
This content originally appeared on DEV Community and was authored by Vikas Solegaonkar
It was 3AM on a Monday. The team had experienced a sleepless weekend, trying to dig into a production failure. In just a few hours, the work week would begin, and we all knew that the world needed this application to work. It would be a disaster if this issue were not fixed before then.
But why did it fail? It worked last week. Why did it stop working today? A recent code change? But that was absolutely unrelated. We tested it - with all the rigor. We had setup the best test automation, topped with some manual tests as well. Even further, our microservices are scanned and reviewed by effective tools. Why then did it fail?
We started cursing our fate and the tools we used. Management started yelling at us. You said K8s is meant for resilience and it enables applications that can never fail. But we have seen more trouble than solution. Never use Open Source! And all that blah..
But after hours of struggle, fate smiled - just in time - and we discovered the problem with the YML configuration. Some progressive minded developer had not specified the version of the embedded opensource DB used in there - he had used a "latest" - hoping to get the best features as they are released. A new version was available, and that broke some existing functionality.
Hush! Our job was saved. We managed to resolve the issue and then crashed into the bed - as the world started using our application that was functioning as before.
The RCA
Does this sound familiar? I am sure it does. We have all seen disasters caused by misconfiguration in Kubernetes. The problem is in the power of the tool. With great power comes great responsibility.
There is so much that we configure in there, and there are very few developers who really understand these configurations well enough. Most of them make these configurations using other existing configurations - a copy/paste, with modifying some parts that make sense to them. Or the adventurous ones pick the YML files straight from some online tutorials - which were good to prove a point, but not mature enough for the production.
When we use infrastructure as code we tend to forget that it is also a piece of code, that should go through all the validation like a normal application code. It is often tempting to use shortcuts that work today. They work and get deployed into production. And we assume that they will work forever. But unfortunately, that is not the case with Kubernetes configurations.
The world is still new to the Kubernetes Patterns. Developers are still struggling their way though it - so are the admins. And too much of configuration goes into the system, making it easy for such errors to creep in. Worse still, most of these errors show their impact after a few days, or even months. The system works perfectly until it just collapses without any warning. This makes the task even more difficult
Common Problems
There is no end to our creativity, and our ability - to introduce newer and newer defects in the system. But there are some common issues that show up very often. Let us look at them one by one.
Default Namespace
This is a common mistake new developers make - when they pick the configurations from tutorials and blogs. Most of them are meant to explain the concept and syntax. To keep that simple, most of them skip the other complexities like namespace.
But any Kubernetes deployment should have a meaningful namespace in the architecture. If we miss it out by error, it can cause name clashes in future.
Deprecated API's
Kubernetes is going through an active development. Lot of developers across the globe are working hard on improving it and making it more and more resilient. An unfortunate consequence is that we have some API's getting deprecated in newer releases.
We need to identify and remove them before they begin failing in production.
Naked Pods
Kubernetes provides for "Deployments" - as a way to encapsulate pods and all that they need. But some lazy developers may want to skip this and deploy just the pod into Kubernetes.
Well, this may work today. But it is a bad practice, and will definitely lead to a disaster some day.
Namespace Sharing
When entities at different levels share the namespace, the lower entity can access neighbors of the higher entity - to probe the network.
For example, when a container is allowed to share its host's network namespace, it can access local network listeners and leverage it to probe the host's local network.
This is a security risk. Even if it is our own code, the minimal access principle recommends that this should not be allowed. When it comes to system security, we should never believe in anyone - not even ourselves.
Not Respecting the Abstraction
All communications between the containers should go through the layers of abstraction provided by Kubernetes. Communication between services has to go through the abstractions of ingress and service defined in the deployments.
Never run containers with root privilege. Never expose node ports from services, or access host files directly in code (using UID). Ingress should forward traffic to the service, not directly to individual pods.
Hardcoding IP addresses, or directly accessing the docker sockets, etc.. can lead to problems. Again, these won't break the system on the very first day. But it will show up sometime someday - when we just can't afford it.
Incorrect Image tags
This is a common disaster. Developers are often tempted to use "latest" - with the hope of improving continuously, getting the latest and best version available. Such a configuration can live in our system for many months. But, it can lead to a nasty surprise.
When an image tag is not descriptive (e.g. lacking the version tag like 1.19.8), every time that image is pulled, the version will be a different version and might break our code. Also, a non-descriptive image tag does not allow us to easily roll back (or forward) to different image versions. It is better to use concrete and meaningful tags such as version strings or an image SHA.
Believing in Defaults
This is another problem that shows up very often - when we are not very confident of a configuration, we tend to believe in the defaults. The memory/CPU allocation, min/max replica counts for auto scaling... these are some of the properties that are missed too often.
Datree
As we noted, there are too many configurations that go into the Kubernetes cluster. Helm tries to reduce this complexity, but makes things worse, when we try to configure Helm itself. It is impossible for a human to ensure the quality that we need in our production deployments.
We need some good tools that can automate this process, and help us with this end.
After some discussion on tech platforms, and a lot of Google / StackOverflow / YouTube, we found a few interesting tools. After comparing them, we chose Datree.
It is simple to set up and use. It can be easily integrated with most CI/CD tools. It helps us identify such issues much before they can cause a problem. It has a lavish free tier and does not lock in - all that we need in an ideal tool.
Let's check it out.
Installation
Installing the tool is quite easy and fast. Run the below command. We need the sudo permissions.
curl https://get.datree.io | /bin/bash
A few seconds, and we are ready to go! Most of us are uncomfortable running such a command - we should be. We can just check out the actual code that is executed by script. Just open the link
in the browser.
```bash
#!/bin/bash
osName=$(uname -s)
DOWNLOAD_URL=$(curl --silent "https://api.github.com/repos/datreeio/datree/releases/latest" | grep -o "browser_download_url.*\_${osName}_x86_64.zip")
DOWNLOAD_URL=${DOWNLOAD_URL//\"}
DOWNLOAD_URL=${DOWNLOAD_URL/browser_download_url: /}
OUTPUT_BASENAME=datree-latest
OUTPUT_BASENAME_WITH_POSTFIX=$OUTPUT_BASENAME.zip
echo "Installing Datree..."
echo
curl -sL $DOWNLOAD_URL -o $OUTPUT_BASENAME_WITH_POSTFIX
echo -e "\033[32m[V] Downloaded Datree"
unzip -qq $OUTPUT_BASENAME_WITH_POSTFIX -d $OUTPUT_BASENAME
mkdir -p ~/.datree
rm -f /usr/local/bin/datree || sudo rm -f /usr/local/bin/datree
cp $OUTPUT_BASENAME/datree /usr/local/bin || sudo cp $OUTPUT_BASENAME/datree /usr/local/bin
rm $OUTPUT_BASENAME_WITH_POSTFIX
rm -rf $OUTPUT_BASENAME
curl -s https://get.datree.io/k8s-demo.yaml > ~/.datree/k8s-demo.yaml
echo -e "[V] Finished Installation"
echo
echo -e "\033[35m Usage: $ datree test ~/.datree/k8s-demo.yaml"
echo -e " Using Helm? => https://hub.datree.io/helm-plugin"
tput init
echo
Essentially, it just downloads a zip file and expands it into the specified locations. It places the binary into the /usr/local/bin folder - for which it needs a sudo. It does not mess with any system configuration and so it is very simple to remove.
A Simple Demo
The datree installation provides a sample yaml file - for a POC.
datree test ~/.datree/k8s-demo.yaml
>> File: ../../.datree/k8s-demo.yaml
❌ Ensure each container has a configured memory limit [1 occurrences]
💡 Missing property object `limits.memory` - value should be within the accepted boundaries recommended
by the organization
❌ Ensure each container has a configured liveness probe [1 occurrences]
💡 Missing property object `livenessProbe` - add a properly configured livenessProbe to catch possible d
eadlocks
❌ Ensure workload has valid label values [1 occurrences]
💡 Incorrect value for key(s) under `labels` - the vales syntax is not valid so it will not be accepted
by the Kuberenetes engine
❌ Ensure each container image has a pinned (tag) version [1 occurrences]
💡 Incorrect value for key `image` - specify an image version to avoid unpleasant “version surprises” in
the future
+-----------------------------------+-------------------------------------------------+
| Enabled rules in policy “default” | 21 |
| Configs tested against policy | 1 |
| Total rules evaluated | 21 |
| Total rules failed | 4 |
| Total rules passed | 17 |
| See all rules in policy | https://app.datree.io/login?cliId=GStykNg6GkUAS8LfaEt2B8 |
+-----------------------------------+-------------------------------------------------+
Interesting? Well that was just a glimpse.
Online View
Note the URL it generates at the end of the table -
https://app.datree.io/login?cliId=GStykNg6GkUAS8LfaEt2B8
.
This is a unique ID assigned to your system. It is stored in a config file in home folder.
# cat .datree/config.yaml
token: t4e73q9ZxkXhKhcg4vYHDF
Open the link in a browser. It prompts us to log in with Google / Github. As we login, this Unique ID is connected with the new account on Datree. We can now tailor the tool from the web UI. Also, will see the reports from all the tests
Filters and Policies
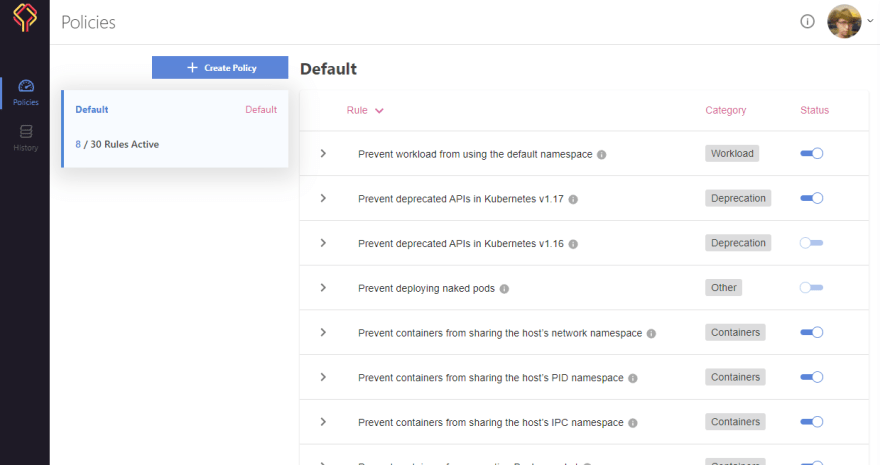
There we can see detailed setup for the tests. We can alter that and the same is used when the yaml files are evaluated. We can choose what we feel is important and skip what we feel can be ignored. If we want, we can be a rebel and allow a class of errors to go through. Datree gives us that flexibility as well.
Apart from the default policy available to us, we can define more custom policies that can be triggered as per our need.
Datree provides "Filters" for all the above mentioned potential issues, and many more.
History
On the left panel, we can see a link for "History". Click on it, and we will see the history of all the validations that it has performed so far. So we can just view the status of policy checks right here - without having to open the "black screen"

Every time we invoke the datree command, it connects to the cloud with this ID and pulls the required configuration, and then uploads the report for the run.
Compatible with Tools
As we saw above, we can trigger the datree in a single command. Much more than that, it also provides wonderful compatibility with most of the configuration management tools and managed Kubernetes deployments like AKS, EKS and GKS. And ofcourse, we cannot forget Helm when working with Kubernetes. Datree provides a simple plugin on helm.

Datree has an elaborate documentation and set of "How to" tutorials on their website. You can refer to them for quickly setting up any feature that you want.
Don't Wait for a Disaster
Most of the applications across the globe have a lot of such misconfigurations - that will surely bring a nasty disaster some day. We knew our application had this problem. But we underestimated the extent of damage that it could cause. We were just procrastinating, sitting on a timebomb!
Now I tell everyone, don't do what we did. Don't wait for the disaster. Automate the configuration checks and enjoy your weekends.
This content originally appeared on DEV Community and was authored by Vikas Solegaonkar
Vikas Solegaonkar | Sciencx (2021-10-11T10:30:57+00:00) Prevent Configuration Errors in Kubernetes. Retrieved from https://www.scien.cx/2021/10/11/prevent-configuration-errors-in-kubernetes/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.