
This content originally appeared on DEV Community and was authored by Salah Elhossiny
- The blue/green deployment technique enables you to release applications by shifting traffic between two identical environments that are running different versions of the application.
- Blue/green deployments can mitigate common risks associated with deploying software, such as downtime and rollback capability.
- This whitepaper provides an overview of the blue/green deployment methodology and describes techniques customers can implement using Amazon Web Services (AWS) services and tools.
- It also addresses considerations around the data tier, which is an important component of most applications.
Blue/Green Deployment Methodology
- Blue/green deployments provide releases with near zero-downtime and rollback capabilities.
The fundamental idea behind blue/green deployment is to shift traffic between two identical environments that are running different versions of your application.
The blue environment represents the current application version serving production traffic.
In parallel, the green environment is staged running a different version of your application.
After the green environment is ready and tested, production traffic is redirected from blue to green.
If any problems are identified, you can roll back by reverting traffic back to the blue environment.
Benefits of Blue/Green
- After you deploy the green environment, you have the opportunity to validate it.
- You might do that with test traffic before sending production traffic to the green environment, or by using a very small fraction of production traffic, to better reflect real user traffic.
- This is called canary analysis or canary testing.
- If you discover the green environment is not operating as expected, there is no impact on the blue environment.
You can route traffic back to it, minimizing impaired operation or downtime and limiting the blast radius of impact.
This ability to simply roll traffic back to the operational environment is a key benefit of blue/green deployments.
You can roll back to the blue environment at any time during the deployment process.
Impaired operation or downtime is minimized because impact is limited to the window of time between green environment issue detection and shift of traffic back to the blue environment.
Additionally, impact is limited to the portion of traffic going to the green environment, not all traffic.
If the blast radius of deployment errors is reduced, so is the overall deployment risk.
Blue/green deployments also work well with continuous integration and continuous deployment (CI/CD) workflows, in many cases limiting their complexity.
Your deployment automation has to consider fewer dependencies on an existing environment, state, or configuration as your new green environment gets launched onto an entirely new set of resources.
Define the Environment Boundary
- When planning for blue/green deployments, you have to think about your environment boundary, where have things changed and what needs to be deployed to make those changes live.
- The scope of your environment is influenced by a number of factors:
Application architecture: Dependencies, loosely/tightly coupled
Organization: Speed and number of iterations
Risk and complexity: Blast radius and impact of failed deployment
People: Expertise of teams
Process: Testing/QA, rollback capability
Cost: Operating budgets, additional resources
For example, organizations operating applications that are based on the microservices architecture pattern could have smaller environment boundaries because of the loose coupling and well-defined interfaces between the individual services.
Organizations running legacy, monolithic apps can still leverage blue/green deployments, but the environment scope can be wider and the testing more extensive.
Regardless of the environment boundary, you should make use of automation wherever you can to streamline the process, reduce human error, and control your costs.
Services for blue/green deployments
- Amazon Route 53
- Elastic Load Balancing
- Auto Scaling
- AWS Elastic Beanstalk
- AWS OpsWorks
- AWS Cloudformation
- Amazon CloudWatch
- AWS CodeDeploy
There are three ways traffic can be shifted during a deployment on Amazon Elastic Container Services (Amazon ECS).
- Canary – Traffic is shifted in two increments.
- Linear – Traffic is shifted in equal increments.
- All-at-once – All traffic is shifted to the updated tasks.
AWS Lambda Hooks
With AWS Lambda hooks, CodeDeploy can call the Lambda function during the various lifecycle events including deployment of ECS, Lambda function deployment, and EC2/On-premise deployment. The hooks are helpful in creating a deployment workflow for your apps.
Implementation Techniques
- The following techniques are examples of how you can implement blue/green on AWS.
- While AWS highlights specific services in each technique, you may have other services or tools to implement the same pattern.
- Choose the appropriate technique based on the existing architecture, the nature of the application, and the goals for software deployment in your organization. - Experiment as much as possible to gain experience for your environment and to understand how the different deployment risk factors affect your specific workload.
Update DNS Routing with Amazon Route 53
- DNS routing through record updates is a common approach to blue/green deployments.
- DNS is used as a mechanism for switching traffic from the blue environment to the green and vice versa when rollback is necessary.
This approach works with a wide variety of environment configurations, as long as you can express the endpoint into the environment as a DNS name or IP address.
-
Within AWS, this technique applies to environments that are:
- Single instances, with a public or Elastic IP address
- Groups of instances behind an Elastic Load Balancing load balancer, or third-party load balancer
- Instances in an Auto Scaling group with an Elastic Load Balancing load balancer as the front end
- Services running on an Amazon Elastic Container Service (Amazon ECS) cluster fronted by an Elastic Load Balancing load balancer
- Elastic Beanstalk environment web tiers
- Other configurations that expose an IP or DNS endpoint
You can shift traffic all at once or you can do a weighted distribution. For weighted distribution with Amazon Route 53, you can define a percentage of traffic to go to the green environment and gradually update the weights until the green environment carries the full production traffic.
This provides the ability to perform canary analysis where a small percentage of production traffic is introduced to a new environment. You can test the new code and monitor for errors, limiting the blast radius if any issues are encountered. It also allows the green environment to scale out to support the full production load if you’re using Elastic Load Balancing(ELB), for example. ELB automatically scales its request-handling capacity to meet the inbound application traffic; the process of scaling isn’t instant, so we recommend that you test, observe, and understand your traffic patterns. Load balancers can also be pre-warmed (configured for optimum capacity) through a support request.
Swap the Auto Scaling Group Behind the Elastic Load Balancer
- If DNS complexities are prohibitive, consider using load balancing for traffic management to your blue and green environments.
- This technique uses Auto Scaling to manage the EC2 resources for your blue and green environments, scaling up or down based on actual demand.
- You can also control the Auto Scaling group size by updating your maximum desired instance counts for your particular group.
- Auto Scaling also integrates with Elastic Load Balancing (ELB), so any new instances are automatically added to the load balancing pool if they pass the health checks governed by the load balancer.
- ELB tests the health of your registered EC2 instances with a simple ping or a more sophisticated connection attempt or request.
- Health checks occur at configurable intervals and have defined thresholds to determine whether an instance is identified as healthy or unhealthy.
- For example, you could have an ELB health check policy that pings port 80 every 20 seconds and, after passing a threshold of 10 successful pings, health check will report the instance as being InService.
- If enough ping requests time out, then the instance is reported to be OutofService
- As you scale up the green Auto Scaling group, you can take blue Auto Scaling group instances out of service by either terminating them or putting them in Standby state.
- Standby is a good option because if you need to roll back to the blue environment, you only have to put your blue server instances back in service and they're ready to go.
- As soon as the green group is scaled up without issues, you can decommission the blue group by adjusting the group size to zero.
- If you need to roll back, detach the load balancer from the green group or reduce the group size of the green group to zero.
Update Auto Scaling Group launch configurations
- A launch configuration contains information like the Amazon Machine Image (AMI) ID, instance type, key pair, one or more security groups, and a block device mapping.
- Auto Scaling groups have their own launch configurations. You can associate only one launch configuration with an Auto Scaling group at a time, and it can’t be modified after you create it.
- To change the launch configuration associated with an Auto Scaling group, replace the existing launch configuration with a new one.
After a new launch configuration is in place, any new instances that are launched use the new launch configuration parameters, but existing instances are not affected.
When Auto Scaling removes instances (referred to as scaling in) from the group, the default termination policy is to remove instances with the earliest launch configuration.
However, you should know that if the Availability Zones were unbalanced to begin with, then Auto Scaling could remove an instance with a new launch configuration to balance the zones.
In such situations, you should have processes in place to compensate for this effect.
To implement this technique, start with an Auto Scaling group and an Elastic Load Balancing load balancer.
To deploy the new version of the application in the green environment, update the Auto Scaling group with the new launch configuration, and then scale the Auto Scaling group to twice its original size.
The next step is to shrink the Auto Scaling group back to the original size.
By default, instances with the old launch configuration are removed first.
You can also utilize a group’s Standby state to temporarily remove instances from an Auto Scaling group.
Having the instance in Standby state helps in quick rollbacks, if required.
As soon as you’re confident about the newly deployed version of the application, you can permanently remove instances in Standby state.
To perform a rollback, update the Auto Scaling group with the old launch configuration.
Then, perform the preceding steps in reverse. Or if the instances are in Standby state, bring them back online
Swap the Environment of an Elastic Beanstalk Application
- Elastic Beanstalk enables quick and easier deployment and management of applications without having to worry about the infrastructure that runs those applications.
- To deploy an application using Elastic Beanstalk, upload an application version in the form of an application bundle (for example, Java .war file or .zip file), and then provide some information about your application.
Based on application information, Elastic Beanstalk deploys the application in the blue environment and provides a URL to access the environment (typically for web server environments).
Elastic Beanstalk provides several deployment policies that you can configure for use, ranging from policies that perform an in-place update on existing instances, to immutable deployment using a set of new instances.
Because Elastic Beanstalk performs an in-place update when you update your application versions, your application may become unavailable to users for a short period of time.
Elastic Beanstalk provides an environment URL when the application is up and running.
The green environment is spun up with its own environment URL.
At this time, two environments are up and running, but only the blue environment is serving production traffic.
Use the following procedure to promote the green environment to serve production traffic.
- Navigate to the environment's dashboard in the Elastic Beanstalk console.
In the Actions menu, choose Swap Environment URL.
Elastic Beanstalk performs a DNS switch, which typically takes a few minutes.
Once the DNS changes have propagated, you can terminate the blue environment.
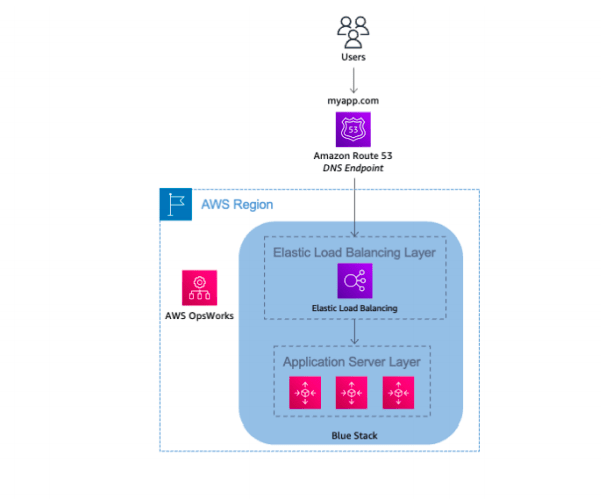
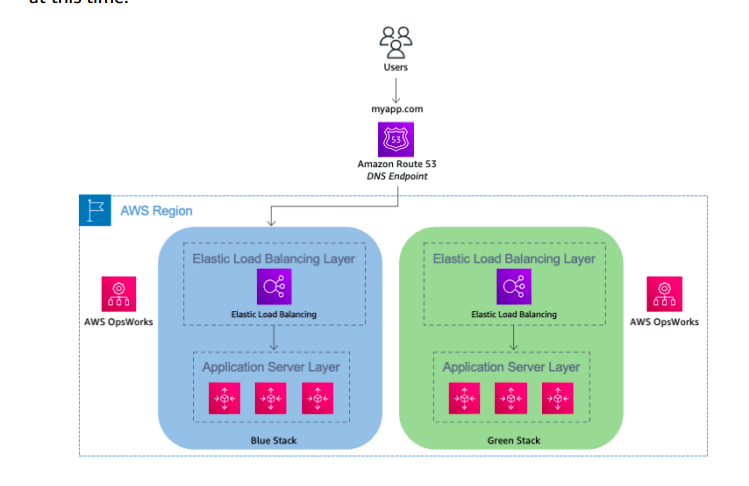
Clone a Stack in AWS OpsWorks and Update DNS
- AWS OpsWorks utilizes the concept of stacks, which are logical groupings of AWS resources (EC2 instances, Amazon RDS, Elastic Load Balancing, and so on) that have a common purpose and should be logically managed together.
- Stacks are made of one or more layers.
A layer represents a set of EC2 instances that serve a particular purpose, such as serving applications or hosting a database server.
When a data store is part of the stack, you should be aware of certain data management challenges.
To implement this technique in AWS OpsWorks, bring up the blue environment/stack with the current version of the application.
Next, create the green environment/stack with the newer version of application.
At this point, the green environment is not receiving any traffic.
If Elastic Load Balancing needs to be initialized, you can do that at this time.
When it’s time to promote the green environment/stack into production, update DNS records to point to the green environment/stack’s load balancer.
You can also do this DNS flip gradually by using the Amazon Route 53 weighted routing policy.
Best Practices for Managing Data Synchronization and Schema Changes
- The complexity of managing data synchronization across two distinct environments depends on the number of data stores in use, the intricacy of the data model, and the data consistency requirements.
Both the blue and green environments need up-to-date data:
- The green environment needs up-to-date data access because it’s becoming the new production environment.
- The blue environment needs up-to-date data in the event of a rollback, when production is either shifts back or remains on the blue environment.
Broadly, you accomplish this by having both the green and blue environments share the same data stores. Unstructured data stores, such as Amazon S3 object storage, NoSQL databases, and shared file systems are often easier to share between the two environments.
Structured data stores, such as RDBMS, where the data schema can diverge between the environments, typically require additional considerations.
A general recommendation is to decouple schema changes from the code changes. This way, the relational database is outside of the environment boundary defined for the blue/green deployment and shared between the blue and green environments. The two approaches for performing the schema changes are often used in tandem:
- The schema is changed first, before the blue/green code deployment.
Database updates must be backward compatible, so the old version of the application can still interact with the data.
The schema is changed last, after the blue/green code deployment.
Code changes in the new version of the application must be backward compatible with the old schema.
There’s an increased risk involved when managing schema with a deletive approach: failures in the schema modification process can impact your production environment.
Your additive changes can bring down the earlier application because of an undocumented issue where best practices weren’t followed or where the new application version still has a dependency on a deleted field somewhere in the code.
To mitigate risk appropriately, this pattern places a heavy emphasis on your pre-deployment software lifecycle steps.
Be sure to have a strong testing phase and framework and a strong QA phase.
Performing the deployment in a test environment can help identify these sorts of issues early, before the push to production.
When Blue/Green Deployments Are Not Recommended
- The following scenarios highlight patterns that may not be well suited for blue/green deployments.
Are your schema changes too complex to decouple from the code changes? Is sharing of data stores not feasible?
In some scenarios, sharing a data store isn’t desired or feasible. Schema changes are too complex to decouple. Data locality introduces too much performance degradation to the application, as when the blue and green environments are in geographically disparate regions. All of these situations require a solution where the data store is inside of the deployment environment boundary and tightly coupled to the blue and green applications respectively.
This requires data changes to be synchronized—propagated from the blue environment to the green one, and vice versa. The systems and processes to accomplish this are generally complex and limited by the data consistency requirements of your application. This means that during the deployment itself, you have to also manage the reliability, scalability, and performance of that synchronization workload, adding risk to the deployment.
Does your application need to be deployment aware?
You should consider using feature flags in your application to make it deployment aware. This will help you control the enabling/disabling of application features in blue/green deployment. Your application code would run additional or alternate subroutines during the deployment, to keep data in sync, or perform other deployment-related duties. These routines are enabled/disabled turned off during the deployment by using configuration flags.
Making your applications deployment aware introduces additional risk and complexity and typically isn’t recommended with blue/green deployments. The goal of blue/green deployments is to achieve immutable infrastructure, where you don’t make changes to your application after it’s deployed, but redeploy altogether. That way you ensure the same code is operating in a production setting and in the deployment setting, reducing overall risk factors.
Does your commercial off-the-shelf (COTS) application come with a predefined update/upgrade process that isn’t blue/green deployment friendly?
Many commercial software vendors provide their own update and upgrade process for applications which they have tested and validated for distribution. While vendors are increasingly adopting the principles of immutable infrastructure and automated deployment, currently not all software products have those capabilities.
Working around the vendor’s recommended update and deployment practices to try to implement or simulate a blue/green deployment process may also introduce unnecessary risk that can potentially negate the benefits of this methodology.
Conclusion
Application deployment has associated risks. However, advancements such as the advent of cloud computing, deployment and automation frameworks, and new deployment techniques, blue/green for example, help mitigate risks, such as human error, process, downtime, and rollback capability.
The AWS utility billing model and wide range of automation tools make it much easier for customers to move fast and cost-effectively implement blue/green deployments at scale.
Reference
This content originally appeared on DEV Community and was authored by Salah Elhossiny
Salah Elhossiny | Sciencx (2021-10-20T12:10:10+00:00) Blue / Green Deployments on AWS | AWS White Paper Summary. Retrieved from https://www.scien.cx/2021/10/20/blue-green-deployments-on-aws-aws-white-paper-summary/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.