
This content originally appeared on DEV Community and was authored by Brett Martin
Originally published @ catstach.io
Hello, and welcome to the my first ever Devlog! I wanted to attempt to build a new web application in public, mostly so I can look back on the experience one day, but also to possibly connect with other developers and builders that I wouldn't meet if I worked in the shadows!
My plan for this first post is to explain the application and what it attempts to solve, and then talk about the first steps I have taken in the first week of development. I will also try to do some small tweets about what I am doing throughout the week and if you are interested in seeing those, give me a follow @BoudroBam!
The Problem
When trying to decide on what to build, I wanted to make sure that I was addressing a problem. It didn't have to be a big problem - in fact I spent a lot of time thinking of smaller problems to try and attempt to solve, but I was usually greeted with a handful of Software as a Service (SaaS) solutions that already existed! However, I didn't let that deter me and I finally settled on a problem to attempt to solve...
Finding information within a company is a massive pain!
I believe this is true for most industries, but it is especially true for software jobs. Not only do you have to know about the systems you are developing and interacting with, you also need to know about the domain of the business, the business rules, which teams own what part of the system, and the list goes on and on.
When you are part of a company for a long enough time you may learn a lot of the things that I pointed out above through conversations and past experiences, but there is usually still some gap in knowledge. If you are new to a company those points are even worse as you drown in a flood of domain knowledge and acronym soup.
I have found that if I was lucky my company had some sort of wiki or knowledge base where people published documentation. However, I still find that with such a system in place, the issue still exists. In fact, I feel that having a wiki gives false security that there is correct, and useful documentation.
The Goals
I decided to title this section "The Goals" because ill be honest, I don't really have a solution! This will be a hard problem to solve, and I imagine there will be many mistakes, learning opportunities, and pivots as I start building. Instead I want to state some goals that will help define what a system that wants to solve this problem should be able to do. It should:
- Assist with clarifying documentation.
- Surface the subject matter experts (SMEs) of topics.
- Ensure knowledge is up to date.
- Enable users discovery.
- Identify knowledge gaps.
I believe a system that does all of these things would massivly improve the correctness and usefulness of information sharing. The goal that is the most daunting, but also the most important in terms of changing how information is compiled, is identifying knowledge gaps. If the system can automatically detect, then ask for someone to fill the gap, that would be huge!
Of course, these goals may change as time goes on. I may add new ones, or rework existing ones to capture new ideas, all based on user feedback.
First Milestone - Clarifying Documentation Through Key Word Detection
With all of the goals laid out, I need to pick something to start driving toward. While I can't tackle all of a singular goal in one go, I can at least start making milestones that I think will address them! So the first goal area I am going to work on is assiting with clarifying documentation, and I think a good place to start would be to help highlight missing definitions.
The idea is that as pages of documentation are added and modified, the system can start to pick out keywords and request that maintainers of the space add definitions to a glossary. I want to start here because it appears to be a pretty simple process and will allow me to get the basic infrastructure of the app set up. I also think it would be a good launching point for starting to add layers of complexity to the process - first ill start with a simple detection and alert system, but then I can move on to suggesting definitions for industry terms, searching for "synonyms" if its a term used internally by the company, etc.
So, that is what I will be working towards first!
Some Wireframes
That has been a lot of words, so I figured now is a decent time for pictures! I have drafted up some wireframes to get just enough of a UI to drive the system. Most are pretty basic and boring, focusing on creating flows for creating Organizations and Workspaces. What I do want to show is just the initial "dashboard", and the two concepts that will help me drive towards the first milestone, the inbox and glossary.
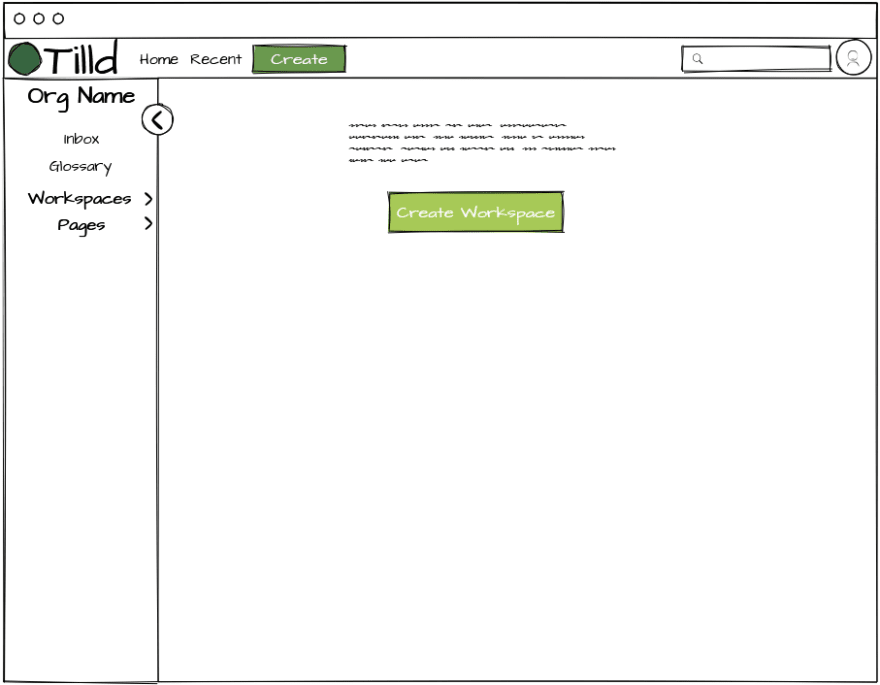
This is the main view when you are in an organization. Its a pretty common layout but its a starting point, and there isn't really a point in reinventing the wheel at this point!
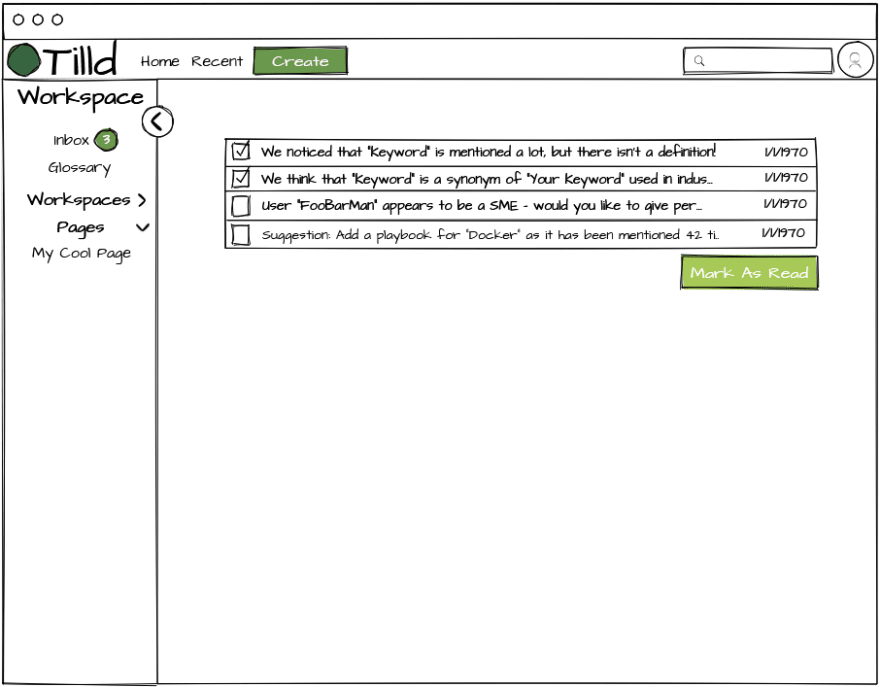
I wanted to add an inbox as the feedback loop for how the system will indicate to the user when something actionable is detected. In this case, when something should have an entry created in the glossary. You can see in the mock up some other ideas I have for use of the inbox such as identifying SMEs, calling out gaps in documentation, etc.
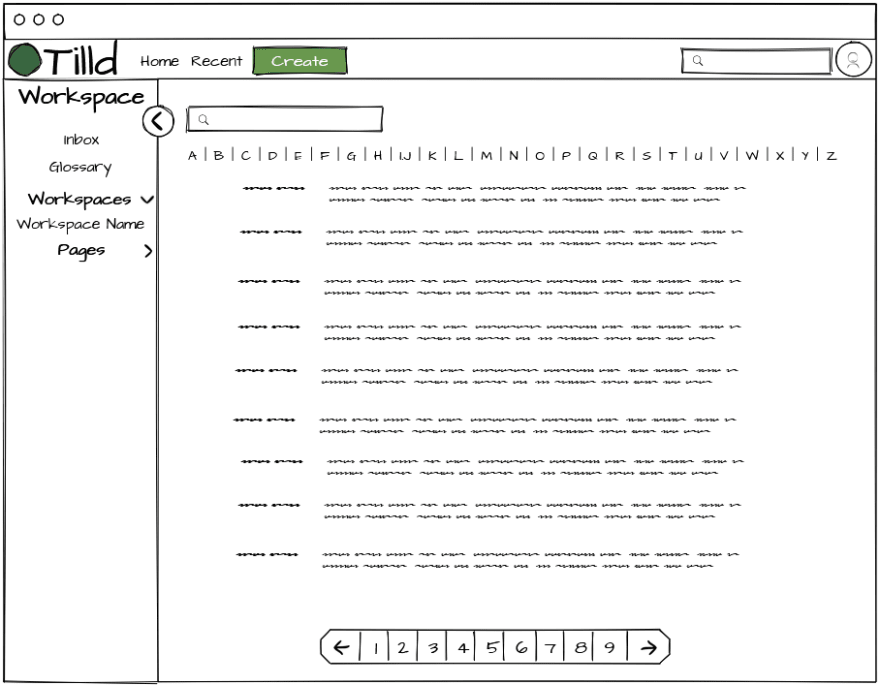
Having an easily accessible glossary is and important first step in achieving usefulness and clarity. At this point in time it will be a basic list of term to definition mappings, but I imagine this will become more content rich as time goes on.
Initial System Design

Now that you have seen some of the visual ideas for the initial UI, I thought it would be good to show the first pass at an overall system design.
I went back and forth in my mind deciding on certain parts of the tech stack, seeing if there was any reason to use some languages and frameworks I wouldn't usually use on my own projects such as Rust with Actix Web or Haskell with Servant for the API but I ended up deciding to keep it simple and use Node with Express for the server since I was going to be using JavaScript anyways for the React front end!
That API server will then be responsible for the common CRUD operations for the things we see in all apps such as Users, and domain specific things like Organizations and Workspaces. These will be written to a PostgreSQL database, since a lot of this info makes sense in a relational database. I decided to go with a second database, a NoSQL database, increasing complexity a bit. This is where the documents will be stored but this may end up being a mistake that I try and roll back in the future. My thinking is that because im not really sure what kind of metadata ill be associating with documents to power this app, it will be easier to work quickly and try new things.
Finally the server will also be responsible for sending messages to a RabbitMQ queue for processors to consume. Again, you can see that there is a plan to create a lot of processors to work off of messages being generated on document CRUD operations. The first one is the keyword processor but ill need to process images to extract data, for example, and I will want to start building a graph of how things in the organization are connected, and who knows what else in the future!
The processors themselves will be written in whatever language makes the most sense, since it is highly decoupled they don't need to interact. That being said, I am starting with Python for the first few because it was the best option when it comes to machine learning and data libraries, and I am keeping them all in the same codebase to allow for code reuse for the common tasks of working with the queues and database.
Current Progress
So, I am not sure the best way of showing progress from a coding and development standpoint. If you have any suggestions of what you would like to see let me know in the comments!
General Notes
As of this writing I started working on the shell of the backend. I wrote a docker-compose file to spin up containers to run the PostgreSQL DB, MongoDB, and RabbitMQ services for local development, and I created two new projects on Gitlab: api and data-processors.
Data Processors
The data processor has been setup to take a command line argument to determine which processor to run on launch, so something like python data-processors.py keyword will start the processor and kick off the logic to pull from the queue and take actions to determine keywords (currently it does nothing besides echo any messages it gets, no fun keyword extraction yet!). It pulls from the message queue using the pika. Unfortunately there isn't too much that is interesting going on in here yet to show code wise.
The next thing to do will be to connect to the MongoDB instance to enable read/write operations on the documents.
API
Similar to the data processor, the first thing I did besides just the basic "Hello World" setup of an express server was create the functionality to write to the queue. I set it up to be a singleton connection to avoid opening and closing all the time, and I can show the first pass of that code here real quick:
const amqp = require('amqplib');
/**
* Function to create a singleton connection to the RabbitMQ host.
* Returns a function `get` to return the connection to the caller, and
* `release` to close the connection.
*
* `release` should only really be invoked if the server is closing and is added
* for completness.
*/
const conn = (() => {
let connection = null;
const connect = async () => {
try {
return await amqp.connect(process.env.RABBITMQ_HOST);
} catch (e) {
console.log('Failed to connect to RabbitMQ Host: ', e);
}
}
const get = async () => {
if (connection === null) {
connection = await connect();
}
return connection;
}
const release = async () => {
if (connection !== null) {
await connection.close();
}
}
return {
get,
release
};
})();
/**
* A channel is just a multiplexed connection on the open TCP connection. This allows us to have distinct channels for different logical
* operations without maintaining extra TCP connections.
*/
const createChannel = async () => {
const connection = await conn.get();
const channel = await connection.createChannel();
return channel;
};
/**
* We make use of an exchange under the hood since most messages will be intended for more than
* one consumer, and a standard queue is a 1-to-1 producer to consumer ratio.
*/
const createExchange = async (exhange) => {
const channel = await createChannel();
await channel.assertExchange(exhange, 'topic', { durable: false });
return channel;
}
/**
* The only function that should be used outside of this file.
*
* Given an exchange name and a topic, return two functions. One to publish to the exchange, and one
* to close the channel connection when done.
*
* TODO - Write up some documentation to link to where we record all the exchanges / keys in use.
*/
const mkQueue = async (exchange) => {
const channel = await createExchange(exchange);
const publish = (key, msg) => {
channel.publish(exchange, key, Buffer.from(msg));
};
const close = async () => {
await channel.close();
}
return [publish, close];
}
module.exports = mkQueue
This allows me to make use of just the exported function like this:
const { rabbitmq } = require('./queue');
const [publish, close] = rabbitmq('docs');
publish('#', 'This is my message');
await close();
So anywhere that I want to write to the queue (any API endpoint that needs to produce a message), I can pass a handle to the publish function to and boom!
The next thing I did was setup my connection the PostgreSQL database using the node-postgres library, and setup migrations to define my schema with node-pg-migrate. I created some simple create functions for the various parts of the database like this one for creating an organization:
const createOrganization = query => {
return async (name, description = '', industry = '') => {
const { rows } = await query('INSERT INTO organizations (name, description, industry) VALUES ($1, $2, $3) RETURNING *', [name, description, industry]);
const { id } = rows[0];
return id;
};
};
I might end up moving away from the migration library, but it seemed like it would work for my current use case.
As you can see from the code above, its not really production ready. I need to set up error handling & recovery when executing these operations and do some logging, but ill probably do that at a later time when I am getting close to releasing the first milestone.
Next Steps
This upcomming week I hope to achieve the following:
- Establish the connection to MongoDB for both the API and the data processor.
- Build the
/api/docsroute for all the verbs (GET, POST, PUT, DELETE) - Persist docs to the MongoDB instance, send a message to the queue, and see the processor successfully retrieve the doc from MongoDB.
- Determine which data science package to use for keyword extraction
- Implement the keyword extraction!
- Stretch: setting up the rest of the API routes for CRUD operations would be good as well.
What Are You Building?
If you made it this far, thank you so much for reading! I am hoping to release these either on a weekly or bi-weekly basis, so make sure to follow if you want to see the progress!
I would love to hear about what you are building as well! Is it a library, a program to solve a problem that has been nagging you, the next Google? Let me know in the comments!
This content originally appeared on DEV Community and was authored by Brett Martin
Brett Martin | Sciencx (2021-11-09T05:26:47+00:00) Tilld Devlog #1 – Building a Better Knowledge Source. Retrieved from https://www.scien.cx/2021/11/09/tilld-devlog-1-building-a-better-knowledge-source/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.