
This content originally appeared on DEV Community and was authored by Supratip Banerjee
Storage fundamentals
Amazon S3 is storage for the Internet that makes web-scale computing easier for developers and users alike. Amazon S3 is an object storage platform that allows you to store and retrieve any amount of data, at any time, from anywhere on the web. If you are new to storage, you may not be aware that there are different types of storage.
Amazon S3 is an object storage-based service. However, to better understand object storage and how it differs from the other storage types, take a moment to review the underlying differences between storage types.

Block storage
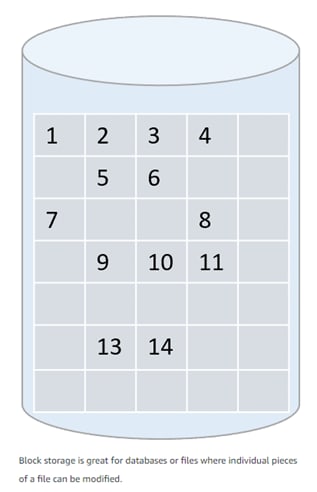
A block is a range of bytes or bits on a storage device. Block storage files, are divided into blocks and written directly to empty blocks on a physical drive. Each block is assigned a unique identifier and then written to the disk in the most efficient manner possible. Since blocks are assigned identifiers, they do not need to be stored in adjacent sections of the disk. Indeed they can be spread across multiple disks or environments. You can retrieve the individual blocks separately from the rest of the file, which makes block storage excellent for technology like relational databases.
With relational databases, you might only need to retrieve a single piece of a file, such as an inventory tracking number, or one specific employee ID, rather than retrieving the entire inventory listing or whole employee repository.
File Storage
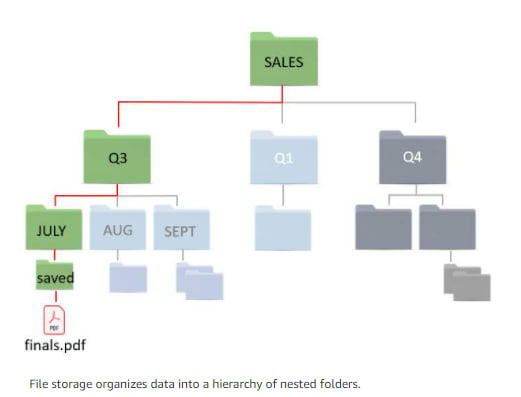
Historically, operating systems save data in hierarchical file systems organized in the form of directories, sub-directories and files, or folders, sub-folders, and files depending on the operating system.
For example, if you are troubleshooting an issue on a Linux distribution, you may need to look in /var/log or /etc/config. Once inside of these directories, you need to identify which file to explore and open. When using a file-based system, you must know the exact path and location of the files you need to work with or have a way to search the entire structure to find the file you need.
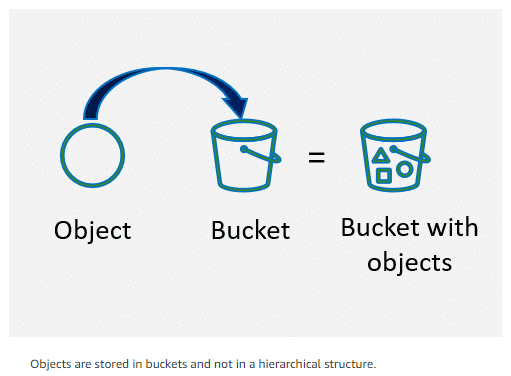
Object Storage
Unlike the hierarchical structure used in file-based storage, object storage is a flat structure where the data, called an object, is located in a single repository known as a bucket. Object can be organized to imitate a hierarchy by attaching key name prefixes and delimiters. Prefixes and delimiters allow you to group similar items to help visually organize and easily retrieve your data. In the user interface, these prefixes give the appearance of a folder and subfolder structure but in reality, the storage is still a flat structure.
Amazon S3 fundamentals
Amazon S3 is an object storage service that offers industry-leading scalability, data availability, security, and performance. It is intentionally built with a minimal feature set that focuses on simplicity and robustness. You have access to the same highly scalable, reliable, fast, inexpensive data storage infrastructure that Amazon uses to run its own global network of web sites. The service aims to maximize benefits of scale and to pass those benefits on to the you, the customer.
This content originally appeared on DEV Community and was authored by Supratip Banerjee
Supratip Banerjee | Sciencx (2021-07-18T06:15:59+00:00) Amazon S3 Deep Dive (part 1-storage fundamentals). Retrieved from https://www.scien.cx/2021/07/18/amazon-s3-deep-dive-part-1-storage-fundamentals/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.