
This content originally appeared on DEV Community and was authored by prasanth mathesh

Introduction
The python, java etc applications can be containerized as a docker image for deployment in AWS Lambda and AWS EKS using the AWS ECR as container registry. The spark framework commonly used for distributed big data processing applications supports various deployment modes like local, cluster, yarn, etc. I have discussed serverless data processing architecture patterns in my other articles and in this, we will see how one can build and run a Spark data processing application using AWS EKS and also serverless lambda runtime. The working version code used for this article is kept in Github
Requirements
The following are the set of client tools that should be already installed in the working dev environment.
AWS CLI, Kubectl, Eksctl, Docker
One should ensure the right version for each set of tools including the spark, AWS SDK and delta.io dependencies.
Kubernetes Deployment
AWS EKS anywhere which was launched recently can enable organizations to create and operate Kubernetes clusters on customer-managed infrastructure. This new service by AWS is going to change the way of scalability, disaster plan and recovery option that are being followed for Kubernetes currently.
The following are the few native Kubernetes deployments since containerized applications will run in the same manner in different hosts.
1.Build and test application on-premise and deploy on the cloud for availability and scalability
2.Build, test and run applications on-premise and use the cloud environment for disaster recovery
3.Build, test and run application on-premise, burst salves on the cloud for on-demand scaling
4.Build and test application on-premise and deploy master on a primary cloud and create slaves on secondary cloud
For ever-growing,data-intensive applications that process and store terabytes of data, RPO is critical and its better to use on-premise dev and cloud for PROD
Spark on Server
Local
First, let's containerize the application and test it in the local environment.
The pyspark code used in this article reads a S3 csv file and writes it into a delta table in append mode. After the write operation is complete, spark code displays the delta table records.
Build the image with dependencies and push the docker image to AWS ECR using the below command.
./build_and_push.sh cda-spark-kubernetes
After the build, the docker image is available in the local dev host too which can be tested locally using docker CLI
docker run cda-spark-kubernetes driver local:///opt/application/cda_spark_kubernetes.py {args}
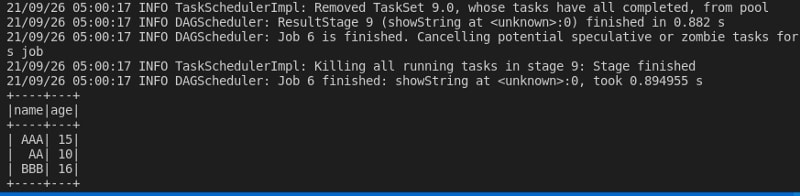
The above image shows the output of the delta read operation
AWS EKS
Build AWS EKS cluster using eksctl.yaml and apply RBAC role for spark user using below cli.
eksctl create cluster -f ./eksctl.yaml
kubectl apply -f ./spark-rbac.yaml
Once the cluster is cluster is created, verify nodes and cluster IP.

The above is a plain cluster that is ready without any application and its dependencies.
Install spark-operator
Spark Operator is an open-source Kubernetes Operator to deploy Spark applications. Helm is similar to yum, apt for K8s and using helm, spark operator can be installed.
Install spark-operator using below helm CLI
helm repo add spark-operator https://googlecloudplatform.github.io/spark-on-k8s-operator
helm install spark-operator spark-operator/spark-operator --set webhook.enable=true
kubectl get pods

The containerized spark code can be submitted from a client in cluster mode using spark operator and its status can be checked using kubectl cli.
Run the spark-job.yaml that contains config parameters required for the spark operator in the command line.
kubectl apply -f ./spark-job.yaml
The cli to get application is given below
kubectl get sparkapplication

The cli to get logs of the spark driver at the client side is given below.
kubectl logs spark-job-driver
The delta operation has done the append to the delta table and it's displayed on driver logs as given below.

Additionally, the driver Spark-UI can be forwarded to the localhost port too.

The Kubernetes deployment requests driver and executor pods on demand and shuts them down once processing is complete. This pod level resource sharing and isolation is a key difference between spark on yarn and kubernetes
Spark on Serverless
Spark is a distributed data processing framework that thrives on RAM and CPU. Spark on AWS lambda function is suitable for all kinds of workload that can complete within 15 mins.
For the workloads that take more than 15 mins, by leveraging continuous/event-driven pipelines with proper CDC, partition and storage techniques, the same code can be run in parallel to achieve the latency of the data pipeline.
The base spark image used for AWS EKS deployment is taken from the docker hub and it is pre-built with AWS SDK and delta.io dependencies.
For AWS Lambda deployment, AWS supported python base image is used to build code along with its dependencies using the Dockerfile and then it is pushed to the AWS ECR.
FROM public.ecr.aws/lambda/python:3.8
ARG HADOOP_VERSION=3.2.0
ARG AWS_SDK_VERSION=1.11.375
RUN yum -y install java-1.8.0-openjdk
RUN pip install pyspark
ENV SPARK_HOME="/var/lang/lib/python3.8/site-packages/pyspark"
ENV PATH=$PATH:$SPARK_HOME/bin
ENV PATH=$PATH:$SPARK_HOME/sbin
ENV PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.9-src.zip:$PYTHONPATH
ENV PATH=$SPARK_HOME/python:$PATH
RUN mkdir $SPARK_HOME/conf
RUN echo "SPARK_LOCAL_IP=127.0.0.1" > $SPARK_HOME/conf/spark-env.sh
#ENV PYSPARK_SUBMIT_ARGS="--master local pyspark-shell"
ENV JAVA_HOME="/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.302.b08-0.amzn2.0.1.x86_64/jre"
ENV PATH=${PATH}:${JAVA_HOME}/bin
# Set up the ENV vars for code
ENV AWS_ACCESS_KEY_ID=""
ENV AWS_SECRET_ACCESS_KEY=""
ENV AWS_REGION=""
ENV AWS_SESSION_TOKEN=""
ENV s3_bucket=""
ENV inp_prefix=""
ENV out_prefix=""
RUN yum install wget
# copy hadoop-aws and aws-sdk
RUN wget https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-aws/${HADOOP_VERSION}/hadoop-aws-${HADOOP_VERSION}.jar -P ${SPARK_HOME}/jars/ && \
wget https://repo1.maven.org/maven2/com/amazonaws/aws-java-sdk-bundle/${AWS_SDK_VERSION}/aws-java-sdk-bundle-${AWS_SDK_VERSION}.jar -P ${SPARK_HOME}jars/
COPY spark-class $SPARK_HOME/bin/
COPY delta-core_2.12-0.8.0.jar ${SPARK_HOME}/jars/
COPY cda_spark_lambda.py ${LAMBDA_TASK_ROOT}
CMD [ "cda_spark_lambda.lambda_handler" ]
Local
Test the code using a local machine using docker CLI as given below.
docker run -e s3_bucket=referencedata01 -e inp_prefix=delta/input/students.csv -e out_prefix=/delta/output/students_table -e AWS_REGION=ap-south-1 -e AWS_ACCESS_KEY_ID=$(aws configure get default.aws_access_key_id) -e AWS_SECRET_ACCESS_KEY=$(aws configure get default.aws_secret_access_key) -e AWS_SESSION_TOKEN=$(aws configure get default.aws_session_token) -p 9000:8080 kite-collect-data-hist:latest cda-spark-lambda
The local mode testing will require an event to be triggered and AWS lambda will be in wait mode.

Trigger an event for lambda function using below cli in another terminal
curl -XPOST "http://localhost:9000/2015-03-31/functions/function/invocations" -d '{}'
Once AWS lambda is completed, we can see the output as given below in the local machine.

AWS Lambda
Deploy a lambda function using the ECR image and set necessary ENV variables for the lambda handler. Once lambda is triggered and completed successfully we can see the logs in cloud watch.

AWS Lambda currently supports 6 vCPU cores and 10 gb memory and it is billed for the elapsed run time and memory consumption as shown below.

The AWS Pricing is based on the number of requests and GB-Sec.
The same code is run for various configurations and it is evident from the below table that even if memory is overprovisioned, AWS lambda pricing methodology saves the cost.

Conclusion
Going forward, wider adoption to use containerized data pipelines for spark will be the need of the hour since sources like web apps, SaaS products that are built on top of Kubernetes generates a lot of data in a continuous manner for the big data platforms.
The most common operations like data extraction and ingestion in the S3 data lake, loading processed data into the data stores and pushing down SQL workloads on AWS Redshift can be done easily using AWS lambda Spark.
Thus by leveraging AWS Lambda along with Kubernetes, one can bring down TCO along with build planet-scale data pipelines.
This content originally appeared on DEV Community and was authored by prasanth mathesh
prasanth mathesh | Sciencx (2021-09-29T02:32:19+00:00) Spark as function - Containerize PySpark code for AWS Lambda and Amazon Kubernetes. Retrieved from https://www.scien.cx/2021/09/29/spark-as-function%e2%80%8a-%e2%80%8acontainerize-pyspark-code-for-aws-lambda-and-amazon-kubernetes/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.