
This content originally appeared on DEV Community and was authored by swyx
Watching recent trends in client-server paradigms, from Apollo GraphQL to React Server Components to Rails Hotwire, I've had a revelation that helped me make sense of it all: They're all abstractions over REST!
There are two schools of thought:
-
Smart Client: State updates are rendered clientside first, then sent back to the server.
- You can roll your own: Use a state management solution like Redux or Svelte Stores and handwrite every piece of the client-server coordination logic.
- You can use libraries that combine state and data fetching: Apollo Client, React Query, RxDB, GunDB, and Absurd-SQL all do dual jobs of fetching data and storing related state.
- You can use frameworks that abstract it away for you: Blitz.js and Next.js
- Or you can take it off the shelf: Google's Firebase and AWS' Amplify/AppSync are fully vendor provided and vertically integrated with backend resources like auth, database, and storage (arguably MongoDB Realm and Meteor's minimongo before it)
- Smart Server: State updates are sent to the server first, which then sends rerenders to the client (whether in HTML chunks, serialized React components, or XML).
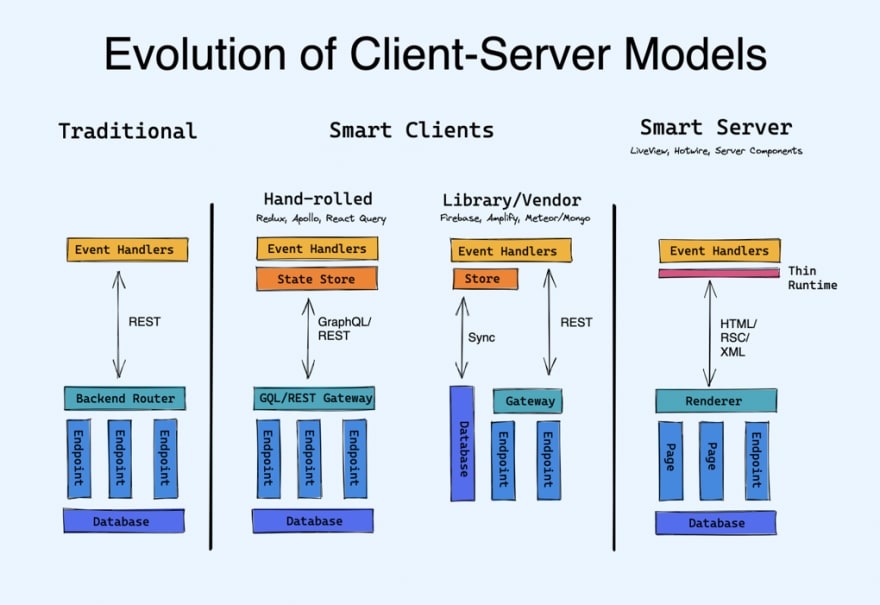
Of course the "Smart Server" paradigm isn't wholly new. It has a historical predecessor — let's call it the "Traditional Server" paradigm. The Wordpress, Django, Laravel type frameworks would fill out HTML templates and the browser's only job is to render them and send the next requests. We gradually left that behind for more persistent interactive experiences with client-side JS (nee AJAX). For a long time we were happy with just pinging REST endpoints from the client, ensuring a clean separation of concerns between frontend and backend.
So why are we tearing up the old client-server paradigm? And which side will win?
It's about User Experience
Ironically, the two sides have very different goals in UX and would probably argue that the other is less performant
- Smart clients enable offline-first apps and optimistic updates so your app can keep working without internet and feels instant because you are doing CRUD against a local cache of remote data (I wrote about this in Optimistic, Offline-First Apps).
- This improves perceived performance for apps.
- However their downside is tend to come with large JS bundles upfront: Firebase adds as much as 1mb to your bundle, Amplify got it down to 230kb after a lot of modularization effort, Realm stands at 42kb.
- Smart servers directly cut JS weight by doing work serverside rather than clientside, yet seamlessly patching in updates as though they were done clientside. Facebook has reported as high as 29% bundle reduction.
- This improves first-load performance for sites.
- However their downside is that every single user of yours is doing their rendering on your server, not their browser. This is bound to be more resource intensive. The problem is mitigated if you can easily autoscale (eg with serverless rendering on Cloudflare Workers or AWS Lambda). There are also real security concerns that should get ironed out over time.
The "winner" here, if there is such, will depend on usecase - if you are writing a web app where any delay in response will be felt by users, then you want the smart client approach, but if you are writing an ecommerce site, then your need for speed will favor smart servers.
It's about Developer Experience
- Platform SDKs. For the Frontend-Platform-as-a-Service vendors like Firebase and AWS Amplify, their clients are transparently just platform SDKs — since they have total knowledge of your backend, they can offer you a better DX on the frontend with idiomatic language SDKs.
- Reducing Boilerplate for Invocations. Instead of a 2 stage process of writing a backend handler/resolver and then the corresponding frontend API call/optimistic update, you can write the backend once and codegen a custom client, or offer what feels like direct database manipulation on the frontend (with authorization and syncing rules).
-
Offline. Both Firebase Firestore and Amplify AppSync also support offline persistence. Since they know your database schema, it's easy to offer a local replica and conflict resolution. There are vendor agnostic alternatives like RxDB or Redux Offline that take more glue work.
- Being Offline-first requires you to have a local replica of your data, which means that doing CRUD against your local replica can be much simpler (see below).
-
Reducing Boilerplate for Optimistic Updates.
- When you do normal optimistic updates, you have to do 4 things:
- send update to server,
- optimistically update local state,
- complete the optimistic update on server success,
- undo the optimistic update on server fail
- With a local database replica, you do 1 thing: write your update to the local DB and wait for it to sync up. The local DB should expose the status of the update (which you can reflect in UI) as well as let you centrally handle failures.
- When you do normal optimistic updates, you have to do 4 things:
-
People. This is an organizational, rather than a technological, argument. How many times have your frontend developers been "blocked by backend" on something and now have to wait 2-3 sprints for someone else to deliver something they need? It is hugely disruptive to workflow. Give the developer full stack access to whatever they need to ship features, whether it is serverless functions, database access or something else. Smart Clients/Servers can solve people problems as much as UX problems.
- This is why I am a big champion of shifting the industry divide from "frontend vs backend" to "product vs platform". Chris Coyier's term for this is The All-Powerful Frontend Developer.
- GraphQL is also secretly a "people technology" because it decouples frontend data requirements from a finite set of backend endpoints.
Both smart clients and smart servers greatly improve the DX on all these fronts.
It's about Protocols
Better protocols lead to improved UX (eliminating user-facing errors and offering faster updates) and DX (shifting errors left) and they're so relevant to the "why are you avoiding REST" debate that I split them out to their own category. Technically of course, whatever protocol you use may be a layer atop of REST - if you have a separate layer (like CRDTs) that handles syncing/conflict resolution, then that is the protocol you are really using.
A lot of these comments will feature GraphQL, because it is the non-REST protocol I have the most familiarity with; but please feel free to tell me where other protocols may fit in or differ.
-
Type Safety: GraphQL validates every request at runtime. trpc does it at compile time.
- Increased type annotation offers better codegen of client SDKs that you would otherwise have to hand-write. This is a much more established norm in gRPC than GraphQL and I'm not sure why.
-
Bandwidth: Sending less data (or data in a format that improves UX) over the wire
- GraphQL helps solve the overfetching problem. In practice, I think the importance of this is overhyped unless you are Facebook or Airbnb. However the usefulness of persisted queries for solving upload bandwidth problems is underrated.
- Hotwire sends literal HTML Over The wire
- React Server Components sends serialized component data over the wire; more compact because it can assume React, and smoothly coordinated with on-screen loading states
-
Real-time: offering "live" and "collaborative" experiences on the web
- This is doable with periodic polling and long-polling, but more native protocols like UDP, WebRTC and WebSockets are probably a better solution
- Replicache (used for Next.js Live) and Croquet look interesting here
- UDP itself seems like a foundation that is ripe for much more protocol innovation; even HTTP/3 will be built atop it
There remain some areas for growth that I don't think are adequately answered yet:
- Performance: One nightmare of every backend developer is unwittingly letting a given user kick off an expensive query that could choke up system resources. Complexity budgets are not a solved problem in GraphQL. It's a touchy subject, but new protocols can at least open up a more interesting dance between performance and flexibility.
- Security: allowing frontend developers direct database access requires much more guard rails around security. Vendors with integrated auth solutions can help somewhat, but the evangelists for a new protocol need to be as loud about their security requirements as they are the developer experience upsides.
Not Everyone is Anti-REST
Yes of course my title is a little clickbaity; REST is perfectly fine for the vast majority of webdevs. There are even people pushing boundaries within the REST paradigm.
- Remix, the soon-to-be-launched React metaframework from the creators of React Router, embraces native browser standards so you get progressive enhancement "for free", for example requiring that you POST from a HTML form.
- Supabase (where I am an investor) is a "smart client" solution that works equally well on the server, which invests heavily in the open source PostgREST project.
Reader Feedback
- Jonathan W: "The framing of the issue got my brain percolating a bit. The entire situation feels very similar to the first time a developer recognizes object-relational impedance mismatch—all the subtle differences that start to crop up as you layer an Application Framework on top of an ORM on top of an RDBMS on top of your business domain (you know, that kind of important topic). Each layer of abstraction is acceptable by itself, but the effects compound at each level and over time."
This content originally appeared on DEV Community and was authored by swyx
swyx | Sciencx (2021-09-20T14:46:38+00:00) Why do Webdevs keep trying to kill REST?. Retrieved from https://www.scien.cx/2021/09/20/why-do-webdevs-keep-trying-to-kill-rest/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.