
This content originally appeared on DEV Community and was authored by Arif Amirani
Introduction
I've been working with large NGOs to architect their multi-faceted systems. These systems are responsible for information dissemination, data collection, analysis, and sources & sinks to other systems. Our near term goal was to build an information platform (IP). The MDP was narrowed down to the following feature set.
Target persona
The IP was intended for 3 main personas.
- Villagers
- Direct consumers
- Low tech capability
- Language barriers
- Varied devices - sizes and capabilities
- Irregular bandwidth
- Ops team
- Responsible for training using the content
- Submitting feedback for content from users
- Updates to content (limited)
- Content team
- Primarily responsible for content
- Regular content updates
Requirements
Media support
The portal has to support different media types which includes but not limited to; video, digital books, images, audio (podcast). The content is generated by a marketing and education team which is then uploaded to a public repository for downloads. All content is in the public domain.
Multilingual and region support
The content itself is versatile. The information and instructions change based on the local language, diet, and availability of resources. The portal has to support reuse of content as well as specific content for a particular region. Ease of management of the portal data by the content team was paramount.
Interval based updates
The content team updates the data several times a day. However there was no need to do real-time updates. New content can show up within the hour.
Analytics
Measurement is core to any successful deployment, especially for large and diverse ones. We factored in the need of granular measurement for clicks, bounces, playback, skips right from day one.
3rd Party API
The content for the portal has to be made available to 3rd party applications for their internal consumption. The interesting part here is that the content over the API is the same as the website, however the 3rd party applications must be throttled to avoid proxy or overuse of our endpoint.
Final Architecture
Apart from the requirements above, we also were tasked to ensure cost-effectiveness along with speed of delivery. The obvious choice was a typical three tier architecture that would achieve most of the objectives. The team also had the right experience. However I decided to go a different route. In the recent past I had deployed a JSON based architecture that had scaled well with up to 20 million visitors but nowhere close to the complexity.
I made a few changes and architected the solution loosely on CQRS - Command Query Responsibility Segregation pattern. All the data that was needed to be displayed (read path) were based on JSON files that were continously refreshed via a fleet of Lambda functions. On the other hand the write path were served by API Gateway (HTTP).
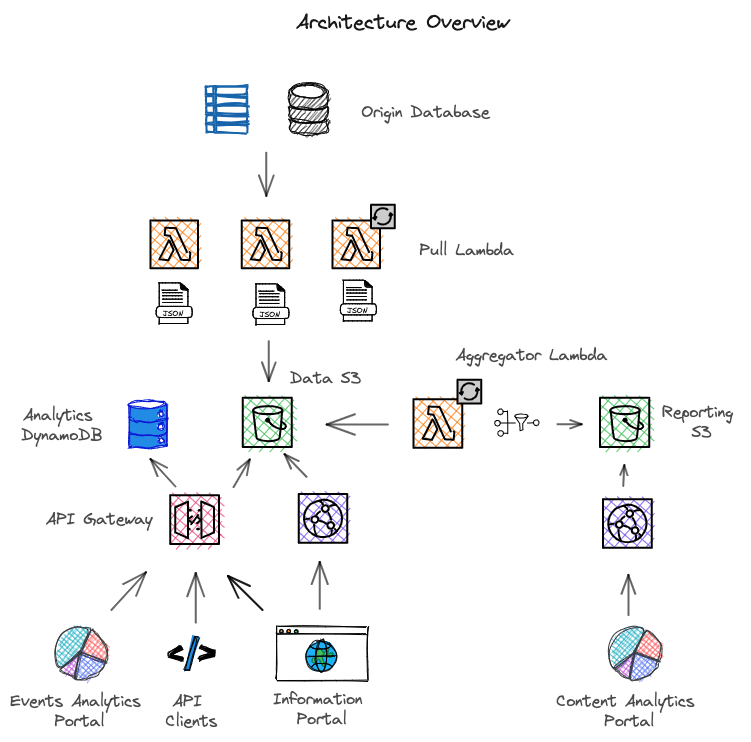
Origin Database
These are the primary sources of information. They can be a Google Sheet, Airtable, RDBMS data sources. They provide the actual content metadata and rules of transformation.
Pull Lambda Fleet
PLF run either on a reactive or schedule basis. They fetch data from the data sources and merge them based on rules. The output is split based on language, region, content, and use case. They generate JSON files at the end of the process and upload them to an S3 bucket using a convention that the webapp can understand.
Information Portal (IP)
Built on React and Tailwind CSS, the IP delivers the content to users. It is a lightweight, responsive PWA. Can work with limited bandwidth and works across all device display sizes. Once it loads, it pulls the appropriate JSON from the server via CloudFront, depending on the region and language setting. All UI actions such as filtering, and search are done on the client side. The size of each JSON is manageable and uses aggressive compression to deliver data quickly. The auto reload mechanism in React (ReactSWR), ensures that the client refetches the JSON every 15 mins or on reload of page.
API Clients
For the content 3rd party API, we use the main API Gateway (APIGW). Using the APIGW method, we can connect directly the GET method to an S3 resource. This requires no glue code or handling. It is seamlessly handled by APIGW.

Using API Keys & Usage Plans, we ensured only authenticated clients got access to data and also rate limited their API calls.

Analytics & Read
All of the write paths use the main API Gateway (APIGW) and Lambda functions to write to DynamoDB. We capture all granular events such as playback, download, visit, and batch them up to the server. Partial data loss is ok with the volume we expected.
We created an internal portal to create a feedback loop of usage which was based on the data in DynamoDB. The web app used the HTTP API endpoints within the same APIGW to fetch data from DynamoDB.
Aggregator Lambda
To monitor and analyse the content changes, we deployed a cron based lambda functions that pulled the current JSON in the data bucket and created a snapshot of it. The snapshots were aggregated over a time interval and uploaded to reporting S3 bucket. A webapp fetched the latest aggregate data and charted it for the admin to review.
Results and Conclusion
The entire setup took about 1.5 months to build. Once deployed, we never breached the free tier of many services for processing. Our biggest cost center was data transfer. We had also enabled all edge nodes for Cloudfront which cost us a bit more. The latency issues were non existent. Our DR was pretty self solved due to S3 becoming our primary data store and DynamoDB was highly available but not in the critical path.
Final notes
We had a specific use case that was served quite well with our design choices. This may not be the most optimal architecture for more demanding and real-time applications.
This content originally appeared on DEV Community and was authored by Arif Amirani
Arif Amirani | Sciencx (2021-08-10T13:16:28+00:00) A JSON Based Serverless Quasi-Static Platform. Retrieved from https://www.scien.cx/2021/08/10/a-json-based-serverless-quasi-static-platform/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.