
This content originally appeared on DEV Community and was authored by Mark A
Hi Guys Good Day!
It's been a long time since I posted here there were a lot of changes in my life for over almost 2 years now, mostly because of the pandemic. But anyways, let's learn about Pipelines in Bitbucket.
Before that let's understand few concepts that you may have heard but dont understand.
CI - Continuous Integration
is a software development practice where developers regularly merge their code changes into a central repository.
CD - Continuous Delivery or Continuous Deployment
Continuous Delivery - is a software development practice where code changes are automatically prepared for a release to production
Continuous Deployment - every change that passes all stages of your production environment.
Basically, the difference between Continuous Delivery and Continuous Deployment is that the former releases our project in a non-production environment like testing or staging but also can be released in the production environment with a manual approval in the pipeline while the latter releases our project in the production environment automatically without a manual approval.
These two combined makes CI/CD (CD can be interchangeable between Continuous Delivery and Continuous Deployment) CI/CD automate steps in your software delivery process, such as testing or building our application when someone pushes in the repository and also automates the release process in the specific environments after the test or build steps depending the configuration in your pipeline.
That's where Bitbucket Pipelines comes into play.
A Pipeline in Bitbucket helps as achieve building a CI/CD in our application. All we need is a configuration file bitbucket-pipelines.yml. The Free Plan gives us 50 build minutes which is enough for us. We will be deploying our project in AWS ElasticBeanstalk.
Before making the bitbucket-pipelines.yml config file. We will install the packages that we will need in this demo. We will be using Node.js in our project.
Run this command in your command line. We will be initializing the node project and install the express framework to build our api.
npm init -y && npm i express
app.js
const express = require('express')
const app = express()
app.use(express.json())
app.get('/', (req, res) => {
return res.send({ message: 'Hello World' })
})
app.all('*', (req, res) => {
return res.status(404).send({ message: 'Not Found' })
})
module.exports = app
server.js
const app = require('./app')
const port = process.env.PORT || 3000
app.listen(port, () => {
console.log(`Server listening at port: ${port}`)
})
We also need to make some sample tests for our api. Install these packages to use for our testing.
npm i -D jest supertest
Make a directory for our testing.
mkdir test
Inside the test folder make this file.
app.test.js
const app = require("../app")
const request = require("supertest")
describe('request server', () => {
it('should return with a status of 200 for the root path', (done) => {
request(app)
.get('/')
.expect(200)
.end(done)
})
it('should return with a status of 200 and the correct response', (done) => {
request(app)
.get('/')
.expect(200)
.expect((res) => {
expect(res.body.message).toBe('Hello World')
})
.end(done)
})
it('should return with a status of 404 for an invalid path', (done) => {
request(app)
.get('/ddd')
.expect(404)
.end(done)
})
})
package.json
{
"name": "api",
"version": "1.0.0",
"description": "",
"main": "server.js",
"scripts": {
"test": "jest",
"start": "node server"
},
"keywords": [],
"author": "",
"license": "ISC",
"dependencies": {
"express": "^4.17.1"
},
"devDependencies": {
"jest": "^27.2.5",
"supertest": "^6.1.6"
}
}
bitbucket-pipelines.yml
image: atlassian/default-image:2
pipelines:
default:
- step:
name: "Install"
image: node:12.13.0
caches:
- node
script:
- npm install
- parallel:
- step:
name: "Test"
image: node:12.13.0
caches:
- node
script:
- npm test
- step:
name: "Build zip"
script:
- apt-get update && apt-get install -y zip
- zip -r application.zip . -x "node_modules/**"
artifacts:
- application.zip
- step:
name: "Deployment to Production"
deployment: production
script:
- pipe: atlassian/aws-elasticbeanstalk-deploy:1.0.2
variables:
AWS_ACCESS_KEY_ID: $AWS_ACCESS_KEY_ID
AWS_SECRET_ACCESS_KEY: $AWS_SECRET_ACCESS_KEY
AWS_DEFAULT_REGION: $AWS_REGION
APPLICATION_NAME: $APPLICATION_NAME
ENVIRONMENT_NAME: $ENVIRONMENT_NAME
ZIP_FILE: "application.zip"
Ok, I will explain our pipeline config. If you want to know more about yaml files here's a link will help you to get started.
image: atlassian/default-image:2
This field specifies the docker image that we will be running our build environment. You can see the list of valid values here.
pipelines:
default:
This pipelines field speaks for itself. The default pipeline field run on every change on the repository or push. We can also use the branches pipeline field to configure our pipeline to run in specific branch changes but in our case we will be using the default.
- step:
name: "Install"
image: node:12.13.0
caches:
- node
script:
- npm install
This specifies a build step in our pipeline. The name field specifies the Name of the step. The image field specifies a different docker image that we can use in this step. I am specifying a new image because this atlassian/default-image:2 has an older version of node installed. The caches field specifies the list of dependencies that we need to cache every build so we can save time for future builds, it will only download the dependencies when the pipeline first runs and it will cached it after a successful build. The script field specifies the list of scripts we need to run in this step.
Note: Steps are executed in the order that they appear in the config file.
- parallel:
- step:
name: "Test"
image: node:12.13.0
caches:
- node
script:
- npm test
- step:
name: "Build zip"
script:
- apt-get update && apt-get install -y zip
- zip -r application.zip . -x "node_modules/**"
artifacts:
- application.zip
The parallel field is really useful if you want to run a couple or a lot of steps at the same time. This will save you a lot of time and of course makes your build faster if the steps you run here don't rely on other steps. As you can see above we are running the Test step and Build zip that will make zip file that we can use to our last step. The artifacts field specifies the output file or files of the step which in the Build zip is the application.zip.
- step:
name: "Deployment to Production"
deployment: production
script:
- pipe: atlassian/aws-elasticbeanstalk-deploy:1.0.2
variables:
AWS_ACCESS_KEY_ID: $AWS_ACCESS_KEY_ID
AWS_SECRET_ACCESS_KEY: $AWS_SECRET_ACCESS_KEY
AWS_DEFAULT_REGION: $AWS_REGION
APPLICATION_NAME: $APPLICATION_NAME
ENVIRONMENT_NAME: $ENVIRONMENT_NAME
ZIP_FILE: "application.zip"
Ok, we are in our last step. The deployment field indicates the environment of this deployment, the only valid values are production, staging and test. In our script, you can see that we have a pipe field, we need the pipe field to integrate to ElasticBeanstalk. Pipes are an amazing feature to work with third party services. If you see this syntax $VARIABLE this is Repository Variables, we can add dynamic configuration using Repository Variables, you can see this in Repository Setting > Pipelines > Repository variables, but first you need enable Pipelines which we will be talking a little bit later.
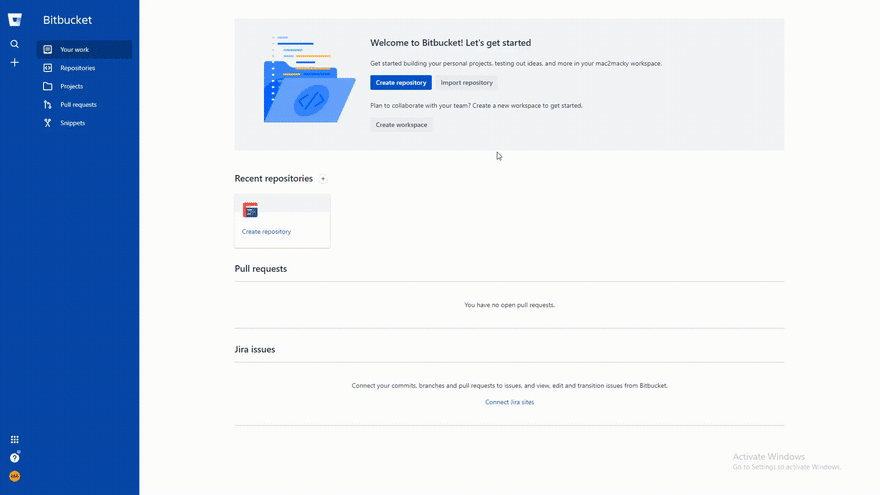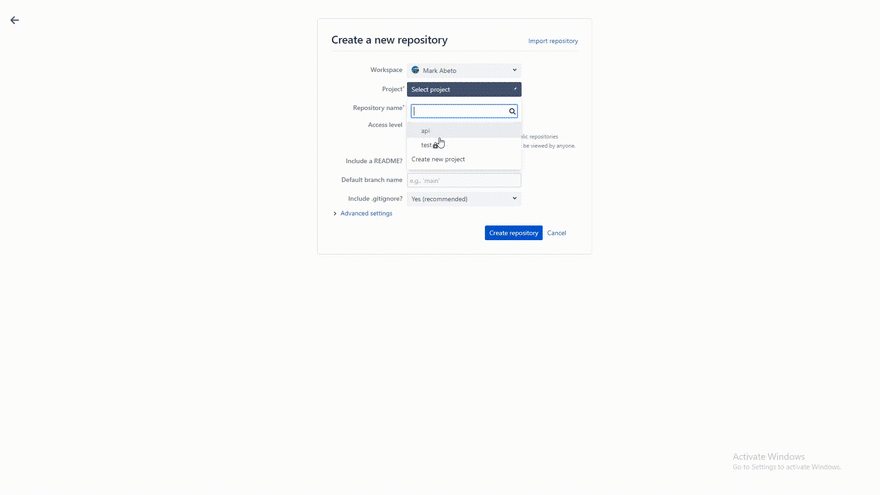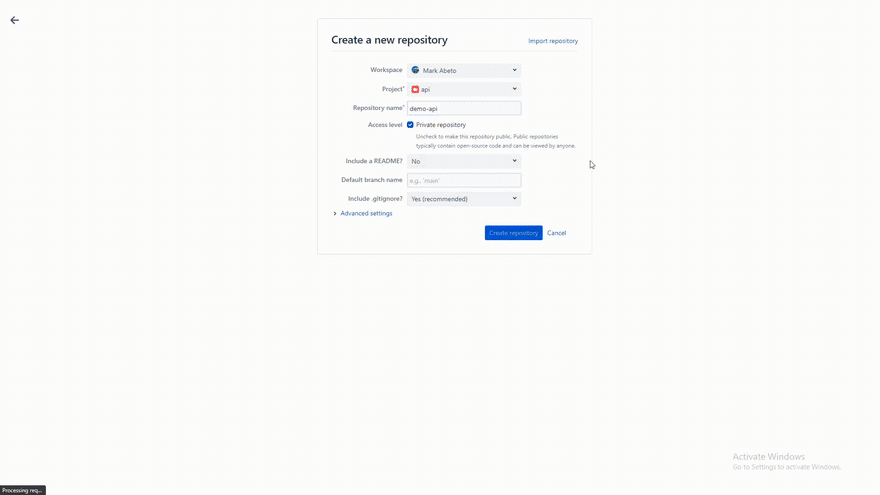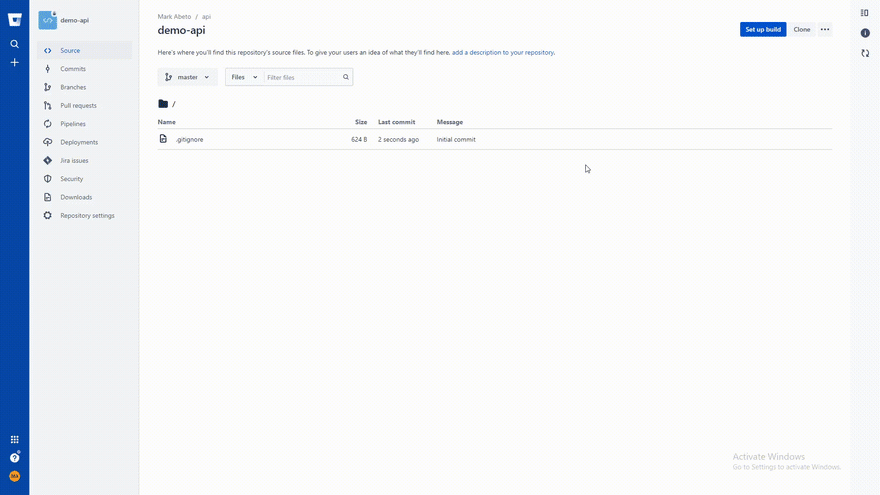
After this, you need to make repository in Bitbucket, you can name it whatever you want or make. Here's a gif on how to make a repo in BitBucket.
Also we need to enable the pipeline. Here's a gif on how to enable the pipeline in Bitbucket.

Adding Repository Variables.

And also we need to make a Application in ElasticBeanstalk. Here's a gif on how to make a Application in ElasticBeanstalk.
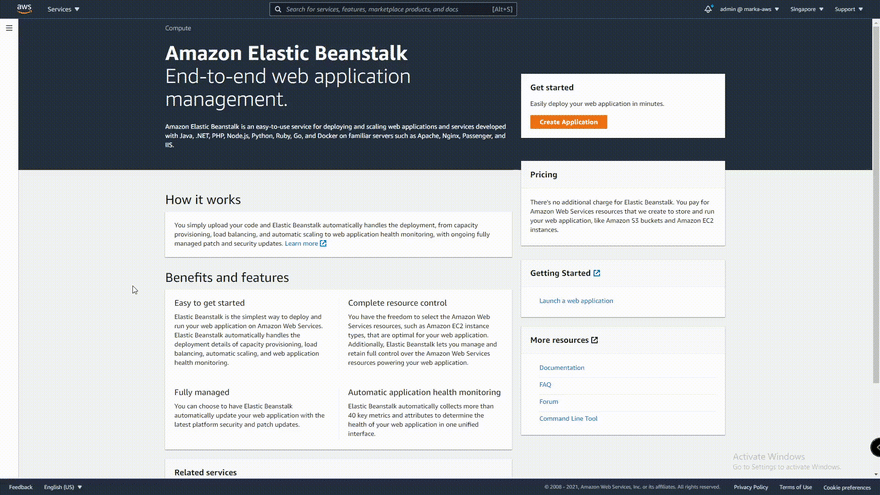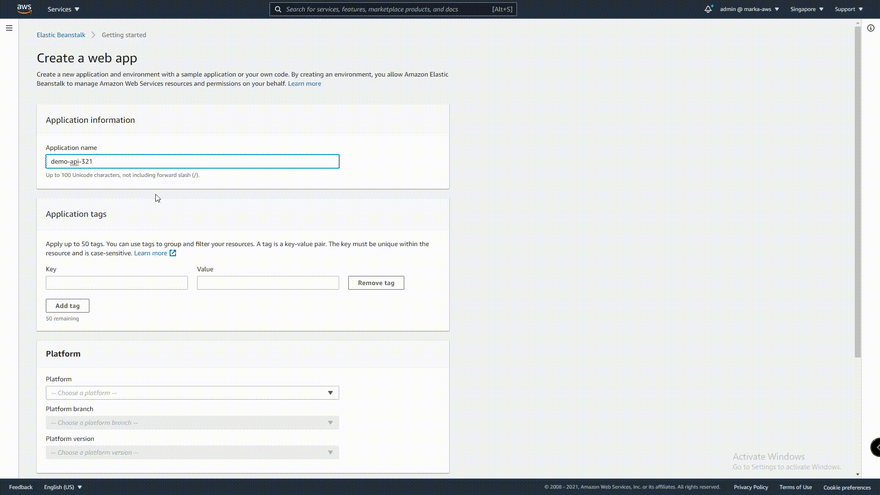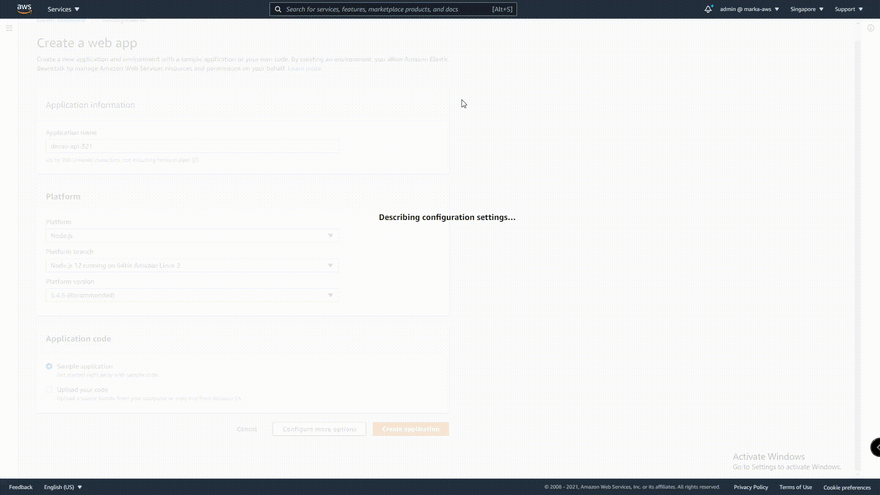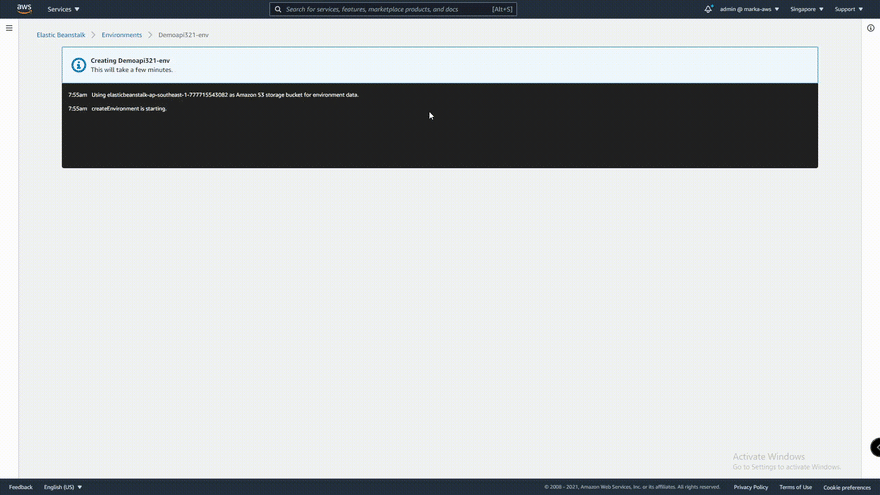
And lastly, bear with me. We need to make a AWS S3 Bucket to store our zip files. The name of the bucket must be in this format
(APPLICATION_NAME)-elasticbeanstalk-deployment. The refers to the ElasticBeanstalk Application that we created earlier. The name of your bucket must be globally unique, this is a S3 constraint that we must follow, so you must application name must be really different because it's a part of the name our bucket.

You need to initialize git in your project and also add the remote repository in Bitbucket as the origin.
git init
git remote add origin <your-repo-link>
git add .
git commit -m "Initial commit"
git pull origin master
git push origin master
This is my finished pipeline. Sorry I can't post another gif file because of the maximum frames.

By the way, if you notice the #2 this is the second time that my pipeline ran, the first time I encountered the S3 bucket PutObject error, basically the bucket didn't exist because it had a different name, the bucket that existed in my S3 had the name demo-api-312-elasticbeanstalk-deployment, it should have the name demo-api-321-elasticbeanstalk-deployment.

So let's access our ElasticBeanstalk Environment.

Yey, it works. Even though we learned a lot, this still is basically simple, you might change the pipeline configuration base on your application needs. But anyways, One step at a time guys.
Thank you guys for reading this post.
Have a Nice Day 😃!.
This content originally appeared on DEV Community and was authored by Mark A
Mark A | Sciencx (2021-10-17T12:25:28+00:00) Working with Bitbucket Pipelines. Retrieved from https://www.scien.cx/2021/10/17/working-with-bitbucket-pipelines/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.