
This content originally appeared on DEV Community and was authored by Ferdinand Boas
One of the cool things about Machine Learning is that you can see it as a competition. Your models can be evaluated with many performance indicators, and be ranked on various leaderboards. You can compete against other Machine Learning practitioners around the world, and your competitors can be a student in Malaysia or the largest AI lab at Stanford University.
Kaggle started as a platform to host such Machine Learning contests, and it gained a lot of attention from the data science community. The best data scientists exhibit on Kaggle their most sophisticated Machine Learning skills, craft the most elaborated models to reign over these competitions.
Kaggle is now a broader platform, where you can enter these competitions but also learn data science, discuss it, and collaborate with fellow data scientists.
Most of the Kaggle competitors are Machine Learning practitioners. Many software engineers do not enter these competitions, mostly because they think that they do not have the needed skill set, tools, or time to be successful in them.
Machine Learning can be hard to learn and use. It’s a very technical field.
Running a Machine Learning project is complex: you will have to gather and clean data, choose a pre-trained model or train a model that suits your needs, fine-tune it for your curated dataset, and deploy the model in a production environment. You will also need to worry about monitoring, scalability, latency, reliability...
This is usually a resource-intensive process, it takes time, knowledge, compute resources, and money. This does not fit well with the regular activities of a software engineer.
At this stage, I need to point out that I am not a data scientist.
You may now wonder how I ranked among the best data scientists in a Kaggle Natural Language Processing (NLP) challenge without using any Machine Learning.
This blog post explains how I successively leveraged Hugging Face ? AutoNLP web interface and ? Inference API to achieve this result.
Find all the scripts and assets used in this GitHub repository.
 ferdi05
/
kaggle-disaster-tweet-competition
ferdi05
/
kaggle-disaster-tweet-competition
Participating to a Kaggle competition without coding any Machine Learning
The Kaggle competition
Entering a Kaggle competition is straightforward. You are asked to perform a task such as sentiment analysis or object detection that can be solved with Machine Learning. Kaggle provides a training dataset with examples of the task to achieve. You can use this dataset to train a Machine Learning model. Then you can use this model to perform the same task on a test dataset (also provided by Kaggle). This is your attempt at solving the challenge. Then you will submit your model predictions for this test dataset to Kaggle and they will evaluate it and give you a ranking in the competition that you entered.
You will find plenty of NLP competitions on the Kaggle website. I participated in the Natural Language Processing with Disaster Tweets competition as it is quite recent (7 months when writing this post) and has over 3,000 submissions from other teams.
This competition challenged me to build a Machine Learning model that predicts if a tweet is about a real disaster or not.
 Charlie Langa@charlielanga
Charlie Langa@charlielanga @marksmaponyane Hey!Sundowns were annihilated in their previous meeting with Celtic.Indeed its an improvement.19:27 PM - 05 Aug 2015
@marksmaponyane Hey!Sundowns were annihilated in their previous meeting with Celtic.Indeed its an improvement.19:27 PM - 05 Aug 2015


This tweet is not about a real disaster
Kaggle provides a training dataset of around 7,500 tweets (the input object) with their associated label (the desired output value). These labels tell if each tweet is about a disaster (its label is 1) or not (its label is 0). This dataset will be used to train a few Machine Learning models and evaluate them.

Kaggle also provides a test dataset of around 3,200+ tweets without any paired label. We will use the newly created Machine Learning model to predict if they are about a disaster, asking the Machine Learning model to apply labels to each of these tweets.

Both datasets also contain two other data columns that will not be used: a keyword and the location of the tweet.
? AutoNLP web interface to the rescue
The process of training a Machine Learning model is not straightforward. It requires collecting cleaning and formatting data, selecting a Machine Learning algorithm, playing with the algorithm parameters, training the model, evaluating its performance, and iterating. And this does not guarantee that performances will reach your expectations.
This is a resource-intensive process. Fortunately, I used a web interface to do all the heavy-lifting and save hours of Machine Learning-induced head-scratching.
What is ? AutoNLP?
Leveraging its experience with the most performant architectures of NLP, Hugging Face offers the ? AutoNLP web interface to automatically train, evaluate and deploy state-of-the-art NLP models for different tasks. All you need to do is feed it your datasets.
? AutoNLP uses supervised learning algorithms to train the candidate Machine Learning models. This means that these models will try to reproduce what they learned from examples that pair an input object and its desired output value. After their training, these models should successfully pair unseen input objects with their correct output values.
? AutoNLP will train a range of NLP models suitable for the task required by the competition and will use a various set of configurations for each of them. Then each model’s performance will be automatically evaluated. I saved a lot of resources and money by avoiding their computer-intensive training.
Later I selected the most performant model to make predictions for the Kaggle competition.
Training Machine Learning models with data only
The competition requires to label each tweet as related to a disaster or not. And binary text classification is one of the tasks achievable with the ? AutoNLP web interface. So I started a new project.
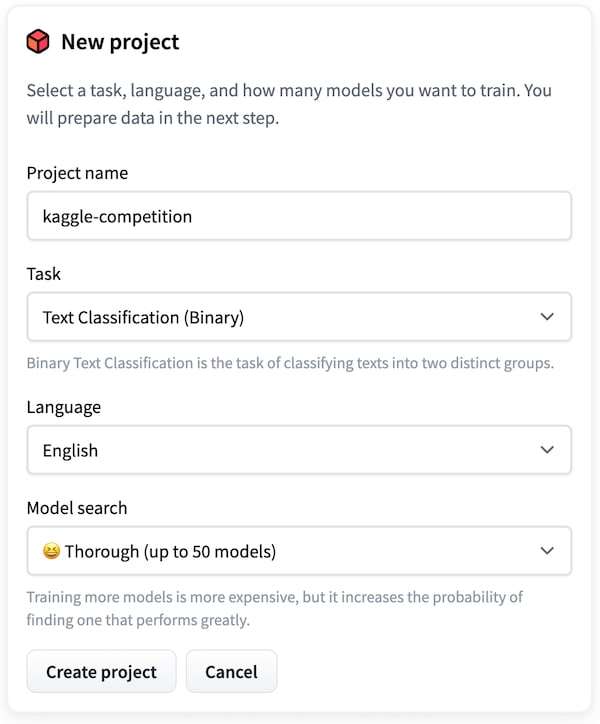
In this competition, Kaggle provides only one training dataset but you need one dataset to train the models (the training dataset) and another one (the validation dataset) to evaluate their performance.
I split the original dataset provided by Kaggle into 2 datasets using a rule of thumb ratio of 80%-20%.
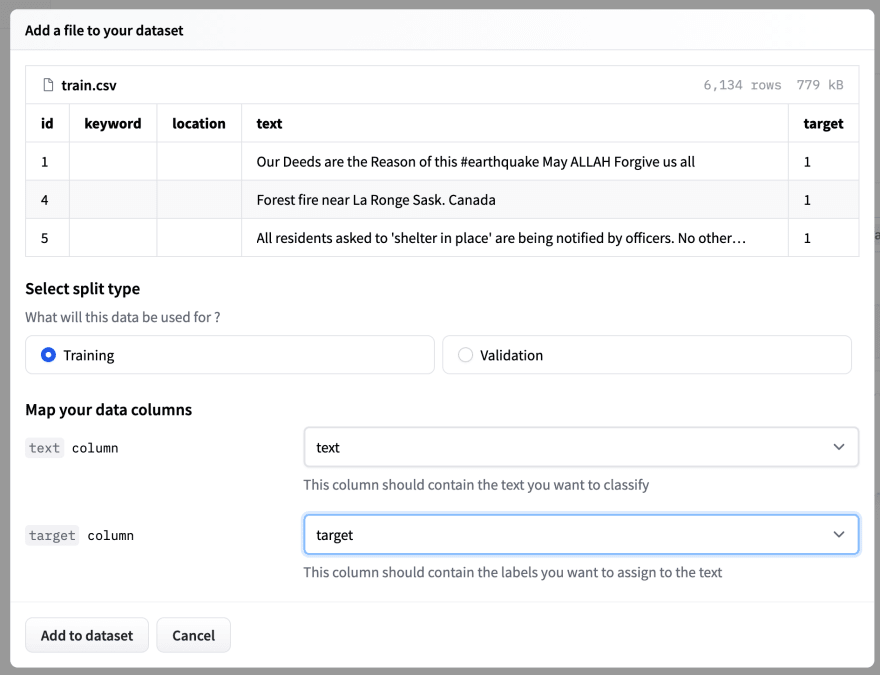
The columns of both datasets need to be mapped. The text column is the input object and the target column is the desired output value. Here the input object is the tweet content, and the output value is its associated label.
Then the web interface started the training and did its magic.
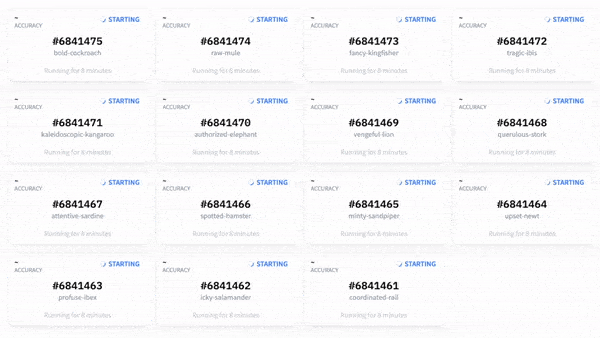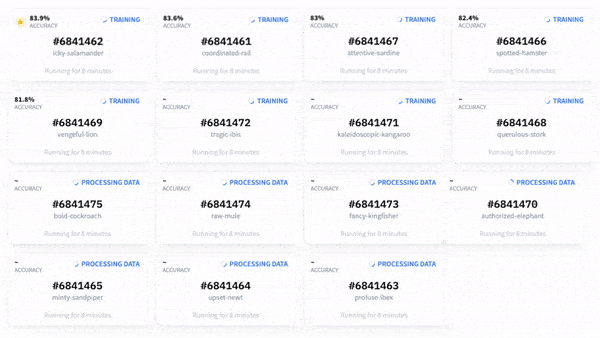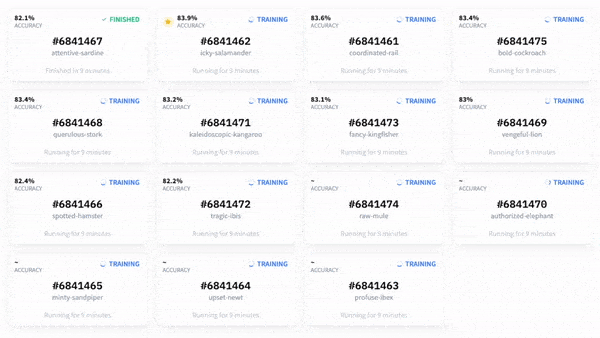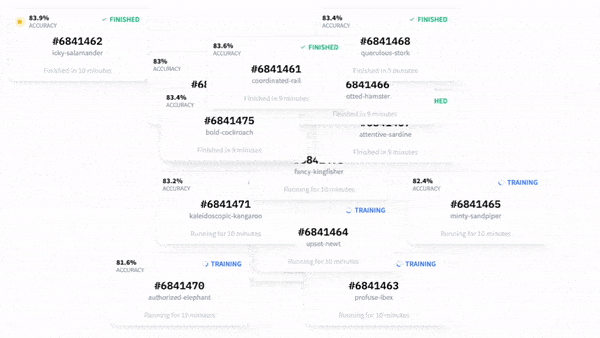
After a few minutes, models were trained, evaluated, and uploaded on the Hugging Face Hub (with private visibility). They were ready to serve, still without any Machine Learning instructions, as you will see later.
For this competition, Kaggle evaluates the performance of the predictions with their F1 score. This is an accuracy metric for a machine learning model. So the best model was the one with the highest F1 score.

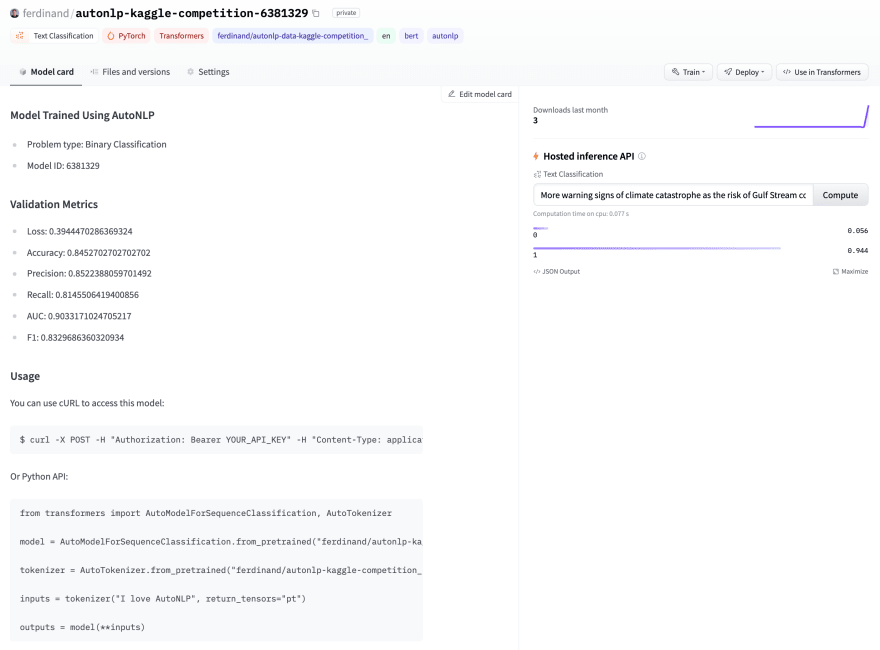
Kaggle sometimes evaluates results with more sophisticated metrics. Conveniently ? AutoNLP web interface automatically uploads every trained model’s file on the Hugging Face Hub with their associated card. Each card includes the model metrics (that you may combine according to your need) and code snippets to use the model. And there is even a widget to quickly experiment with the model.
Solving the Kaggle challenge with the ? Inference API
It is now time to use the most performant model on the test dataset provided by Kaggle.
There are two different ways to use the model:
- the data scientist way: deploying the model on a dedicated infrastructure, or on a Machine Learning platform
- the developer-friendly way of using it: through API calls. This is the one that I will describe here.
Serving Machine Learning models with the ? Inference API
Using Machine Learning models in production is hard, even for Machine Learning engineers:
- you may have a difficult time handling large and complex models
- your tech architecture can be unoptimized
- your hardware may not meet your requirements Your model may not have the scalability, reliability or speed performances that you were expecting.
So I relied on the ? Inference API to use my model, still without coding any Machine Learning. The API allows to reach up to 100x speedup compared to deploying my model locally or on a cloud, thanks to many optimization techniques. And the API has built-in scalability which makes it a perfect addition to a software production workflow, while controlling the costs as I will not need any extra infrastructure resources.
A few API calls to solve the challenge
Let’s call the ? Inference API for each row of the test dataset, and write the output value in the submission file.
I could have used the API via regular HTTP calls, but there is an alternate way: the huggingface_hub library conveniently offers a wrapper client to handle these requests, and I used it to call the API.
import csv
from huggingface_hub.inference_api import InferenceApi
inference = InferenceApi("ferdinand/autonlp-kaggle-competition-6381329", token=API_TOKEN) # URL of our model with our API token
MODEL_MAX_LENGTH = 512 # parameter of our model, can be seen in config.json at "max_position_embeddings"
fr = open("assets/test.csv") # Kaggle test data
csv_read = csv.reader(fr)
next(csv_read) # skipping the header row
fw = open("assets/submission.csv", "w", encoding="UTF8") # our predictions data
csv_write = csv.writer(fw)
csv_write.writerow(['id', 'target']) # writing the header row
#returns a label : about a disaster or not given a tweet content
def run(tweet_content):
# calling the API, payload is the tweet content , possibly truncated to meet our model requirements
answer = inference(inputs=tweet_content[:MODEL_MAX_LENGTH])
# Determining which label to return according to the prediction with the highest score
# example of an API call response: [[{'label': '0', 'score': 0.9159180521965027}, {'label': '1', 'score': 0.08408192545175552}]]
max_score = 0
max_label = None
for dic in answer[0]:
for label in dic['label']:
score = dic['score']
if score > max_score:
max_score = score
max_label = label
return max_label
for row in csv_read: # call the API for each row
# writing in the submission file the tweet ID and its associated label: about a disaster or not
write_row = [row[0], run(row[3])] # row[0] is the tweet ID, row[3] is the tweet content
csv_write.writerow(write_row)
After running the ? Inference API on all the input data (it may take a while), I ended up with a file that I submitted to Kaggle for evaluation.

This model made it to the top 15% of the competitors with a 0.83 mean score!
At first, I was surprised to not rank higher. Unfortunately, the test dataset and its associated label used for this competition are available publicly. So a few clever contestants submitted it and received an approximate 1.00 score, which is not something realistic in a data science problem.
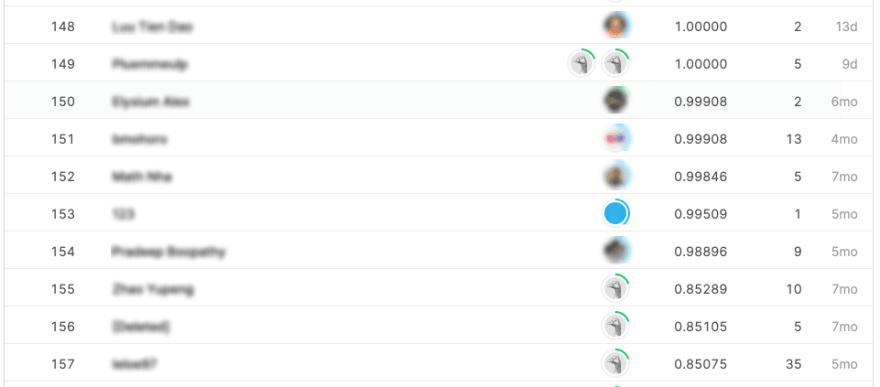
Having a second look at the leaderboard, I saw that the best data science teams have a 0.85 score. This is very close to the score that I obtained, and another ?AutoNLP test may give better results, depending on how lucky I am with the random variations of each model’s parameters. Given the time and resources invested in solving this challenge, this is almost a win!
Do more with the AutoNLP Python package
With the ? AutoNLP web interface, the ? Inference API, and a very few lines of code, NLP models were automatically created, deployed, and used to achieve a great ranking in an NLP competition without learning or using any Machine Learning techniques.
? AutoNLP can also be used as a Python package and can support more Machine Learning tasks than those provided by the web interface - but the interface is quickly catching up. You can use the package to perform tasks like speech recognition and enter even more Kaggle competitions!
If you want to win a Kaggle competition or to train a model for your business or pleasure, you can get started with AutoNLP here.
This content originally appeared on DEV Community and was authored by Ferdinand Boas
Ferdinand Boas | Sciencx (2021-08-10T13:51:28+00:00) How I almost won an NLP competition without knowing any Machine Learning. Retrieved from https://www.scien.cx/2021/08/10/how-i-almost-won-an-nlp-competition-without-knowing-any-machine-learning/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.