
This content originally appeared on Bits and Pieces - Medium and was authored by Fernando Doglio
The Case for Reactive Architectures — Dropping the Client-server Paradigm for a More Performant Alternative
Client-server communication is so 1990, get with the times!

Are you tired of sending a request and waiting for the response to come (if at all)? Because I am.
The classic client-server paradigm when it comes to web applications is no longer the best alternative, not if your application is complex enough. Don’t get me wrong, a classic REST API that can be consumed using classic HTTP communication is perfect if you’re building a small application, or something that will not need to scale significantly.
However, if you’re pushing the limits of your servers and the technology you’re using, whether because you’re just expecting too much traffic or having to deal with too much data, then you need to break out of the client-server paradigm.
Instead, you should consider a change in paradigm and switch to a Reactive Architecture.
What is a Reactive Architecture then?
The name pretty much states it, the gist of a reactive architecture is that instead of having a single request and a single response, you have the concept of “message”. Services send messages and get notified when a message for them arrives.
Thus the “reactive” part.
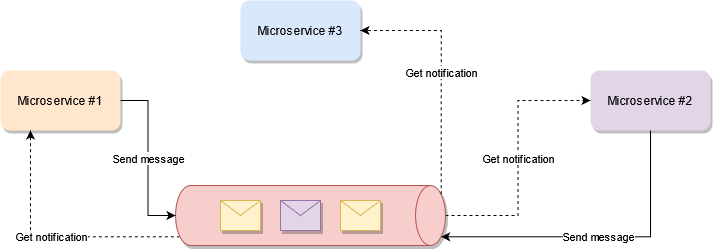
Consider the above diagram, you can see how all microservices are communicating directly with the central message hub instead of to each other.
Using the classic client-server paradigm, you’d have a client (an external application or another service) initiating the request, waiting for the server to perform the task, and then for it to return a response.
Reactive architectures work differently, instead the workflow looks something like this:
- During bootup, all services will register to “listen” for a specific type of message. It may be the case that all of them listen for the same type, or that each one listens for a different one, it really depends on what they’re trying to do.
- Once a service needs something, it’ll send a message with one particular type and payload.
- All interested services will get notified about it and they’ll react accordingly.
- If appropriate, they will also in turn, generate a “response” message that will also be broadcasted. All interested services will react to it (mainly the initiating service) and if appropriate the flow from step 2 will begin anew.
This is a loop that will go on until the final response is generated and the only service interested in it, is the initial one.
This is mainly why this paradigm is called “reactive”, because multipe services are interacting with each other, and instead of actively checking to see if there is a new message for them, they wait until being notified.
Why choose a Reactive architecture?
Why would you want to go with such a paradigm instead of the trusted client-server one? There are many reasons, most of the implied from the behavior I mentioned before:
Optimizing the client’s time
The reactive approach allows the client (or the initiating service) to do something else while it waits for the response. Compare it with the classic client-server setup, where the client needs to wait patiently until the server is done. In this context, a very common error is a timeout that happens when the server takes longer than a pre-defined window of time. This is because you can’t keep the client locked, waiting for a response, indefinitely. The reactive approach could potentially handle longer timeouts because in the meantime the client can to work on anything else. Its business logic is not locked waiting for anything.
Resource consumption
When it comes to resource consumption, a reactive approach is a lot more forgiving. Consider how for a client-server request, the client needs to stay active and aware of what’s happening during the whole time.
For a reactive architecture, your client only needs to initiate the request and then go into sleep mode. In an extreme scenario, you could even set it up in a way that you use something like lambda functions (serverless approach), being executed only when required. This way you’d only use the resources required to run the actual business logic, without the added idle time.
This is a win-win scenario since you save resources and at the same time, that turns into less money spent per request.
It’s a lot easier to scale & grow
Microservice architectures are usually easy to scale, but different services tend to need to be aware of others unless you have some form of discoverability built-in. And even if you do, communication usually happens directly between services or between the client and a particular service. This means that from a business logic point of view, each service needs to be aware of the others because they’re directly issuing requests back and forth.
However, on a reactive architecture, services don’t need to be aware of anything else. They can be developed in isolation, understanding what kind of messages they’ll care for, and the type of processing they’ll do to them. The rest is handled by the central message bus and the other services who decide (or not) to listen for particular types of messages.
This way scaling one section of that architecture is as easy as adding copies of the required services and have them listen for the same type of message. The rest of the architecture doesn’t need to know about it.
The same reasoning can be applied to growing the architecture. Adding new services and business features is as simple as developing the required services and hooking them up into the message bus. The other services don’t need to be aware of anything, unless of course the new services bring with them new message types. But that would be the only caveat, given that a new message type would require other services to know what to do with them. In an ideal scenario, a new service that re-uses existing type definitions for messages, would have no impact on the existing architecture. You can’t say the same for a client-server approach, can you?
Multi-step requests can be processed in parallel a lot easier
Imagine a scenario where you have several microservices that need to be called for a particular request.
On a traditional client-server approach, after the client starts the “conversation” and sends the request, the initial service that receives it, has two options:
- Continues a serial process having one HTTP request after the other, chaining the responses. This would be the simplest approach, but the inherent latency of an HTTP connection would add quite a bit of extra time to the client’s request.
- Orchestrates a set of parallel calls to other services and gathers all the results back. This is more efficient time-wise, but there is a lot of code required inside this service to orchestrate all the complex parallel execution logics.
A reactive architecture would go with option #2 by default. The only (and major) difference is that the whole orchestration would be done by the message bus. The client would only need to enter the initial message, and then wait for the final response to be broadcasted. Anything that happens in between is handled by a component that you didn’t write, nor have to worry about.
A more stable setup
Stability on a platform is relative to how much effort you want to invest into it. But then again, let’s assume you’re paying 0 attention to stability and have a multi-service back-end.
The moment that one of these bad boys starts crashing randomly for some reason (let’s call it resource consumption quota, faulty RAM or whatever) you have two scenarios:
- The classical client-server scenario. Here the request fails because the moment one of the services crashes, the 500 error will bubble up to the client, closing the connection and showing an unhandled error to the client.
- On a reactive architecture. The request would not end, but it would remain in an unfinished state. The client would still be able to function, and while it is true that it would not get the data it was looking for, it’ll still be able to function and potentially cope with that situation.
Now, the moment you fix the problem with the unstable service, it could continue processing those pending requests because they would still be available inside the message bus, waiting at the same stage of the process they were during the initial crush. Frozen in time, if you will, waiting to be finished.
Granted, that story could be different if you were to spend some time working on error handling on either of the two scenarios. The more time you spend on it, the better it’ll be. However, by default the reactive approach already has a head-start over the other one.
Is there anything wrong with a reactive approach?
I mean, let’s be real for a second: there is no perfect solution to any real-world problem. They’re born out of business needs and we need to find the best solution however, nothing is a 100% fit.
The main two issues I tend to mention when speaking about reactive architectures are:
- They only make sense when the back-end is complex enough. Look at it as a threshold, if the complexity of your business logic is not that high and you can solve all your needs with a few microservices, then go with the classic approach. However, if you’ve passed that threshold and you have complex logic, multiple services and other requirements that make it a lot harder to orchestrate and fulfill on a classic scenario, then a reactive approach is probably for you. The extra effort of setting everything up and having your client adapt to the new workflow needs to be worth it.
- They’re a lot harder to debug. Anything complex enough is going to be hard to debug, that’s for sure. But add the asynchronous nature of message exchange that we have going on with our reactive architecture, and following a single request’s data flow is a very complex task. You’ll have to resort to tracking Ids on messages and other techniques to allow for better debugging. Otherwise you’ll lose yourself inside a sea of asynchronous logs.
But that’s IT, to be honest, those are very big cons and you definitely need to consider them when making the decision. However, I think the benefits definitely outweigh the two cons listed here. There is much to be gained and very little to be lost or work-around if you will, to make you decide not to go with a reactive approach.
Build with independent components, for speed and scale
Instead of building monolithic apps, build independent components first and compose them into features and applications. It makes development faster and helps teams build more consistent and scalable applications.
OSS Tools like Bit offer a great developer experience for building independent components and composing applications. Many teams start by building their Design Systems or Micro Frontends, through independent components.
Give it a try →
Small enough back-ends and simple business logic don’t require a lot of effort to be implemented. But then again, you’re probably not here reading about reactive architectures if you’re building one of those.
If you’re pushing the limits of the client-server paradigm, it might be worth considering alternative approaches, such as a reactive architecture. If you’d like to know how to implement one, I wrote here how you can build one around Redis, so make sure to check it out.
Learn More
- Independent Components: The Web’s New Building Blocks
- Microservices are Dead — Long Live Miniservices
- API Versioning Do’s and Don’ts
The Case for Reactive Architectures — Dropping the Client-server Paradigm was originally published in Bits and Pieces on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Bits and Pieces - Medium and was authored by Fernando Doglio
Fernando Doglio | Sciencx (2021-10-14T16:53:41+00:00) The Case for Reactive Architectures — Dropping the Client-server Paradigm. Retrieved from https://www.scien.cx/2021/10/14/the-case-for-reactive-architectures%e2%80%8a-%e2%80%8adropping-the-client-server-paradigm/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.