
This content originally appeared on DEV Community and was authored by Elegberun Olugbenga
Cover Photo by Javier Miranda on Unsplash
Databases are one of those abstract, mysterious things that "just work" when you run an insert statement, where's the data stored?. How is it stored? Why are queries so fast? What's underneath the black box of a database? Sometimes it all just feels like magic.
It's 1 am in Lagos and I can't sleep. I pick up my phone and head to Google to help me demystify this black box. The next words you read are my attempt to unbox a database.
My focus on this article will be on SQL databases but I believe the underlying concepts can be passed to other types of databases. Before we go on let us define some terms.
Database
A database is a set of physical files(data) on a hard disk stored and accessed electronically from a computer system. Usually created by the CREATE DATABASE statement.
Database management system
A database management system is software that handles the storage, retrieval, and updating of data in a computer system.

Database engine
A database engine is the underlying software component that a database management system uses to create, read, update and delete data from a database.
What is the difference between a database management system and a database engine?
The database management system is the software with its functions that allow us to connect to a database engine. The database engines are the internal tools that allow or facilitate a certain number of operations on the tables and their data.
How does a database management system store data?
Most database management systems store data in files. MySQL for example stores data in files in a specific directory that has the system variable "datadir". Opening a MySQL console and running the following command will tell you exactly where the folder is located.
mysql> SHOW VARIABLES LIKE 'datadir';
+---------------+-----------------+
| Variable_name | Value |
+---------------+-----------------+
| datadir | /var/lib/mysql/ |
+---------------+-----------------+
1 row in set (0.01 sec)
This stack overflow answer explains it really well.
As you can see from the above command, my "datadir" was located in /var/lib/mysql/. The location of the "datadir" may vary in different systems. The directory contains folders and some configuration files. Each folder represents a MySQL database and contains files with data for that specific database, below is a screenshot of the "datadir" directory in my system.
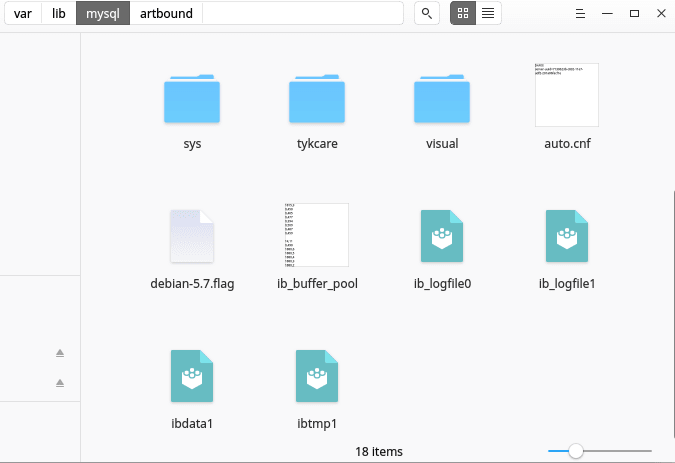
Each folder in the directory represents a MySQL database. Each database folder contains files that represent the tables in that database. There are two files for each table, one with a .frm extension and the other with a .idb extension. See the screenshot below.

- The .frm table file stores the table's format. Details: MySQL .frm File Format
- The .ibd file stores the table's data. Details: InnoDB File-Per-Table Tablespaces
When we insert a record into a table we are actually inserting into a datafile. A page (representing the rows of the table)is created in that datafile. By default, all datafiles have a page size of 16KB, you can reduce or increase the page size depending on the database engine you are using.
As more and more records are inserted into the table(datafile) several data pages are created.
How Pages Relate to Table Rows
The maximum row length is slightly less than half a database page. For example, the maximum row length is slightly less than 8KB for the default 16KB InnoDB page size. For 64KB pages, the maximum row length is slightly less than 16KB.
If a row does not exceed the maximum row length, all of its data is stored locally within the page. If a row exceeds the maximum row length the database engine stores a 20-byte pointer to the next page locally in the row, and stores the remaining rows externally in overflow pages.
These two articles do a wonderful job of describing how data pages look in sql server.
Let us assume we have a table(tblEmployees) and we insert a single record into it.
INSERT INTO tblEmployees VALUES (1,'Abhishek')
This is a sample data page of that insertion into the datafile. It is divided into 3 main sections
Section 1:Page Header
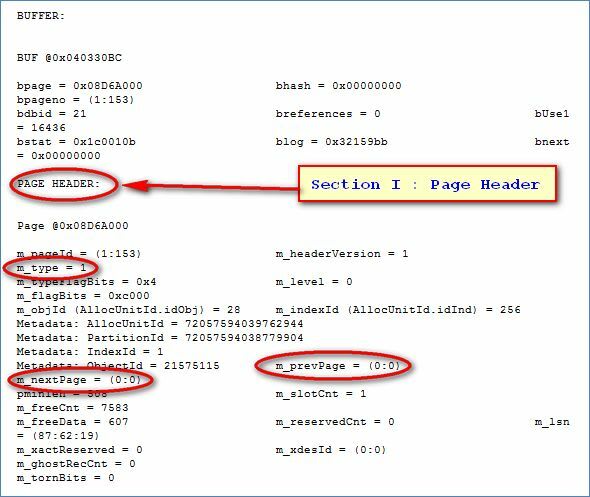
- m_type =1 indicates that it is a data page.
- m_nextpage: This is the link to the memory location of the next data page that will be created, in this case, we have a single data page so it is(0:0).
- m_Prevpage: This is the link to the memory location of the previous data page. Since we have a single data page the value is(0:0).
Section 2:Actual Data
The actual data that we insert into our table is stored in this section. If you remember, we inserted 1 record with an employee named "Abhishek". That record will be saved here, in this section as shown below.

- Record Type = PRIMARY_RECORD, which means it's our actual data.
- Memory Dump = This points to the Actual data's location in memory.
Section 3:Offset Table
Offset Table: This section of the data file tells you where the record Abhishek is saved exactly in memory.
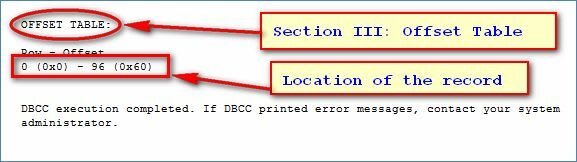
If you see the row offset, it's pointing to the actual data's location.
These diagrams show how rows are stored in a datafile.
How does indexing work?
A database index is a data structure that improves the speed of data retrieval operations on a database table.
Indexing is the way to get an unordered table into an order that will maximize the query efficiency. A Clustered Index is a special type of index that reorders the way records in the table are physically stored on the disk. So how does it work?
In reality, the database table does not reorder itself every time the query conditions change to optimize the query performance, what happens is that when you create an index you cause the database to create a data structure which in most cases is likely to be a B+Tree. The main advantage of this data structure is that it is sortable and this makes our search more efficient.
A B+Tree is a type of dictionary, no more and no less. If you think about a linguistic dictionary, it's ordered by "words", and associated with each word is a definition. You look up a word and get a definition.

So the context of a map data structure is that you have keys ("words") and you want to map this to values ("definitions").
B+trees have an advantage for certain types of queries. For example, you can do range queries, say if you want to find all entries where the key is between two values (e.g. all words in the dictionary starting with "q").
B+trees are page-structured (meaning they can be implemented on top of fixed-size disk pages; which minimizes the number of disk accesses needed to perform a query.
Example
Let us assume we have a table called Employee_Detail. We can create a clustered index with the following command on the Emp_Iid column.
Create Clustered Index My_ClusteredIndex
on Employee_Detail(Emp_Iid)
Now let's insert some records
- Head over to this site and insert records from 1 to 6 simulating how records will be inserted in a database. You will see how the tree automatically adjusts as records are being inserted.
Another thing to note the data value locations never change but the (pointers to those values are the ones that are constantly shifting).
The B+Tree will be formed like this. - The center point of the records which in our case is 3 will be the head node. All the Ids that are lower than 3 will be moved to the left and the Ids greater than 3 to the right as shown in this diagram.
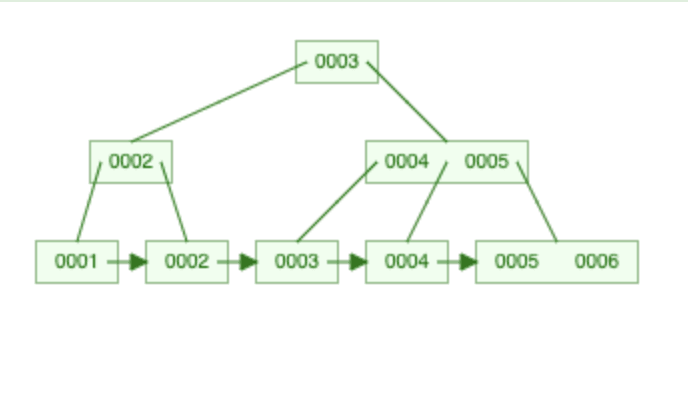
The left side value of each node is always less than the node itself and the right-side value is always greater than the node. The last set of values are called leaf nodes and they contain the actual data value while the intermediate rows hold pointers to the actual data value location.
Think of it like a dictionary that contains a name tag. All the words with "c" are labeled under the "c" tag. words higher than "c" are shifted to the right and words lower than "c" to the left. The tag "c" does not contain the value but a (pointer) to the actual words.
From the earlier explanation on how SQL stores data in data pages we can infer that the leaf nodes represent data pages containing the table rows.
If we want to get the employees where Emp_Iid is 4.
select * from employee_Detail where Emp_Iid=4
In a normal case, the system will perform 4 comparisons, the first for 1, the second for 2, and the third for 3 and in the fourth comparison, it will find the desired result.
Using an index, the system only does a single comparison because 3 is the head node of the B+Tree and it knows that 4 is greater than 3 so the record will be on the right. Once it checks the next key It will find a pointer to the data value 4 which is the value that is being requested.
From this example, we can say that by using an index we can increase the speed of data retrieval.
Components of a Database Engine

All SQL database engines have a compiler to translate the SQL statement into byte code and a virtual machine to evaluate the byte code.
The RDBMS processes the SQL statement by:
1.Parsing: Validates the statement by checking the SQL statement against the system’s catalog and seeing if these databases, tables, and columns that the user wants exist, and if the user has privileges to execute the SQL query.
Under the parsing stage, there is a syntax check, semantic check, and shared pool check.
Syntax check
A statement that breaks a rule for well-formed SQL syntax fails the check. For example, the following statement fails because the keyword FROM is misspelled as FORM:
SQL> SELECT * FORM employees;
SELECT * FORM employees
*
ERROR at line 1:
ORA-00923: FROM keyword not found where expected
Semantic Check
The semantics of a statement is its meaning. A semantic check determines whether a statement is meaningful, for example, whether the objects and columns in the statement exist.
SQL> SELECT * FROM nonexistent_table;
SELECT * FROM nonexistent_table
*
ERROR at line 1:
ORA-00942: table or view does not exist
Shared Pool Check
During the parse, the database performs a shared pool check to determine whether it can skip resource-intensive steps of statement processing.
To this end, the database uses a hashing algorithm to generate a hash value for every SQL statement.
2.Compiling (Binding): Generates a query plan for the statement which is the binary representation of the steps required to carry out the statement. In almost all SQL engines, it will be byte code. What has now been compiled is a command-line shell — a program that reads SQL statements and now sends them to the database server for optimization and execution.
3.Optimizing: Optimizes the query plan and chooses the best algorithms such as for searching and sorting. This feature is called the Query Optimizer. The Query Optimizer devises several possible ways to execute the query i.e. several possible execution plans. An execution plan is, in essence, a set of physical operations (an index seek, a nested loop join, and so on) to be performed.
Once this is done, we now have a prepared SQL statement.
Example
This example shows the execution plan of a SELECT statement when AUTOTRACE is enabled. The statement selects the last name, job title, and department name for all employees whose last names begin with the letter A.
SELECT e.last_name, j.job_title, d.department_name
FROM hr.employees e, hr.departments d, hr.jobs j
WHERE e.department_id = d.department_id
AND e.job_id = j.job_id
AND e.last_name LIKE 'A%';
Execution Plan
----------------------------------------------------------
Plan hash value: 975837011
--------------------------------------------------------------------------------
| Id| Operation | Name |Rows|Bytes|Cost(%CPU)|Time |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3 | 189 | 7(15)| 00:00:01 |
|*1 | HASH JOIN | | 3 | 189 | 7(15)| 00:00:01 |
|*2 | HASH JOIN | | 3 | 141 | 5(20)| 00:00:01 |
| 3 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 3 | 60 | 2 (0)| 00:00:01 |
|*4 | INDEX RANGE SCAN | EMP_NAME_IX | 3 | | 1 (0)| 00:00:01 |
| 5 | TABLE ACCESS FULL | JOBS | 19 | 513 | 2 (0)| 00:00:01 |
| 6 | TABLE ACCESS FULL | DEPARTMENTS | 27 | 432 | 2 (0)| 00:00:01 |
-------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
--------------------------------------------------------
1 - access("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")
2 - access("E"."JOB_ID"="J"."JOB_ID")
4 - access("E"."LAST_NAME" LIKE 'A%')
filter("E"."LAST_NAME" LIKE 'A%')
4.Executing: The RDBMS executes the SQL statement by running the query plan.
For an in-depth view, check out this tutorial
Summary
This article has covered a lot of ground, but by now you should have an understanding (or at least an appreciation) of the components and processes that form the databases we use every day.
Thank you for reading.
Follow me here and across my social media for more content like this Linkedin. Twitter
REFERENCES AND MORE
1.How a sql database engine works by Andres reyes
2.How a sql database engine works by Dennis Pham
3.The sql server query optimizer by Benjamin Nevarez
4.An in-depth look at Database Indexing by Kousik Nath
5.Database btree indexing in sqlite by Dhanushka Madushan
6.Inside the storage engine by Paul Randal
7.B-tree and how it is used in practice answered by Pseudonym
8.Index in sql by Pankaj Kumar Choudhary
9.How sql server stores data in data pages part 1 by Abhishek Yadav
10.How sql server stores data in data pages part 2 by Abhishek Yadav
12.How does a sql query work by
13.How sql database engine works by Vijay Singh Khatri
This content originally appeared on DEV Community and was authored by Elegberun Olugbenga
Elegberun Olugbenga | Sciencx (2021-07-30T15:23:53+00:00) Unboxing a Database-How Databases Work Internally. Retrieved from https://www.scien.cx/2021/07/30/unboxing-a-database-how-databases-work-internally/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.