
This content originally appeared on DEV Community and was authored by Michael Bogan
Unless you’ve been developing software in a cave, you’ve probably heard people sing the praises of microservices. They’re agile, simple, and an overall improvement on the monolith and service-oriented architecture days. But of course, with all the benefits of microservices comes a new set of challenges.
In this article, we’ll look at some microservices best practices. Plus, we’ll suggest a few proven ways to help you design, orchestrate, and secure your microservices architecture. By understanding these practices, you’ll have a head start on a successful project.
Benefits and Challenges of Microservices
Before we dive into microservices best practices, however, we should first talk about some of the benefits and challenges of microservices and why you would want to use them in the first place.
Briefly, microservices are an improved software architecture that allow you to:
- Deploy and scale faster. Smaller application domain responsibility allows for automation, leading to faster deployments and faster scaling.
- Reduce downtime. Limit the impact that one unavailable service has on your primary business function, improving your overall business uptime.
- Ensure availability. Keep functionality between microservices discrete, limiting the impact when an instance goes down.
Of course, with these benefits, we have a new set of challenges, including inter-service communication, security, and scalability.
- Inter-service communication. With a monolithic application, all of the modules can inherently talk to one another. You have one certificate to manage, and once a request is authenticated and authorized, it can traverse the code paths without issue. When you extract a function out of the monolith architecture to a microservices application, what was once an internal function call becomes an external API call requiring authentication and authorization for that outside microservice.
- Security layer. Authentication and authorization, in the monolith application, can be handled one time at the point of entry. With the transition to microservices, every microservice needs to perform some authentication and authorization to enforce access controls. It's not realistic to ask users to log in every time they use a different microservice, so a comprehensive auth strategy needs to be established.
- Scalability. Although microservices allow you to scale independent functionality quickly, doing so effectively requires good app management and even better tooling. The effectiveness of your scalability hinges on your microservice orchestration platform, which we’ll talk about in more detail below.
Microservices Best Practices
With that quick overview of the benefits and challenges of microservices, let’s now dive into some best practices. These best practices will help you create a robust, easy-to-manage, scalable, and secure system of intercommunicating microservices.
1. Small Application Domain
Adopting a microservices strategy requires embracing the single responsibility principle. By limiting the scope of responsibility for any single service, we limit the negative impact of that service failing. If a single microservice is responsible for too much, its failure or unavailability will have a domino effect on the rest of the system.
A _micro_service should be just that: micro. Keep the app domain of your microservices small, dedicated to one logical functionality. This will reduce the impact that a given microservice has if any issues arise. In addition, smaller services are simpler to maintain. The result is easier updating and faster development.
What does this look like in practice? For example, let's assume that our microservice is an API server that accepts requests to fetch data, and an authorization token must accompany those requests. When you're just starting, this is the only microservice that requires an authorization token. Why not just make authentication and token generation part of the microservice? At first glance, the advantage is fewer moving parts, less to manage.
Of course, there will come a day when you'll have other services that require an authorization token. You'll soon find your original microservice functioning as an API server and an authentication server. If your API server goes down, then your authentication server goes down with it. With that, so does every other service that requires an authorization token.
Be considerate of your future self: keep your microservices small.
2. Separation of Data Storage
Multiple microservices connecting to the same database are still, in essence, a monolithic architecture. The monolith is just at the database layer instead of the application layer, making it just as fragile. Each microservice should have, as much as possible, its own data persistence layer. This not only ensures isolation from other microservices but also minimizes the blast radius if that particular data set were to become unavailable.
At times, it might seem to make sense for different microservices to access data in the same database. However, a deeper examination might reveal that one microservice only works with a subset of database tables, while the other microservice only works with a completely different subset of tables. If the two subsets of data are completely orthogonal, this would be a good case for separating the database into separate services. This way, a single service depends on its dedicated data store, and that data store's failure will not impact any service besides that one.
We could make an analogous case for file stores. When adopting a microservices architecture, there's no requirement for separate microservices to use the same file storage service. Unless there's an actual overlap of files, separate microservices ought to have separate file stores.
With this separation of data comes an increase in flexibility. For example, let's assume we had two microservices, both sharing the same file storage service with a cloud provider. One microservice regularly touches numerous assets but is small in file size. The other microservice has only a few files that it touches periodically, but those files are hundreds of gigabytes in size.
Using a common file store service for both microservices makes you less flexible to optimize costs since you have a mix of large and small files and a mix of regular and periodic access. If each microservice had its own data persistence layer—and that could be a separate microservice, of course—then you’d have more flexibility to find the provider or service that best fits the needs of that individual microservice.
Cost optimization, the flexibility of options, and less dependence on a single solution that could fail—these are all reasons to separate the data of different microservices.
3. Communication Channels
How microservices communicate with one another—in particular, regarding events of interest—requires thoughtful consideration. Otherwise, a single unavailable service can lead to a communication breakdown that collapses an entire application.
Imagine a system of microservices for an online store. One microservice takes orders placed by a website. Another microservice sends a text notification to the customer that it received their order. Another microservice notifies the warehouse to send out the product. Finally, another microservice updates inventory counts.
There are two types of communication between microservices: synchronous and asynchronous. If we approach the above example using synchronous communication, a web server might process a new order by first sending a request to the customer notification service. After the customer notification service responds, the web server sends a request to the warehouse notification service, and again it waits for a response. Last, the web server sends a request to the inventory updater. Our synchronous approach would look like this:
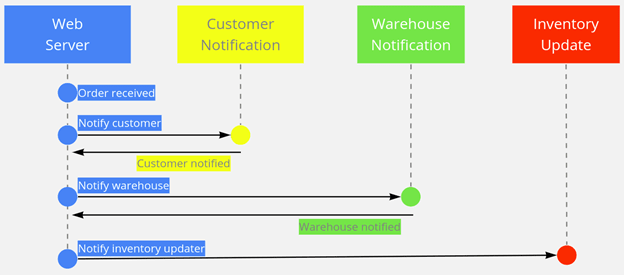
Synchronous communication between microservices
Of course, suppose the customer notification service happened to be down. In that case, the request to notify the customer might timeout or return an error or perhaps leave the web server waiting for a response indefinitely. The warehouse notification service might never get the request to fulfill the shipment. Synchronous communication between microservices can create a dependency chain that breaks if any link in the chain breaks.
In asynchronous communication, a service sends a request and continues its life without waiting for a response. In one possible asynchronous approach, the web server might send the "notify customer" request and then complete its task. The customer notification service is responsible for notifying the customer and sending an asynchronous request to the warehouse notification service, which is responsible for sending a request to the inventory updater service. It might look like this:

Chained asynchronous communication between microservices
In this model, of course, we see that asynchronous communication can still result in a chain dependency, and the failure of a single service would still disrupt the application.
A simple but effective approach to asynchronous communication is to adopt the publish/subscribe pattern. When an event of interest occurs, the producer—in this case, the microservice—publishes a record of that event to a message queue service. Any other microservices interested in that type of event subscribe to the message queue service as consumers of that event. Microservices only talk to and listen to the message queue service, not each other.
For our example, it might look like this:

Asynchronous communication facilitated by a message queue service
The message queue is a separate service of its own, decoupled from all of the microservices. It is in charge of receiving published events and notifying subscribers of those events. This ensures that the failure of one microservice, which might mean delayed delivery of a message, has minimal impact on other related but unconcerned services.
There are many tools to accomplish this kind of asynchronous communication (for example, Kafka or RabbitMQ). Look for ways to integrate tools like these as asynchronous communication backbones for your microservices.
There are cases when synchronous communication between microservices is necessary. Most request-response interactions are, out of necessity, synchronous. For example, an API server querying a database must wait for the query response; a web server fetching cached data must wait for the key-value store to respond.
When synchronous communication is needed, you’ll want to use the open source Kong Gateway to ensure that your communication is routed quickly and reliably to the right microservices.
4. Compatibility
As much as possible, maintain backward compatibility, so your consumers don’t encounter broken APIs. The popular way to do this is by following path level compatibility guarantees like /api/v1 or /api/v2. Any backward-incompatible changes go to a new path like /api/v3.
However, despite our best efforts as software engineers, sometimes we need to deprecate APIs, so we’re not stuck running them forever. With the API gateway request transformation plugin, your microservices can alert your API consumers by easily injecting deprecation notices alongside the original API response or attaching a “deprecation header” similar to Kubernetes.
5. Orchestrating Microservices
Orchestration of your microservices is a key factor of success in both process and tooling. Technically, you could use something like systemd and Docker or podman to run containers on a virtual machine, but that doesn’t provide the same level of resiliency as a container orchestration platform. This negatively affects the uptime and availability benefits that come with adopting a microservices architecture. For effective microservice orchestration, you’ll want to rely on a battle-tested container orchestration platform; and the clear leader in that field is Kubernetes.
Kubernetes manages all of your containers’ provisioning and deployment while handling load balancing, scaling, replica sets for high availability, and network communication concerns.
You might deploy bare Kubernetes on-premises, or you might go with a cloud distribution like Azure Kubernetes Service, Red Hat OpenShift, or Amazon Elastic Kubernetes Service. The built-in scheduling, replication, and networking capabilities of Kubernetes make microservice orchestration much easier than on a traditional operating system.
Couple Kubernetes with Kuma service mesh and Kong Ingress Controller, and you have microservices that are discoverable, monitored, and resilient—like magic.
6. Microservices Security
As your application comprises more and more microservices, ensuring proper security can become a complicated beast. A centralized system for enforcing security policies is vital to protecting your overall application from malicious users, invasive bots, and faulty code. Kong ought to be the start of your security story with microservices, whether you’re running on VMs or in Kubernetes. The abundance of Kong-maintained security plugins makes it easy to address some of the most common needs for microservices, including authentication, authorization, traffic control, and rate limiting.
Example: Rate Limiting with Kong Ingress Controller
To demonstrate an example of a security plugin at work, we'll deploy Kong's Rate Limiting plugin to show how Kong can prevent excessive inbound requests to your applications. We'll create a local Kubernetes cluster with kind and then deploy the Kong Ingress Controller by following these instructions.
After creating a cluster and deploying the Kong Ingress Controller, our first step is to set up the Rate Limiting plugin. There are different scopes for which you can set up the plugin. We’ll use the default project on our Kubernetes cluster for our use case and scope the plugin to that default namespace.
$ echo 'apiVersion: configuration.konghq.com/v1
kind: KongPlugin
metadata:
name: rate-limiting-example
namespace: default
config:
second: 5
hour: 10000
policy: local
plugin: rate-limiting' | kubectl apply -f -
kongplugin.configuration.konghq.com/rate-limiting-example created
Now, we’ll create an “echo service” and an ingress for the service. In this case, we’re borrowing the example from Kong’s Getting Started with Kubernetes Ingress Controller documentation:
$ kubectl apply -f https://bit.ly/echo-service
service/echo created
deployment.apps/echo created
$ echo "
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: demo
annotations:
kubernetes.io/ingress.class: kong
konghq.com/plugins: rate-limiting-example
spec:
rules:
- http:
paths:
- path: /foo
backend:
serviceName: echo
servicePort: 80
" | kubectl apply -f -
The last thing we need to do is test! We’ll borrow the shell-demo from the Kubernetes documentation for in-cluster testing:
$ kubectl apply -f https://k8s.io/examples/application/shell-demo.yaml -n default
Before getting into our shell pod, we’ll need the cluster IP of kong-proxy:
$ kubectl get svc/kong-proxy -n kong -o jsonpath='{.spec.clusterIP}'
10.96.74.69
Now, we can get shell access to our pod and test the rate limiting:
$ kubectl exec --stdin --tty shell-demo -- /bin/bash
# curl -I 10.96.74.69/foo
HTTP/1.1 200 OK
Content-Type: text/plain; charset=UTF-8
Connection: keep-alive
X-RateLimit-Limit-Second: 5
X-RateLimit-Remaining-Hour: 9998
X-RateLimit-Limit-Hour: 10000
RateLimit-Reset: 1
RateLimit-Remaining: 4
RateLimit-Limit: 5
X-RateLimit-Remaining-Second: 4
Date: Sat, 24 Jul 2021 20:01:35 GMT
Server: echoserver
X-Kong-Upstream-Latency: 0
X-Kong-Proxy-Latency: 0
Via: kong/2.4.1
The additional step of using an intermediary pod to test the rate limiting won’t be necessary for most cloud providers, which gives you a load balancer out of the box. In this case, since we’re using kind, there’s no load balancer provisioned, so our test comes from within the cluster. This same test would work externally if a load balancer were available.
Rate limiting is just one example of where Kong fits into the security concerns of your overall microservices strategy and best practices but can easily provide a fully comprehensive solution. Kong maintains several plugins and products to keep your communication channels bulletproof, API change impact minimal, and your application domains manageable. Plus, it's compatible with most programming languages and vendor options.
7. Metrics and Monitoring
An architecture built on microservices can lead to massive scaling of hundreds or thousands of small, modular services. While that yields huge potential for increased speed, availability, and reach, a sprawling system of microservices requires a strategic and systematic approach to monitoring. By keeping an eye on all of your microservices, you'll ensure that they are functioning as they ought to, are available to your users, and are using resources appropriately. When any of these expectations are not met, you can respond by taking proper action.
Fortunately, you don't need to reinvent the wheel when it comes to monitoring. There are several widely adopted monitoring solutions that can integrate seamlessly within your infrastructure. Some solutions use metrics exporter SDKs which can be integrated by adding one or two lines of code in your microservice. Others can be integrated with your API gateway or service mesh as a plugin, for monitoring networking concerns and resource usage.
As your monitoring tools gather metrics, those metrics can be consumed by visualization tools—beautiful dashboards that help you see the numbers behind your microservices. How many users were online last Thursday at 8:00 PM? How much has CPU load increased since we released that new feature? What's the latency between our product shipping API and the invoicing API?
By monitoring your microservices and having your hard numbers presented clearly, you're equipped to make informed decisions about how to keep your microservices healthy and available. As you do that, you'll keep your users happy.
Don’t Forget Your Lap Bar...
Microservices are a wild ride! You start with the incredible benefits of speedier deployment and scalability, reduced downtime, and overall improvement of your business availability. Then, you throw in your orchestration platform, along with some best practices powered by Kong and its plugins, and boom! You have a symphony of packets flowing to and fro between your microservices that are secure, reliable, and bulletproof. We’ve only covered a small subset of what Kong can do, so I’d highly recommend checking out Kong Hub to see all the functionality available to ease your journey to microservice nirvana!
This content originally appeared on DEV Community and was authored by Michael Bogan
Michael Bogan | Sciencx (2021-09-13T12:21:05+00:00) 7 Microservices Best Practices for Developers. Retrieved from https://www.scien.cx/2021/09/13/7-microservices-best-practices-for-developers/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.