stats #since it's jupyternotebook, no need of print
 ? The file path can be relative or absolute.
? The file path can be relative or absolute.
You will see a table of this sort in your jupyter notebook. (Not all the rows(1028) and columns(51) so that your entire screen is not occupied!)
There's also a read_excel() function if your dataset is in excel spreadsheet form.
#read excel file as a dataframe
df = pd.read_excel("path/to/my_dataset.xlsx")
?️ whenever I say df, I am referring to Dataframe.
Displaying first and last few rows
It is a common practice to have a quick glance at some rows from beginning or end.
For this, we have df.head(n=5) and df.tail(n=5) methods where n is number of rows to display and its default value is 5.
#display first four rows
pokemon_stats.head(4)

#display last four rows
pokemon_stats.tail(4)

We'll go into the anatomy of Dataframe in the next post. You will get to know that it's more than just a table. Until then, enjoy data science!
Bonus: Where Pandas shine ?
It is useful whenever the data is structured - data stored in CSV files, excel files, database tables, or simply whenever there is a notion of rows and columns.
⚠️ There was a bit of jargon involved in the explanations but don't worry we are going to visit these concepts again and again in forthcoming posts :)
This content originally appeared on DEV Community and was authored by Kathan Vakharia
Kathan Vakharia | Sciencx (2021-06-17T23:56:39+00:00) Pandas Concepts: Introduction. Retrieved from https://www.scien.cx/2021/06/17/pandas-concepts-introduction/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.