
This content originally appeared on Level Up Coding - Medium and was authored by Lee James Gilmore

Example of using AWS Comprehend to understand the sentiment of your customers content, whilst also redacting PII, with visuals and accompanying code repo written in TypeScript and the Serverless Framework! ?

Introduction
Do you currently check the sentiment of your customers comments, transcribed call details, chat history etc? And if not, how do you know if they are generally happy, annoyed or mixed? Do you currently log PII (Personal Identifiable Information) which you possibly shouldn’t due to GDPR? Do you need the contents stored, but with the PII redacted?
This example shows a fully serverless solution built using AWS Comprehend alongside Amazon API Gateway and AWS Lambda, to showcase some of the basic things you can achieve with little code, to mitigate the issues described above!
You can access the basic code repo here which has verbose comments for clarity, as well as keeping the majority of the code in one file for simplicity.
? Please note this is the minimal code and architecture to demonstrate the use of AWS Comprehend with Lambda, so this is not production ready and does not adhere to coding best practices.
What are we building?
The architecture diagram below shows what we are going to build, and is described further below:
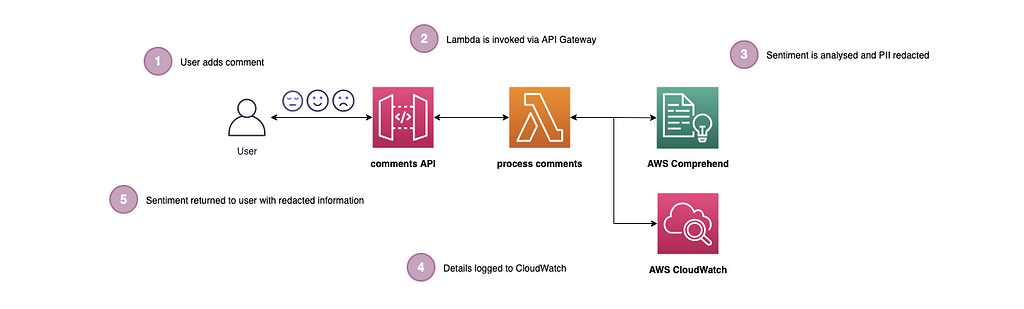
The architecture is described below:
- The user hits the /comments POST endpoint and adds a comment.
- API Gateway invokes the lambda.
- AWS Comprehend is used to understand the sentiment of the comment as well as redacting any PII from it.
- The redacted comment and the sentiment is logged to AWS CloudWatch.
- The redacted comment and sentiment are returned to the user in the response, along with the original comment.
What is AWS Comprehend? ?
Amazon Comprehend is a natural-language processing (NLP) service that uses machine learning and AI to uncover information in unstructured data.
The service can identify critical elements in data, including references to language, people, and places, and the text files can be categorised by relevant topics. In real time, you can automatically and accurately detect customer sentiment in your content.
“This accelerates more informed, real-time decision making to improve customer experiences”
Comprehend not only locates any content that contains personally identifiable information, it also redacts and masks that content.
?The following video gives a great overview:
What are the use cases?
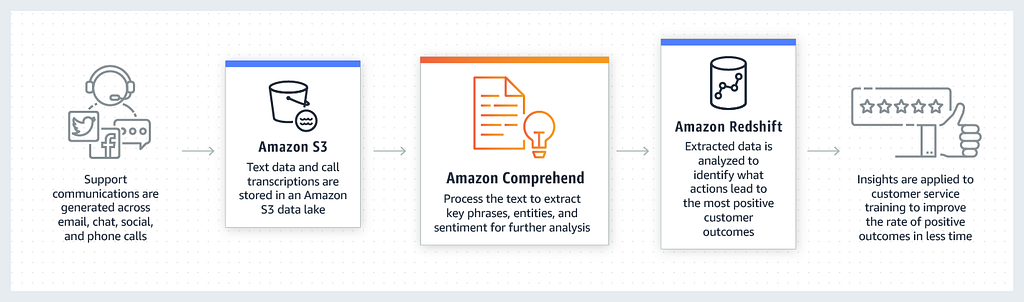
A couple of the use cases for AWS Comprehend are shown below.
Automatically detect customer sentiment using Amazon Comprehend Accurately analyse customer interactions, including social media posts, to improve your products and services.
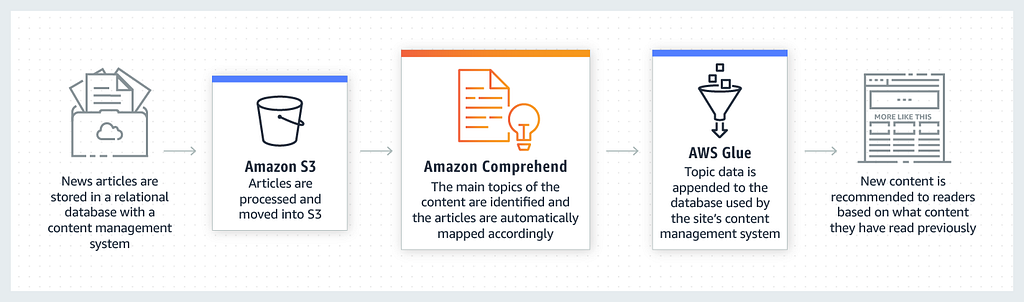
You can use Amazon Comprehend to organise and categorise documents on your website by topic for easier discovery
Content can be personalised for readers and recommendations provided to related articles.
What is PII and how does AWS Comprehend work with it? ?
PII stands for Personal Identifiable Information; with examples being names, locations, bank details, email addresses, telephone numbers etc. Due to GDPR considerations, it is likely that you want to store or log certain information, but you may need to redact any of the personal information from it (as well as for security reasons).
AWS Comprehend helps to redact the information by using machine learning and AI to automatically pull out key pieces of information which are labeled as PII, allowing you to programmatically redact it.
? Comprehend can also redact the PII automatically for you using a separate batch method, however I wanted to be explicit with it in this example.
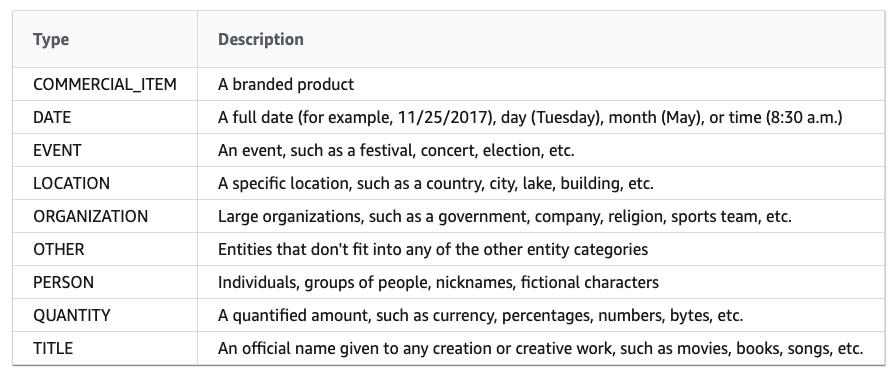
The table below shows the PII entities which AWS Comprehend is capable of locating currently out of the box:

Show me the code! ??
? Note: Running the following commands will incur charges on your AWS account so change the config accordingly.
In the root of the folder run npm i and then npm run deploy:develop which will install all of the dependencies and then deploy to AWS.
The serverless deploy will generate the resources for you using the Serverless Framework i.e. the API and compute layer. You will see similar output to this on success:
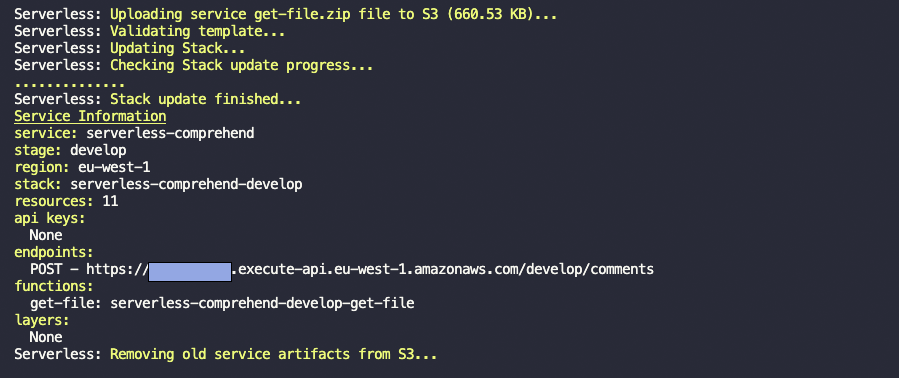
? Make a note of the main API url as you will need this for the following section when testing the endpoints with a Postman file.
A snippet of the main function is detailed below showing the basic calls to the comprehend API using the AWS SDK:
Testing the API! ?
You can test the endpoint now using the Postman file in the ./postman folder, and hitting the ‘POST comment’ request with a body like the following below, once you have replaced the ‘url’ variable with your generated API response from the section above:
{
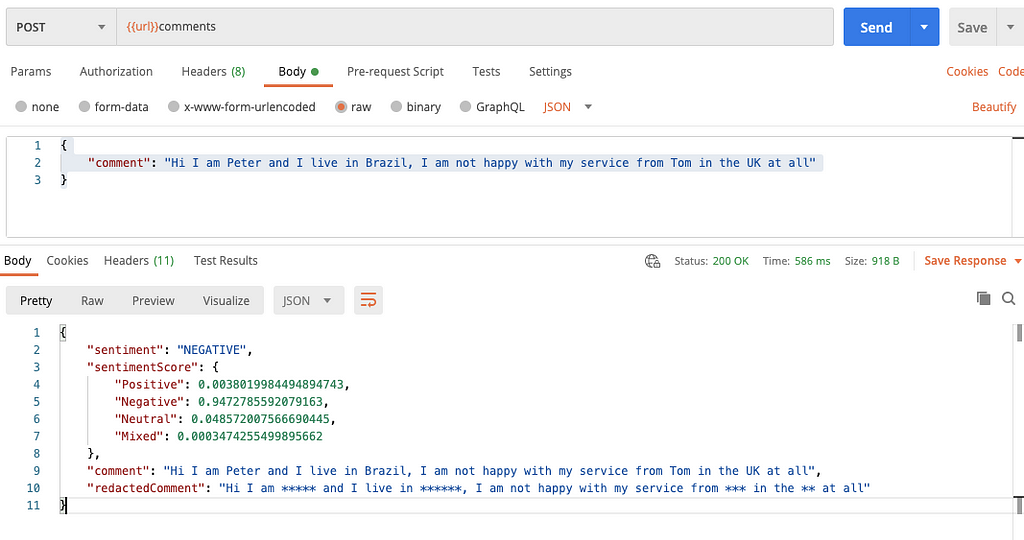
"comment": "Hi I am Peter and I live in Brazil, I am not happy with my service from Tom in the UK at all"
}You will get a response from the endpoint as shown below:
and you can see the detailed logs in CloudWatch too:

So what is happening here? ?
You can see from the response above that we have the following properties:
sentiment: This is the overall sentiment from the comment, which is obviously negative.
sentimentScore: This is a score up to 1 (1 being the highest confidence) of the returned sentiment of the comment. You can see that it is split into four properties, Positive | Negative | Neutral | Mixed
comment: This is the original un-redacted comment which you passed into the payload in the POST request.
redactedComment: This is the original comment with any PII which comprehend found redacted (with *’s).
We can then test again with a different comment to see what we get back in the next response ?
Hitting the endpoint with the following:
{
"comment": "Its great that you found the product my wife Susan was looking for, I will send her an email to susan@google.com to let her know"
}Will give you the following response:
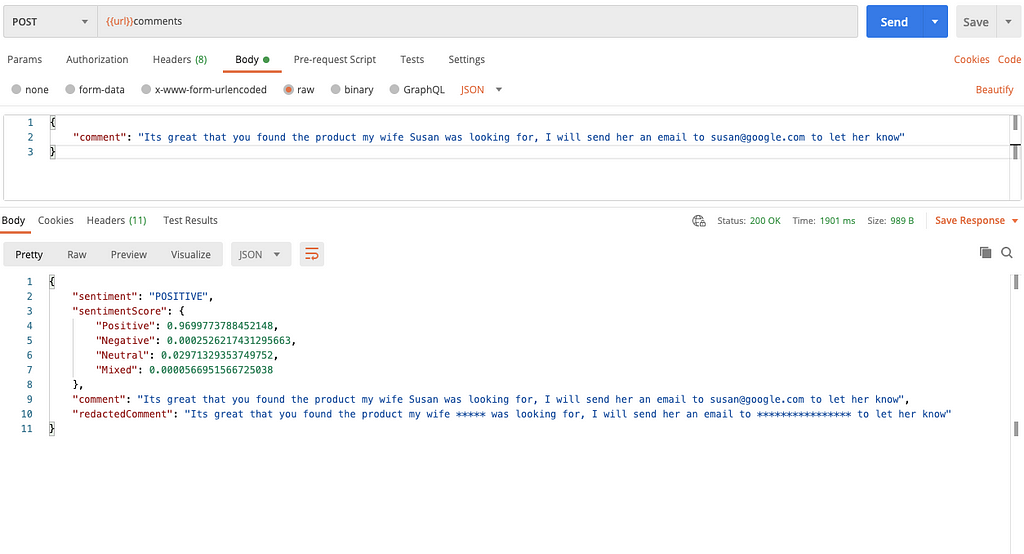
As you can see, this time both the name and email was redacted, and the overall sentiment was understood to be positive.
“Have a play around to see how you find it! This may fit your current needs” ?
Are there any issues with this approach?
From playing around with various comments/text I have found that AWS Comprehend does not always find the PII in the text, which is a concern if you are relying on this for security or GDPR reasons. (or I should say, the labels I would personally believe to be PII)
This is most likely due to the model not having enough context based on this being a simulated chat response, but within a set of logs based on a full conversation I would see this as an accumulation of PII (enough to identify a person)
Examples of replies/comments that could be in a chat which are not redacted are:
“Yes please, the Newcastle store” in response to which store for delivery?
“My car registration is ER21 ITG” in response to what is your car registration?
“Im from Newcastle, yes” in response to where are you from?
“its, 11–08–90” in response to what is your date of birth? (this is the same for sort-code in the UK)
“its 65624352” in response to what is your bank account number?
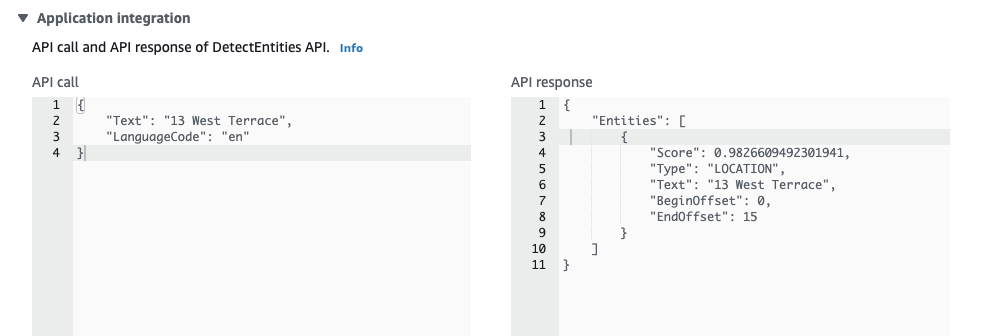
“13 West Terrace” in response to what is your address?
In one particular chat with a call centre agent I would no doubt be able to identify this person above.
From testing in the console, it shows clearly that using the DetectEntities API finds all of the entities above, however the DetectPiiEntities API does not find any of it…(perhaps due to the interpretation of PII within the model and not having enough context to work with within the text)
Taking an example from above with “13 West Terrace” as a response in a chat, you can see that this is detected using the DetectEntities API as a location:
But not picked up using the DetectPiiEntities API:
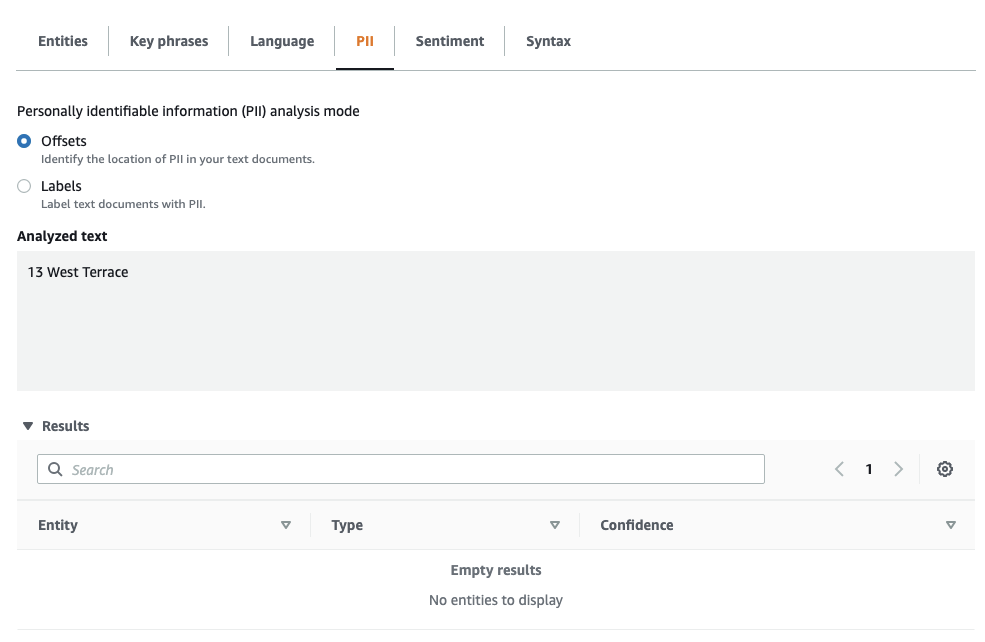
Interestingly the DetectEntities API also picks up different entities compared to the DetectPiiEntities API (the table at the start of the article)
? Note: From this basic testing it shows that it may be beneficial to use the DetectEntities API over the DetectPiiEntities for accuracy in certain scenarios, although I will reach out to AWS and update the post with their response.
Wrapping up
I would love to connect with you on any of the following:
https://www.linkedin.com/in/lee-james-gilmore/
https://twitter.com/LeeJamesGilmore
If you found the articles inspiring or useful please feel free to support me with a virtual coffee https://www.buymeacoffee.com/leegilmore and either way lets connect and chat! ☕️
If you enjoyed the posts please follow my profile Lee James Gilmore for further posts/series, and don’t forget to connect and say Hi ?
Please also use the ‘clap’ feature at the bottom of the post if you enjoyed it! (You can clap more than once!!)
About me
“Hi, I’m Lee, an AWS certified technical architect and Lead Software Engineer based in the UK, currently working as a Technical Cloud Architect and Principal Serverless Developer, having worked primarily in full-stack JavaScript on AWS for the past 5 years.
I consider myself a serverless evangelist with a love of all things AWS, innovation, software architecture and technology.”
** The information provided are my own personal views and I accept no responsibility on the use of the information. ***
Are your Serverless customers happy or sad?? was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Lee James Gilmore
Lee James Gilmore | Sciencx (2021-08-22T18:12:35+00:00) Are your Serverless customers happy or sad?. Retrieved from https://www.scien.cx/2021/08/22/are-your-serverless-customers-happy-or-sad/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.