
This content originally appeared on Level Up Coding - Medium and was authored by Yurii A
Abstractions do leak when dealing with performance-critical applications. In this case, a developer cannot treat a computer as a black box anymore. Instead, one should have a solid understanding of what’s happening behind the scenes. This story illustrates how proper usage of concurrency, computer architecture and algorithms knowledge can tremendously speed up your program if used properly.

C++concurrency is a tricky thing. While giving you the incredible power of boosting your application, it does not restrain you from writing multi-threaded code that is much slower than its sequential version. To identify the potential bottlenecks, we have to know what should/shouldn’t be done in a multi-threaded setup and, most importantly, why it is the case. So let’s get started!
Problem Statement
Recently I received an innocent-looking test task. Please read it carefully, as we will exploit every piece of the statement in the final solution.
“Write a program that counts the number of distinct words in a given file. The input text is guaranteed to contain only ‘a’…’ z’ letters and space characters in ASCII encoding”.
What first seems like a breeze becomes an exciting adventure with only two extra conditions added:
- The program should be able to handle large inputs (i.e. 32GB).
- The solution must utilize all available CPU resources.
Baseline
To have some baseline to compare to, let’s write the most straightforward sequential solution possible:
That’s KISS in its ultimate form: read by words, put them in a set. This piece of code is neither concurrent nor optimal, but it’s a good place to start. We should not overcomplicate things until we genuinely know our needs.
Concurrency Attempt
Let’s add some concurrency into the mix. We should first decouple reading the words from their processing. Doing that should reduce the critical path and overall runtime of the application. I opted for implementing a single producer/multiple consumer pattern with the following threads:
- Reader — reads a file by chunks of words. Each chunk is represented as a vector of strings and is put on the producer’s queue.
- Producer — forms a set of unique words out of each chunk and puts it on the shared consumers’ queue.
- Consumer — while there are more than two elements in the consumers’ queue, merges the first two sets of unique words and puts the resulting one back.
Implementation is a bit cumbersome, but still no rocket science. Some general remarks:
- I use death pills as an inter-thread communication mechanism. These special queue elements indicate that nobody will push anything back on the container anymore. The pill can be present at most once, strictly at the end of the queue. That means that if the front element is the death pill, there are no more items to process.
- Critical sections should be as short as possible. We might check if the front element is the death pill while holding the mutex, but it doesn’t make much sense. Because we expect the elements to be ordinary for most cases, we should quickly steal the front item, release the mutex and process the resulting element without synchronization. And when it happens to be the death pill, we acquire the lock again and move it back.
- Use RAII wrappers for mutexes. When no fine-grained control is needed, std::scoped_lock is an excellent choice. It implies little to no overhead compared to lock/unlock semantics. Moreover, you no longer care about exception safety since the mutex is released automatically during stack unwinding.
- Use move semantics.
- Make sure you know how containers work in-depth.
Results
Here are the timing results. The baseline and producer/consumer approaches were tested on two sets of synthetically generated files: short and long words, with the words having a different mean length in each group. The table also provides the time spent by the reader thread in the producer/consumer algorithm (see Reading Time column):
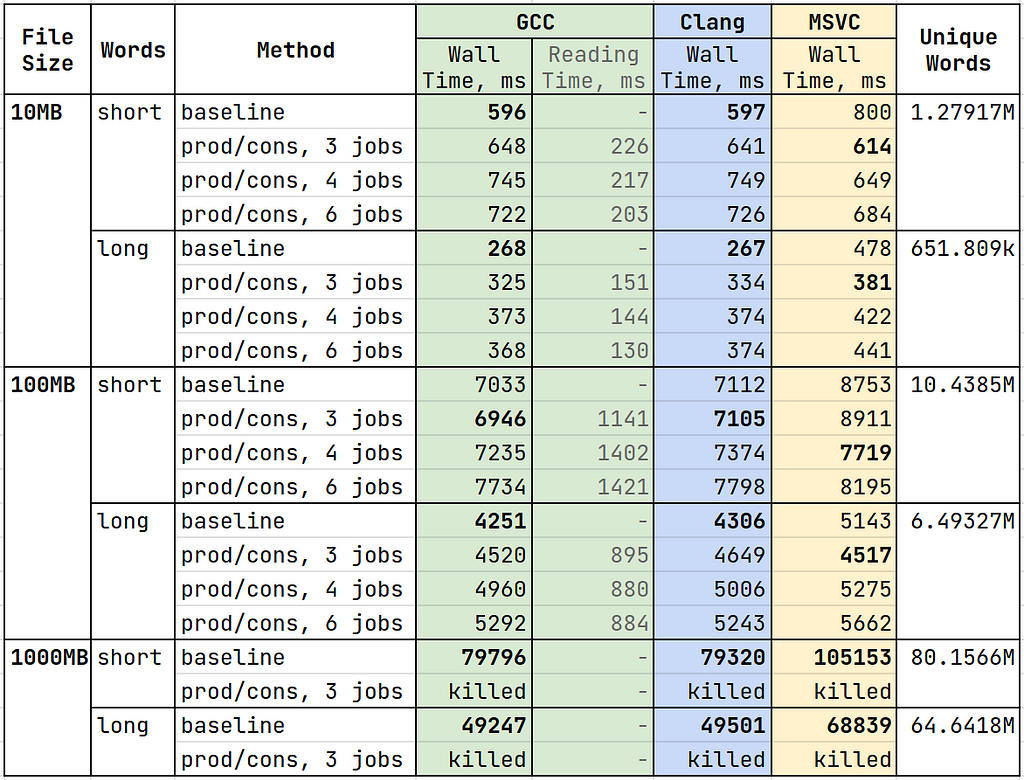
Wait, what? Shouldn’t the producer/consumer solution be much faster than the baseline? Shouldn’t performance improve with the number of threads? Well, the numbers don’t lie. Introducing the concurrency made the program worse, especially for big files! Here are some observations before we move on:
- the methods are far from being bounded by hard drive reading speed
- wall time seems to depend on the number of unique words instead of file size
- 16GB of RAM is not enough for 1000MB files when using the producer/consumer approach
- we don’t benefit from multiple consumer threads
Small Note on Benchmarking
Changing the order of benchmarks may sometimes significantly affect timing results. In my case, it was due to branch prediction. Because short and long words have different statistical properties, the branch deciding whether the next character is a space fails to predict when changing the words’ distribution. To overcome the issue, make sure to run enough iterations or split the benchmarks into two executables if the former is infeasible.
Analysis
Memory Management
So what’s wrong with the concurrent approach? There are no long critical sections, and every thread should have pretty much work to do. There are also no copies since move semantics is used extensively. The experienced programmers might already know the answer, but let’s step back and analyze what every thread is doing:
- Reader: reads strings, puts them in a vector. Vector stores its elements on the heap.
- Producer: puts the strings from vector into an unordered set. Similarly to the vector, the hash table is also allocated on the heap.
- Consumer: merges two unordered sets. Since we are again dealing with hash tables, we have lots of heap memory allocations.
But the threads are still running in parallel, right? Technically yes, but here is a catch: the heap is not parallelizable! We can’t have two simultaneous allocations unless we use system-dependent API or reserve pools of raw memory beforehand. Since no thread does pretty much anything else apart from implicit heap memory allocations under the hood of containers, the second solution is not parallel at all. Because we do more work with sets as opposed to a baseline example and inter-thread communication is not free of charge, all these factors add up to the resulting performance. It also explains why it gets worse with more threads (observation no. 4).
Unordered Set Performance
We know that std::unordered_set uses a hash table under the hood. But what exactly happens there? Well, every bucket of the table is a singly linked list! When inserting the new element, we first find the right bucket using the object’s hash value. Then we traverse the linked list of items inside the chosen bucket to examine whether the element has already been present. If not, we allocate a node, put the element there, and append the node to the list. The set grows when the average number of items per bucket is greater than 1. Sounds good? Here are some aspects to think about:
- Memory allocations. Not only do we allocate the memory for the buckets, but also for the list nodes on every insertion. While the former allocations don’t happen too often, the latter are triggered much more frequently given enough unique words. This essentially kills the parallelism due to the reasons discussed above.
- Unused buckets. We might accidentally “hack” the hash table to use only a fraction of its buckets. For example, the unordered set of even numbers will have only half of its buckets occupied. It’s even possible for all the items to end up in a single bucket if we get really unlucky. The key takeaway is that the hash function should have good statistical properties and produce evenly distributed values.
- Memory access pattern, cache locality. The linked lists are incredibly horrible to traverse compared to contiguous containers. Since the CPU does not operate with individual bytes but rather 64-byte long cache lines, it is lightning fast to access subsequent elements because they are already in cache. Moreover, the hardware will detect the sequential memory access pattern and speculatively prefetch the following cache lines to reduce the latency. Unfortunately, the linked list cannot benefit from all that jazz. Because nodes are randomly scattered across the heap, you will get a cache miss on every element and resort to dealing with RAM, which is a hundred times!!! slower than the L1 cache. To verify this indeed may be an issue, I profiled the baseline implementation with cachegrind. There was a considerable amount of L1 data misses coming from traversing the contents of the buckets.
Now we understand why file reading is not yet a bottleneck and why the resulting time depends on the number of words in the file (observations no. 1 & 2).
Other Potential Problems
- Can we read faster? Iostreams are known to be slow, so we may try to do better. Moreover, we haven’t actually decoupled file reading from words processing since iostreams read by words.
- Better queues? Why should we block two threads if they want to access the elements from different sides? We should try using lock-free queues. Despite atomics being more expensive than mutexes, they might deliver better per-thread performance. But of course, this should be profiled.
- Do we even need std::string?
Optimizing the Baseline
Let’s backtrack a bit. We have decided on the things to aim for: cache locality, fewer heap allocations, custom scanning, lock-free queues. Since none of these is trivial, let’s gradually improve the sequential solution and introduce concurrency afterwards.
Custom Scanning
Since files operations are lengthy, we should read big raw buffers of data and break them into words by hand. The only corner case is when the word is on the boundary of two buffers. Let’s stick with a standard hash set implementation for now and see whether the manual reading alone can make a difference.
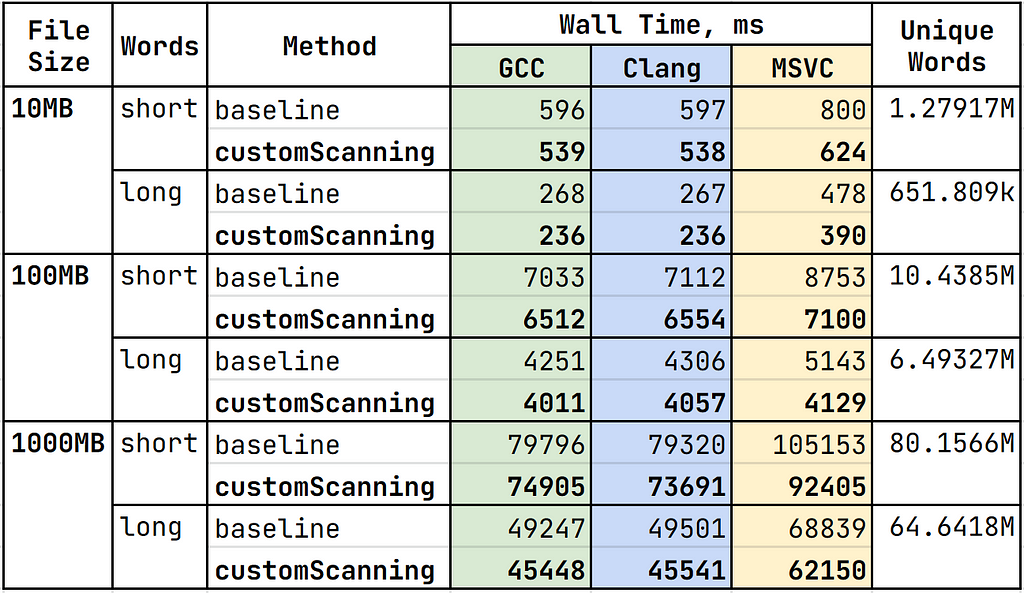
We get 6–12% improvement from manual reading alone. Given the fact that iostreams do something similar under the hood, we should not expect more. We can also try doing memory mapped io to avoid copying the characters from kernel to user space, but it’s out of the scope of this story.
The implementation is not that hard: read the file into the buffer, handle corner cases (first and last words + a rare possibility for the word to span across the whole buffer). The only interesting part is the hot loop where we deal with regular words:
Here is why custom scanning may be faster:
- Few conditions inside the loop. There are no end conditions (I append trailing symbols to the end of the buffer). std::strpbrk is used to look for the space characters (which uses intrinsics under the hood). There is rarely more than one space between the words, so the corresponding loop is marked as unlikely.
- String construction is forwarded to std::unordered_set. In the baseline implementation, we had one or two constructions (reading from the stream + move constructor into the set). Here we always have only one string construction inside the set.
Better Set
We have suspected std::unordered_set to be a bottleneck because of bad cache locality and lots of heap allocations. To mitigate them, we can try using open address hashing with linear probing (you can find my implementation here). It exploits data locality and allocates memory only upon rehashing. The general idea is super-simple:
- Each bucket can contain only one element. That means we only work with an array of buckets. No nodes, pointers or extra allocations.
- When adding the new element, we first choose the bucket to put it into. If it is already occupied, we move to the next one. We continue until we find an empty bucket and put the new element there. Since we examine the neighbouring buckets, it should be fast since they are already in cache.
Let’s compare it against std::unordered_set when inserting the words from the buffer:
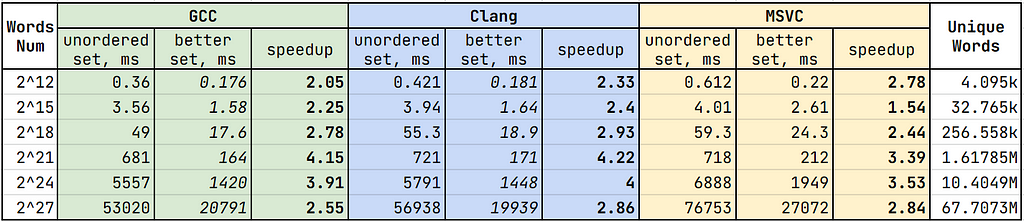
Much better. We see the open addressing set being at least twice as fast compared to std::unordered_set across all compilers in various conditions. Here are the tricks that helped me achieve such results:

- Bucket structure. Because most of the English words are not too long, I designed a bucket to be optimized for this particular scenario. Twenty-two characters are more than enough for almost every word (long words are handled separately). Moreover, the bucket perfectly fits into half of the cache line, having 32 bytes in size. Thereby we have constructed a custom version of the string that occupies 32 bytes together with the hash (as opposed to std::string, which often occupies the same amount of memory without the hash).
- Hash function sensitivity. Wikipedia says that open addressing hashing with linear probing works best with murmur hash. I can confirm it from my tests. Changing the hash function seems to degrade the performance.
- Don’t wait until it gets full. When the open addressing set is almost full, insertion/lookup operations turn into a linear search, which should be avoided as much as possible. The container should remain sparse. Hence, the solution is to rehash when more than 90% of the buckets are occupied.
- Don’t copy into the bucket until there is a real need. Because we emplace the words from the buffer, we can at first determine whether the word is already present by computing the hash from the buffer. Then we copy the word into the bucket if and only if it hasn’t been present. On the contrary, std::unordered_set constructs the std::string on every insertion.
Optimized Baseline
Let’s combine the two previous approaches into one:
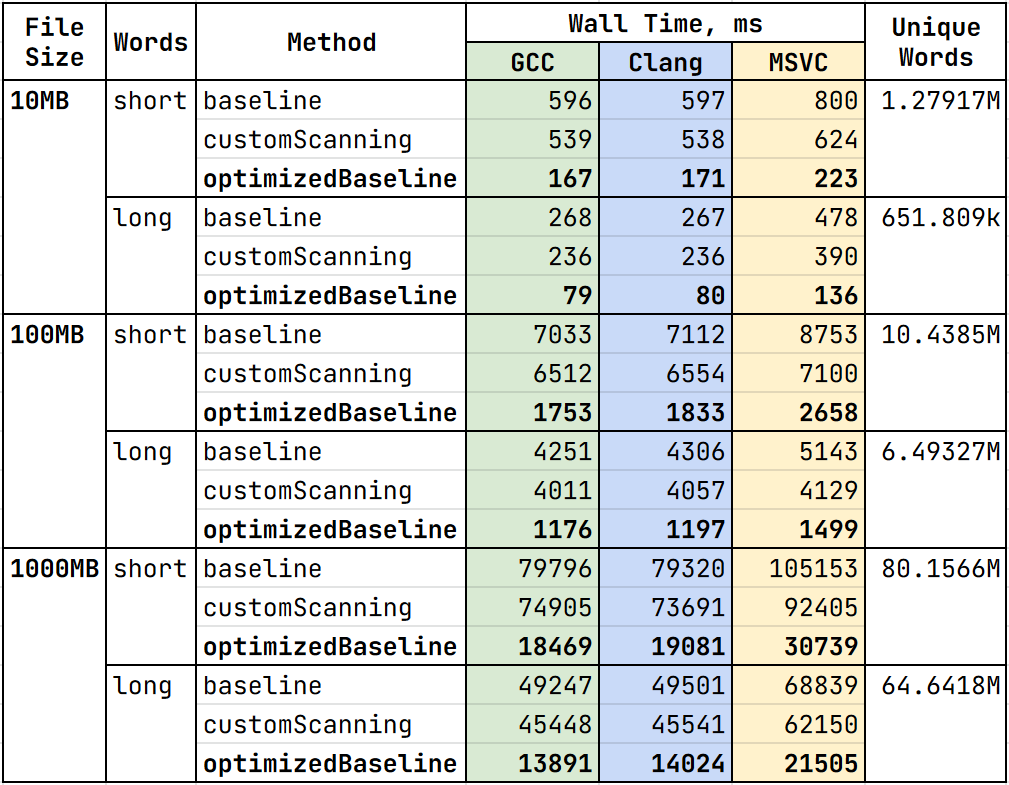
Adding Concurrency
Since the first attempt on concurrency went pretty bad, I will compare the methods against a more practical approach: using multiple consumers with a single tbb::concurrent_unordered_set. It is a part of the Intel TBB library, which provides containers optimized for concurrent use. I haven’t investigated the implementation, but it seems to be using bucket-wise locking, which allows for simultaneous insertion.
The idea of the concurrentSetProducerConsumer approach is pretty straightforward: there is a single producer thread, which reads the data as big raw buffers. Multiple consumer threads process the buffers using the custom scanning routine described above. The words are inserted into the shared instance of tbb::concurrent_unordered_set.
Introducing Concurrency to Optimized Baseline
Because of the non-concurrent nature of the open addressing set, it would be hard to take advantage of multiple threads. But there are still some corners we can cut. The following tasks can be executed simultaneously:
- Reading from the file into the buffer
- Scanning the buffer for words
- Rehashing the resulting set
Consequently, the optimizedProducerConsumer approach uses three threads:
- Scanner: reads the file into big raw buffers
- Producer: reads the buffer using the custom scanning routine. Unique words are placed into small open addressing set with a fixed capacity of 1024 buckets. Once the set is filled up, it is scheduled for consumption and replaced with a new one.
- Consumer: merges all sets retrieved by the producer into one (by doing this, we don’t block the producer thread when rehashing occurs)
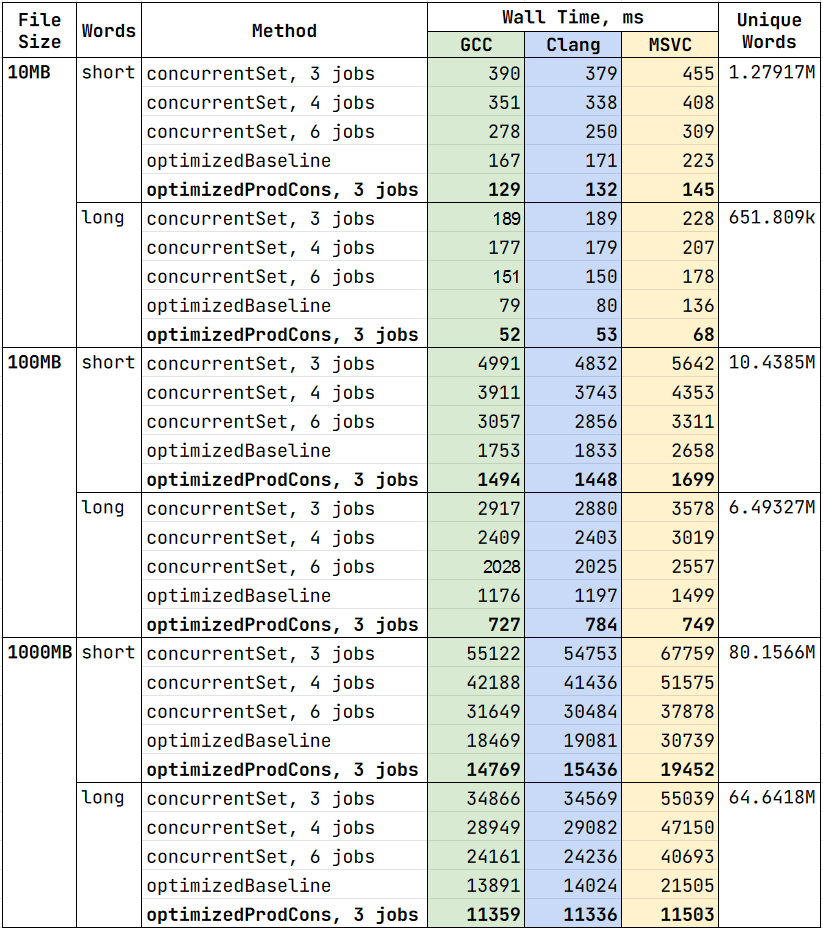
Observations:
- concurrentSetProducerConsumer scales with the number of threads but lacks cache locality
- operations with open addressing set is still a bottleneck and should be optimized further
Further Steps
We have saved another 20%, but we can’t take advantage of more than three threads. If only we could combine the nature of the concurrent unordered set with a cache locality of the open addressing set. It turns out that it might be possible. When deciding on the bucket index for the open addressing set, we use the least significant hash bits. We can spawn multiple instances of the open addressing set and have a one to one correspondence between the word and a set it goes into based on the most significant bits of the hash. Hence, we can have a distributed open addressing set and launch multiple consumer threads that don’t depend on each other. I have already experimented with it a bit. Murmur hash seems to have good statistical properties (i.e. words are evenly distributed among the sets based on the most significant bits). However, this approach requires using per-thread memory pools to handle concurrent allocations, which is slightly out of my league for now. I hope to share the results in the future.
Closing Remarks
Even the most straightforward task can be turned into an exciting cognitive adventure when put into the high-performance perspective. I don’t regret accepting the challenge since it helped me learn new things, refresh my knowledge of algorithms/computer architecture and work on the particular case where it is critical for performance.
The code for the methods, benchmarks and tests is available on Github. Feel free to investigate it or leave improvement suggestions.
Here are the talks that have inspired me along the way:
- Chandler Carruth: “Efficiency with Algorithms, Performance with Data Structures”, CppCon 2014
- Scott Meyers: “Cpu Caches and Why You Care”, code::dive 2014
- Andrei Alexandrescu: “Writing Fast Code”, code::dive 2015 (Part 1, Part 2)
- Timur Doumler: “Want fast C++? Know your hardware!”, CppCon 2016
- Chandler Carruth: “Going Nowhere Faster”, CppCon 2017
Complex Solution to a Dead Simple Concurrency Task was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Yurii A
Yurii A | Sciencx (2021-09-28T12:33:21+00:00) Complex Solution to a Dead Simple Concurrency Task. Retrieved from https://www.scien.cx/2021/09/28/complex-solution-to-a-dead-simple-concurrency-task/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.