
This content originally appeared on Level Up Coding - Medium and was authored by Trung Anh Dang
The High-Performance Series
Think Big, Do Small, Learn Fast
In order to keep up with emerging techniques, I would like to update you on this story throughout the year.
Last updated on 2021 Jun 28

It is not easy to design a system that supports hundreds of millions of users. It always is a big challenge for a software architect (but it’ll be easy from today after reading my article ?)
Here are some topics covered by me in this article.
- Start with simplest: all in one.
- The art of scability: scaling out, scaling up.
- Scaling a relational database: master-slave replication, master-master replication, federation, sharding, denormalization, and SQL tuning.
- Which database to use: NoSQL or SQL?
- Advanced concepts: caching, CDN, geoDNS., etc.
Today I don’t want to discuss general terms in high-performance computing such as fault tolerance, reliability, high availability., etc.
Keep calm, let’s start now!
Start from scratch
In the figure below, I would like to start by designing a basic app with some users. The simplest way is to deploy the entire app on a single server. This is probably how most of us get started.
- A website (include APIs) is running on a webserver like Apache¹ (or Tomcat²).
- A database like Oracle³ (or MySQL⁴).
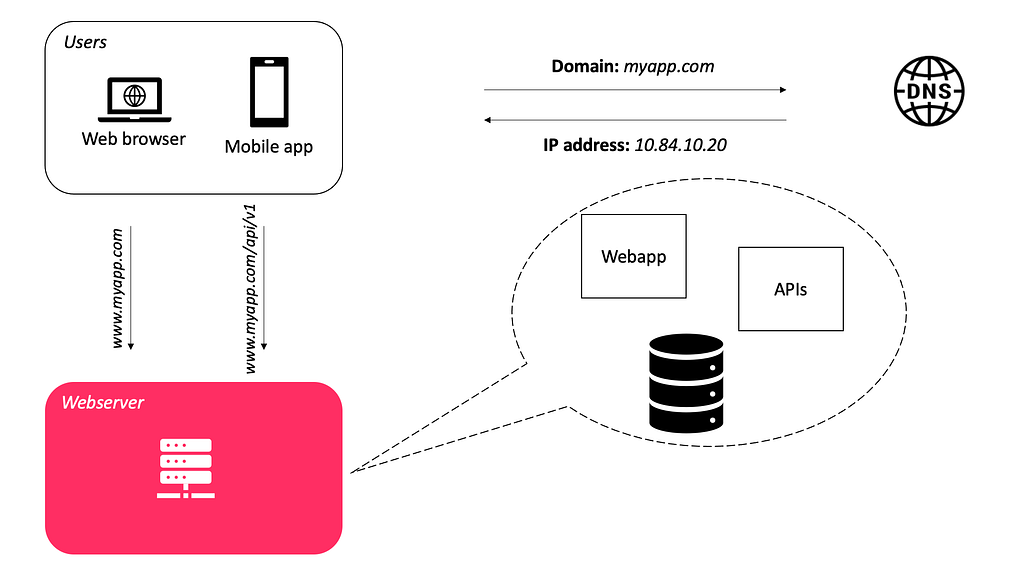
But there are the following disadvantages with the current architecture.
- If the database fails, the system fails.
- If the webserver fails, the entire system fails.
- Scaling a relational database.
- Advanced topics
In this case, we don’t have failover and redundancy. If a server goes down, all goes down.
Using a DNS server to resolve hostnames and IP addresses
In the above figure, users (or clients) connect to the DNS⁵ system to obtain the Internet Protocol (IP) address of the server where our system is hosted. Once the IP address is obtained, the requests are sent directly to our system.
Every time you visit a website, your computer performs a DNS lookup.
Usually, the Domain Name System (DNS) server is used as a paid service provided by the hosting company and is not running on your own server.
The Art of Scalability
Our system may have to scale because of many reasons like increased data volume, increased amount of work (e.g., number of transactions), and grown users.
Scalability usually means an ability to handle more users, clients, data, transactions, or requests without affecting the user experience by adding more resources.
We must decide how to scale the system. In this case, there are the following two types of scaling: scale-up and scale-out.

Scaling up: add more RAM and CPU to the existing server
This is also called “vertical scaling”, it refers to the resource maximization of a system to expand its ability to handle the increasing load — for example, we increase more power to our server by adding RAM and CPU.
If we are running the server with 8GB of memory, it is easy to upgrade to 32GB or even 128GB by just replacing or adding the hardware.
There are many ways to scale vertically as follows.
- Adding more I/O capacity by adding more hard drives in RAID arrays.
- Improving I/O access times by switch to solid-state drivers (SSDs).
- Switching to a server with more processors.
- Improving network throughput by upgrading network interfaces or installing additional ones.
- Reducing I/O operations by increasing RAM.
Vertical scaling is a good option for small systems and can afford the hardware upgrade but it also comes with serious limitations as follows.
- “It’s impossible to add unlimited power to a single server”. It mostly depends on the operating system and the memory bus width of the server.
- When we upgrade RAM to the system, we must shut down the server and so, if the system just has one server, downtime is unavoidable.
- Powerful machines usually cost a lot more than popular hardware.
Scaling up not only applies to hardware terms but also in software terms, for example, it includes optimizing queries and application code.
Do you need more than one server?
With the growth of the number of users, one server is never enough. We need to think about separating out a single server to multiple servers.

With this architecture, there are some advantages as follows.
- The webserver can be tuned differently than the database server.
- A web server needs a better CPU and a database server thrives on more RAM.
- Using separate servers for the web tier and data tier allows them to scale independently of each other.
Scaling out: add any number of hardware and software entities
It also described as “horizontal scaling”, we add more entities (machines, services) to our pool of resources. It’s harder to achieve horizontal scaling than vertical scaling since we need to consider it before the system is built.
Horizontal scaling often initially costs more because we need more servers for the most basic but it pays off at the later stage. We need to do trade-offs.
- Increasing the number of servers means that more resources need to be maintained.
- The code of the system also needs changes to allow parallelism and distribution of work among multiple servers.
Using load a balancer to balance the traffic across all nodes
A load balancer is a specialized hardware or software component that helps to spread the traffic across a cluster of servers to improve responsiveness and availability of the system (include but not limited to applications, websites, or databases).

Typically a load balancer sits between the client and the server accepting incoming network and application traffic and distributing the traffic across multiple backend servers using various algorithms. So, it can also be used in various places, for example; between the Web Servers and the Database servers and also between the Client and the Web Servers.
HAProxy and NGINX are two popular open-source load balancing software.
The load balancer technique is a fault tolerance assurance methodology and improves availability as follows.
- If server 1 goes offline, all the traffic will be routed to server 2 and server 3. The website won’t go offline. You also need to add a new healthy server to the server pool to balance the load.
- When the traffic is growing rapidly, you only need to add more servers to the web server pool and the load balancer will route the traffic for you.
Load balancers employ various policies and work distribution algorithms to optimally distribute the load as follows.
- Round robin: in this case, each server receives requests in sequential order similar in spirit to First In First Out (FIFO).
- Least number of connections: the server with the lowest number of connections will be directed to the request.
- Fastest response time: the server that has the fastest response time (either recently or frequently) will be directed to the request.
- Weighted: the more powerful servers will receive more requests than the weaker ones underweighted strategy.
- IP Hash: in this case, a hash of the IP address of the client is calculated to redirect the request to a server.
The most straightforward way to balance requests between multiple servers is to use a hardware appliance.
- Adding and removing real servers from shared IP happens instantly.
- Load balancing can be done as desired.
Software load balancing is a cheap alternative to hardware load balancers. It operates at layer 4 (network layer) and layer 7 (application layer).
- Layer 4: the load balancer uses the information provided by TCP at the network layer. At this layer, it usually selects a server without looking at the content of the request.
- Layer 7: the requests can be balanced based on information in the query string, cookies, or any header we choose as well as the regular layer information including source and destination addresses.
Scaling a relational database
With a simple system, we can use an RDBMS like Oracle or MySQL to save data items. But relational database systems come with their challenges, especially when we need to scale them.
There are many techniques to scale a relational database: master-slave replication, master-master replication, federation, sharding, denormalization, and SQL tuning.
- Replication usually refers to a technique that allows us to have multiple copies of the same data stored on different machines.
- Federation (or functional partitioning) splits up databases by function.
- Sharding is a database architecture pattern related to partitioning by putting different parts of the data onto different servers and the different user will access different parts of the dataset
- Denormalization attempts to improve read performance at the expense of some write performance by coping of the data are written in multiple tables to avoid expensive joins..
- SQL tunning.
Master-slave replication
The master-slave replication technique enables data from one database server (the master) to be replicated to one or more other database servers (the slaves) like in the below figure.
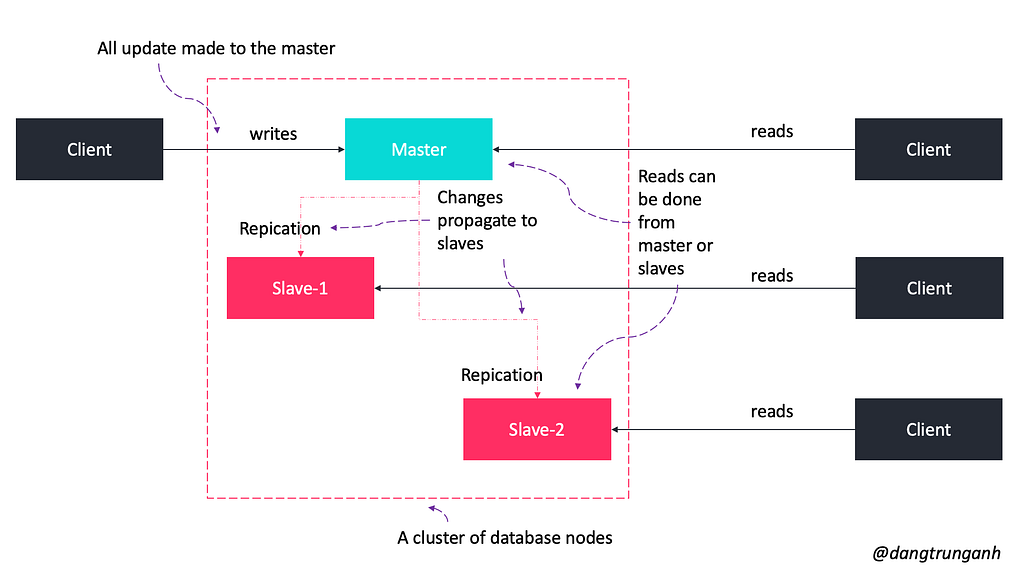
- A client would connect to the master and update data.
- The data would then ripple through the slaves until all of the data is consistent across the servers.
In practice, there is still a bit of a bottleneck here.
- If the master server goes down for whatever reason, the data will still be available via the slave, but new writes won’t be possible.
- We need an additional algorithm to promote a slave to a master.
Here are some solutions to implement only one server can handle update requests.
- Synchronous solutions: the data modifying transaction is not committed until accepted by all servers (distributed transaction), so no data lost on failover.
- Asynchronous solutions: commit -> delay -> propagation to other servers in the cluster, so some data updates may be lost on failover.
Keep in mind that if synchronous solutions are too slow, change to asynchronous solutions.
Master-master replication
Each database server can act as the master at the same time as other servers are being treated as masters. At some point in time, all of the masters sync up to make sure that they all have correct and up-to-date data.
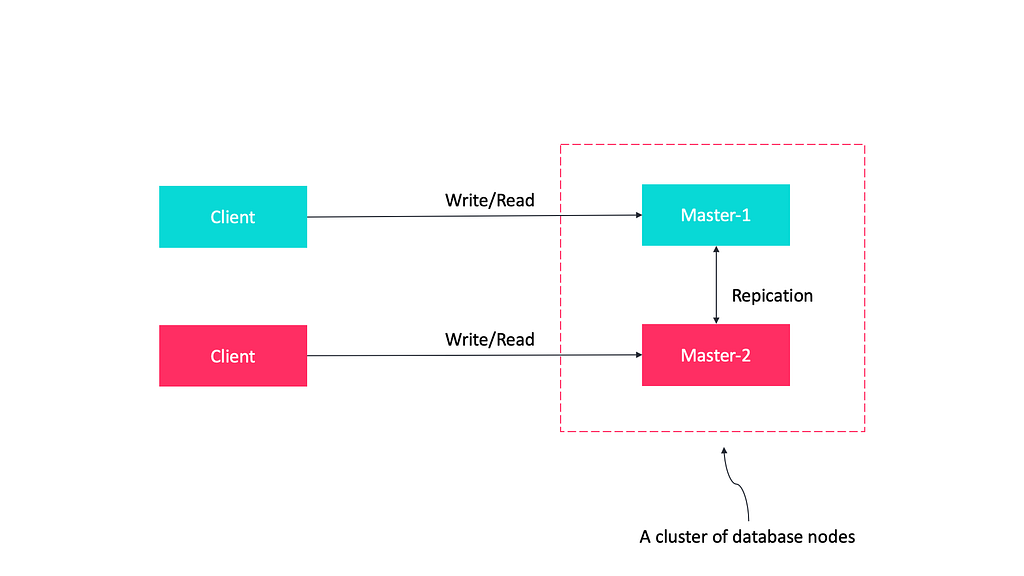
Here are some advantages of master-master replication.
- If one master fails, the other database servers can operate normally and pick up the slack. When the database server is back online, it will catch up using replication.
- Masters can be located in several physical sites and can be distributed across the network.
- Limited by the ability of the master to process updates.
Federation
Federation (or functional partitioning) splits up databases by function. For example, instead of a single, monolithic database, you could have three databases: forums, users, and products, resulting in less read and write traffic to each database and therefore less replication lag.

Smaller databases result in more data that can fit in memory, which in turn results in more cache hits due to improved cache locality. With no single central master serializing writes you can write in parallel, increasing throughput.
Sharding
Sharding (also known as data partitioning), is a technique to break up a big database into many smaller parts such that each database can only manage a subset of the data.
In the ideal case, we have different users all talking to different database nodes. It helps to improve the manageability, performance, availability, and load balancing of a system.
- Each user only has to talk to one server, so gets rapid responses from that server.
- The load is balanced out nicely between servers — for example, if we have five servers, each one only has to handle 20% of the load.
In practice, there are many different techniques to break up a database into multiple smaller parts.
Horizontal partitioning
In this technique, we put different rows into different tables. For example, if we are storing profiles of users in a table, we can decide that users with IDs less than 1000 are stored in one table, and users with IDs greater than 1001 and less than 2000 are stored in the another

Vertical partitioning
In this case, we divide our data to store tables related to a specific feature in their own server. For example, if we are building an Instagram-like system — where we need to store data related to users, photos they upload, and people they follow — we can decide to place user profile information on one DB server, friend lists on another, and photos on a third server.

Directory based partitioning
A loosely coupled approach to this problem is to create a lookup service that knows your current partitioning schema and keeps a map of each entity and which database shard it is stored on.
We can use this method when a data store is likely to need to scale beyond the resources available to a single storage node or to improve performance by reducing contention in a data store. But keep in mind that there are some common problems with Sharding techniques as follows.
- Database joins become more expensive and not feasible in certain cases.
- Sharding can compromise database referential integrity.
- Database schema changes can become extremely expensive.
- The data distribution is not uniform and there is a lot of load on a shard.
Denormalization
Denormalization attempts to improve read performance at the expense of some write performance. Redundant copies of the data are written in multiple tables to avoid expensive joins.
Once data becomes distributed with techniques such as federation and sharding, managing joins across data centers further increases complexity. Denormalization might circumvent the need for such complex joins.
In most systems, reads can heavily outnumber writes 100:1 or even 1000:1. A read resulting in a complex database join can be very expensive, spending a significant amount of time on disk operations.
Some RDBMS such as PostgreSQL and Oracle support materialized views which handle the work of storing redundant information and keeping redundant copies consistent.
Facebook’s Ryan Mack shares quite a bit of Timeline’s own implementation story in his excellent article: Building Timeline: Scaling up to hold your life story⁶ by using the power of Denormalization.
Which database to use?
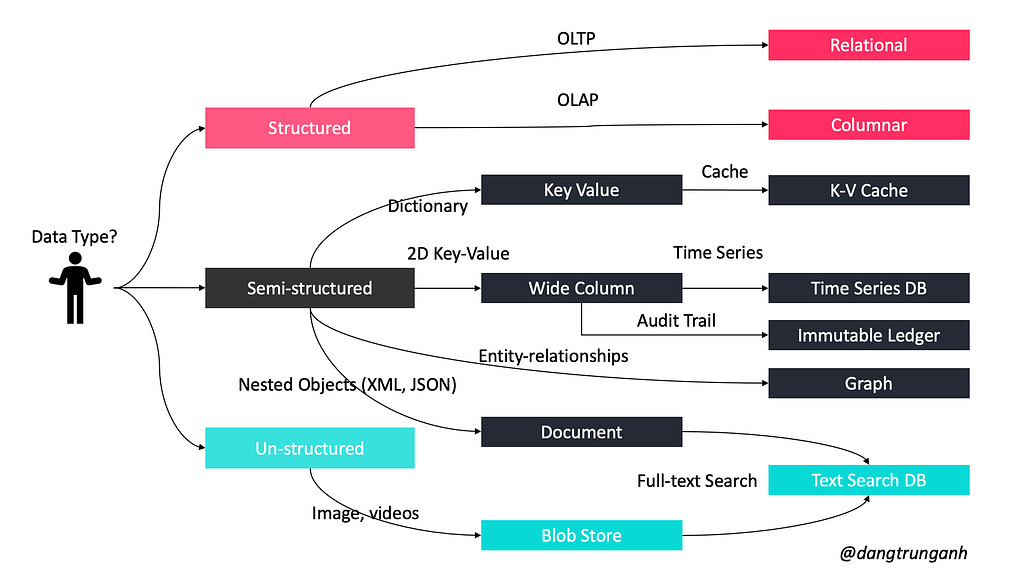
In the world of databases, there are two main types of solutions: SQL and NoSQL. Both of them differ in the way they were built, the kind of information they store, and the storage method they use.
SQL
Relational databases store data in rows and columns. Each row contains all the information about one entity and each column contains all the separate data points.
Some of the most popular relational databases are MySQL, Oracle, MS SQL Server, SQLite, Postgres, and MariaDB.
NoSQL
It also called non-relational databases. These databases are usually grouped into main five categories: Key-Value, Graph, Column, Document, and Blob stores.
Key-Value stores
Data is stored in an array of key-value pairs. The ‘key’ is an attribute name that is linked to a ‘value’.
Well-known key-value stores include Redis, Voldemort, and Dynamo.
Document databases
In these databases, data is stored in documents (instead of rows and columns in a table) and these documents are grouped together in collections. Each document can have an entirely different structure.
Document databases include the CouchDB and MongoDB.
Wide-column databases
Instead of ‘tables,’ in columnar databases we have column families, which are containers for rows. Unlike relational databases, we don’t need to know all the columns upfront and each row doesn’t have to have the same number of columns.
Columnar databases are best suited for analyzing large datasets, big names include Cassandra and HBase.
Graph databases
These databases are used to store data whose relations are best represented in a graph. Data is saved in graph structures with nodes (entities), properties (information about the entities), and lines (connections between the entities).
Examples of graph databases include Neo4J and InfiniteGraph.
Blob databases
Blobs are more like a key/value store for files and are accessed through APIs like Amazon S3, Windows Azure Blob Storage, Google Cloud Storage, Rackspace Cloud Files, or OpenStack Swift.
How to choose which database to use?
When it comes to database technology, there’s no one-size-fits-all solution. That’s why many businesses rely on both SQL and NosQL databases for different needs.
Look at my below guidance!
Scaling the web tier horizontally
We have scaled the data tier, now we need to scale the web tier too. To make this, we need to move the data of user sessions (states) out of the web tier by storing them in a database such as the relational database or NoSQL. It also called stateless architecture.
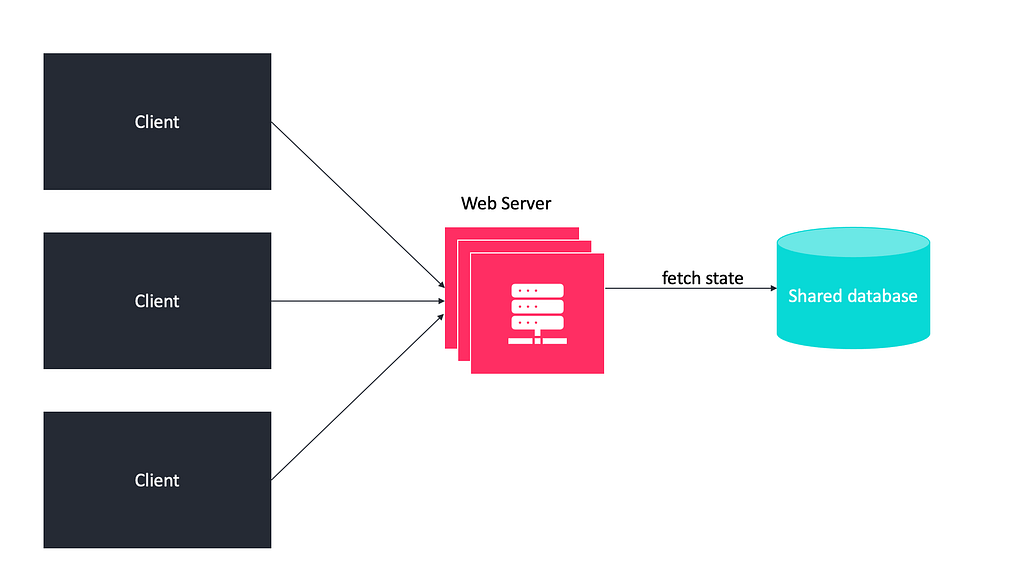
Don't use stateful architecture.
We must choose stateless architecture whenever possible because the implementation of state limits scalability, decreases availability, and increase the cost.
In the above scenario, the load balancer can achieve maximum efficiency because it can select any server for optimal request handling.
Advanced Concepts
Caching
Load balancing helps you scale horizontally across an ever-increasing number of servers, but caching will enable you to make vastly better use of the resources you already have, so that the data may be served faster during subsequent requests.

By adding caches to our servers, we can avoid reading the webpage or data directly from the server, thus reducing both the response time and the load on our server. This helps in making our application more scalable.
Caching can be applied at many layers such as the database layer, web server layer, and network layer.
Content Delivery Network (CDN)
The CDN servers keep cached copies of the content (such as images, web pages, etc.) and serve them from the nearest location.
The use of CDN improves page load time for users as the data is retrieved at a location closest to it. This also helps in increasing the availability of content, since it is stored at multiple locations.

The CDN servers make requests to our Web server to validate the content being cached and update them if required. The content being cached is usually static such as HTML pages, images, JavaScript files, CSS files, etc.
Go Global
When your app goes global, you will own and operating data centers around the world to keep your products running 24 hours a day, 7 days a week. Incoming requests are routed to the “best” data center based on GeoDNS.

GeoDNS is a DNS service that allows domain names to be resolved to IP addresses based on the location of the customer. A client connecting from Asia may get a different IP address than the client connecting from Europe.
Putting it all together
Applying all these techniques iteratively, we can easily scale the system to more than 100 million users such as stateless architecture, apply load balancer, use cache data as much as you can, support multiple data centers, host static assets on CDN, scale your data tier by sharding., etc.

Which topics will be discussed later?
There are many ways to improve scalability and high performance as follows.
- Combining Sharding and Replication techniques.
- Long-polling vs Websockets vs Server sent events.
- Indexes and Proxies.
- SQL Tunning.
Easy, right?
References
[3] https://www.oracle.com/database/
[5] https://en.wikipedia.org/wiki/Domain_Name_System
[6] https://www.facebook.com/note.php?note_id=10150468255628920
How to design a system to scale to your first 100 million users was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Trung Anh Dang
Trung Anh Dang | Sciencx (2021-06-27T18:22:29+00:00) How to design a system to scale to your first 100 million users. Retrieved from https://www.scien.cx/2021/06/27/how-to-design-a-system-to-scale-to-your-first-100-million-users/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.