
This content originally appeared on DEV Community and was authored by Mage
TLDR
Without good performance, machine learning (ML) models won’t provide much value in real life. We’ll introduce some common strategies to improve model performance including selecting the best algorithm, tuning model settings, and adding new features (aka feature engineering).
Outline
- Introduction
- Is the model good or bad?
- Strategies for improving the model
- When to stop improving the model
- Conclusion
Introduction
With the right developer education (e.g. Building your first machine learning model, it’s easy to start training machine learning models. However, it’s difficult to get great results on the first try that meets your product goals. After training the model, it can take a long time to tune the model and improve performance (we’ll use tuning model and improving model performance interchangeably in this article). Different types of models have different tuning strategies. In this article, we’ll introduce common strategies for model tuning.
Is the model good or bad?
Before tuning the model, we first need to know whether the model performance is good or bad. If you don’t know how to measure a model’s performance, you can check our previous blog articles: The definitive guide to Accuracy, Precision, and Recall for product developers and A product developer’s guide to ML regression model metrics.
Each model has baseline metrics. As introduced in our previous article, we can use “mode category” as the baseline metric for classification models. If your model’s performance is better than the baseline metric, then congratulations, your model isn’t bad and you’re off to a good start. If the model’s performance metrics are worse than the baseline metrics, it means the model doesn’t find valuable insights from the data. Then, there’ll be a lot to do in order to improve the performance.
Another scenario is when the model performs “too good”, e.g. 99% precision and 99% recall. This isn’t a good sign and probably indicates some issues in your model. The possible reason is “data leakage”. We’ll talk about how to solve this problem in the “Remove data leakage features” section.
Strategies for improving the model
Generally, there are 3 directions for model tuning: select a better algorithm, tune model parameters, and improve data.
Compare multiple algorithms
Comparing multiple algorithms is a straightforward idea to improve the model performance. Different algorithms are better suited for different types of datasets. We can train them all together and find the one with the best performance. For example, for classification models, we can try Logistic Regression, Support Vector Machine, XGBoost, Neural Network, etc.
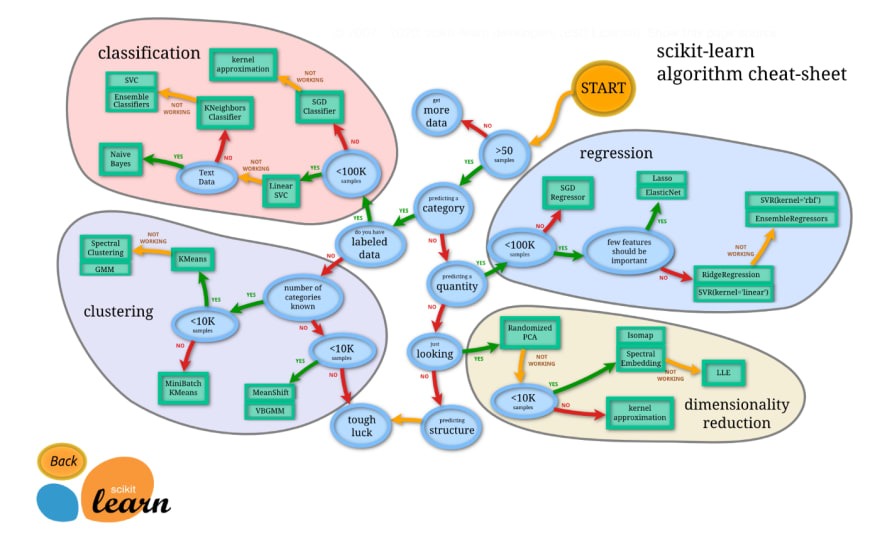 (Source: https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html)
(Source: https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html)
Hyperparameter tuning
Hyperparameter tuning is a common approach to tune models. In machine learning models, there are some parameters chosen before the learning process starts, which are called hyperparameters. Some examples are the maximum depth allowed for decision tree, and the number of trees included in random forest. Hyperparameters will influence the outcome of the learning process. Hyperparameter tuning is choosing the optimal set of parameters so that we can get optimal outcomes from the learning process.
 (Source: Slideshare
(Source: Slideshare
{kind=link}
We recommend using publicly available libraries to help with hyperparameter tuning, e.g. optuna. We’ll have a separate article for hyperparameter tuning in the future.
Trade precision with recall
For classification models, we usually measure the model performance with 2 metrics: precision and recall. Depending on the problem, you may want to optimize for either precision or recall. There’s a quick way to tune models to make a trade-off between the 2 metrics. Classification model predicts the probability of a label class. We can simply increase or decrease the probability threshold to get higher precision or recall.
For example, if we build a model to predict whether a passenger survives in the Titanic disaster, the model can predict the probability of the passenger living or dying. If the probability is above 50%, the model will predict that the passenger will survive. Otherwise, the model will predict the passenger won’t survive. If we want a higher precision, we can increase the probability threshold. Then, the model will predict fewer passengers surviving but will be more precise. If we want to increase recall and cover more passengers that’ll possibly survive, we can decrease the probability threshold.

Feature engineering
Besides selecting the best algorithm and tuning parameters, we can generate more features from existing data, which is called feature engineering.
Create new features
Creating new features requires some domain knowledge and creativity. Here are some examples of newly created features:
Create a feature for counting the number of letters in the text.
- Create a feature counting the number of words in a text.
- Create a feature that understands the meaning of the text (e.g. word embeddings).
- Aggregate user event count over the past 7 days, 30 days, or 90 days.
- Extract “day”, “month”, “year”, and “days since holiday” features from a date or timestamp feature.
Enrich training data with public datasets
When you exhaust your ideas of generating new features from existing datasets, another idea is to get features from public datasets. For example, you want to build a model to predict whether a user will convert to membership but you don’t have too much user information in your datasets. However, you find the dataset contains ‘email’ and ‘company’ columns. Then you can get user and company data from a third-party, including user location, user age, company size, etc. This data can be used to enrich your training data.
 Third-party, but I guess enriched data is worth celebrating. (Source: Tenor)
Third-party, but I guess enriched data is worth celebrating. (Source: Tenor)
{kind=link}
Feature selection
It’s not always good to add more features. Removing irrelevant and noisy features could help reduce model training time and improve model performance. There are multiple feature selection methods in scikit-learn that can be used to get rid of irrelevant features.
Remove data leakage features
As we mentioned earlier, 1 scenario is that the model’s performance is “too good”. However, when you deploy the model and use it in production, you get very poor performance. The possible reason for this issue is “data leakage”, which is a common pitfall for model training. Data leakage means we use some features that happen after the target variable and contain the information of the target variable. In real life, we won’t have those data leakage features when we make predictions.
For example, you want to predict whether or not a user will open an email but your features include whether or not the user clicked on the email. A user can only click the email if they opened it. If the model sees that a user clicked it, then it will 100% predict they will open it. The problem is in a real life scenario, we can’t know whether someone will click an email before they open the email.
 Remove data leakage! (Source: Tenor)
Remove data leakage! (Source: Tenor)
{kind=link}
We can debug the data leakage issue with SHAP values. With the SHAP library, we can plot the chart to show features with the most impact and how they impact the model’s output directionally. If the top features are highly correlated with the target variable and have very high weights, they’re potentially data leakage features and we can remove them from the training data.

More data
Last but not least, getting more training data is an obvious and efficient way to improve model performance. More training data enables the model to find more insights and get better accuracy.
 More data! (Source: Giphy)
More data! (Source: Giphy)
{kind=link}
When to stop improving the model
Knowing when to stop is a tough question with no perfect answer. There’s no hard stopping point for model tuning.
There could always be new ideas to bring on new data, create new features, or tune algorithms. The bare minimum criteria is that the model performance should at least be better than baseline metrics. Once we meet the minimum criteria, this is the process we recommend for improving models and deciding when to stop:
- Try all the strategies to improve models.
- Compare the model performance with some other metrics you have to verify whether the model metrics make sense.
- After doing several rounds of model tuning, evaluate whether it’s worth spending time trying new ideas with the improvements you get.
- If the model performs well and you can barely get improvements after trying out a handful of ideas, deploy the model to production and measure the performance in production.
- If the performance is similar between production and training, then your model is good to go. If the production performance is worse than the performance in training, that indicates some issues in the training. The issues could be the model is overfitting the training data, or the model has data leakage issues. You’ll need to go back and further tune the model.
Conclusion
Model tuning is a lengthy and repetitive process to test new ideas, retrain the model, evaluate the model, and compare the metrics. If you wonder how this process can be simplified, stay tuned for future articles about how Mage can help you improve models.
This content originally appeared on DEV Community and was authored by Mage
Mage | Sciencx (2021-09-16T19:21:07+00:00) How to improve the performance of a machine learning (ML) model. Retrieved from https://www.scien.cx/2021/09/16/how-to-improve-the-performance-of-a-machine-learning-ml-model/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.