
This content originally appeared on DEV Community and was authored by Salem Olorundare👨💻
Introduction
Have you ever wondered how search engines like Google, fetch data from different parts of the web and serve it to you as a user, based on your query? The method used by applications like this is termed crawling.
Search engines work and by crawling and indexing billions of web pages using different web crawlers called web spiders or search engine bots. What these web spiders do is follow links from each web page that have been indexed to discover new ages.
In this short article, you will be building out your own web crawler using Python and its popular web framework for extracting the data you need from websites.
Also, in this tutorial, developers tend to be confused with web crawling and web scraping. We would learn the difference between these two concepts and examine some examples
Prerequisites and Requirements
Before you begin with this tutorial, make sure you have a very basic understanding of python programming, as the article assumes you have gotten familiar and some of the concepts we would be discussing here would be new to you.
To move and understand things quickly, you must also know how to use your chrome developer tools to find tags and classes, in other for you to scrap the website well.
You also need to have the python package manager PIP, to enable you to install Scrapy.
What are web crawlers?
Web crawlers also known as spider bots are internet bots that search the entire Internet for content and prepare them for indexing. This is how crawlers work in a search engine.
In how case the data were gotten from our crawler won't be indexed as we are not building a search engine (at least not yet).
Crawlers consume and extract data from different pages it crawls from and gets them ready for use. Depending on the use case of the user. Crawlers can also be used for web scraping and data-driven programming. The Goal of each web crawler is to know what each web page is all about and to serve it when it is needed or requested for. It automatically accesses a website, consumes and downloads its data through software programs.
Since the internet is constantly changing and it is impossible to know the total number of web pages on the internet, Web crawlers start crawling from a list of known URLs. They crawl the pages of those URLs first and then start looking for a hyperlink to other related web pages from those URLs.
Though crawlers also crawl and find web pages based on the number of traffic on a website, the basic and default of how web crawlers find pages are from the list of known URLs or seeds.
By applying proven algorithms to building crawlers and finding web pages, search engines can provide relevant links and respond almost accurately to user queries.
Difference between Scrapy and BeautifulSoup
As we said earlier, we are going to be using scrapy for this tutorial. But there seems to be a couple of web crawling and scraping framework used in python. The most common of them all is Scrapy and BeautifulSoup.
Although both of these tools are used for web scraping and crawling, there’s quite a large difference between them both. Unlike Scrapy which is used to be specifically created for downloading, cleaning, and saving data from the web and will help you end-to-end, BeautifulSoup is a smaller package that will only help you get information out of webpages with the request module.
Scrapy Installation
To be able to make use of scrapy in our application we need to install scrapy to our local machine, and to do this, run the following command on your terminal:
`pip install scrapy`
The code above downloads scrapy for us. Once it finishes downloading we will then move to create our project.
Creating the Scrapy app
Create a scrapy-python application with a name with the command below. In our case, we named our python application webcrawler.py.
`scrapy startproject webscrawler`
The code above starts a scrapy project in a folder with a scrapy boilerplate. The file structure created should look like this:

Open your application folder (in my case webcrawler) in a code editor, and let's continue building our crawler.
Creating Web Crawler
Creating your first spider. Spider are classes we define, and scrapy uses to gather information from the web.
To create your first spider in scrapy, navigate to the spider file and create and a new folder called spider1.py. This will be our first spider.
All spiders or crawlers are created and stored in the spider folder.
Open your spider1.py and paste the following codes, to create your first crawler, as we would be crawling through the http://quotes.toscrape.com/page/1/ web page.
#imports
import scrapy
#Spider class
class QuotesSpider(scrapy.Spider):
#name of your spider
name = "quotes"
def start_requests(self):
#Website links to crawl
urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
#loop through the urls
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
page = response.url.split("/")[-2]
filename = f'quotes-{page}.html'
with open(filename, 'wb') as f:
f.write(response.body)
The code above crawls through the web links given and downloads the page and gets it ready to be scraped.
To run the following codes, run the following code in your terminal in the directory of your scrapy project.
scrapy crawl webscrawler
When this code is run successfully, two files (quotes-1.html & quotes-2.html) will be created in your project directory. These are the two pages that are downloaded by scrapy and ready for scraping.
Congratulations, you have built your first Web crawler. Tadaa.
Scraping the web pages
Now that you have crawled the web pages and it has been downloaded. We then need to scrape or extract the data needed from the web page. And we would be using the css selector to get this data.
Update your scraper1.py file with the following codes:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
def start_requests(self):
urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span::text').get(),
'author': quote.css('small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall()
}
In above code extracts the text, author, and tags for each of the web pages listed in the URL.
To see our results from the scraped webpages run the following command in your terminal.
`scrapy crawl quotes -o results.json`
This command runs the scraper, scraps the data, and stores it in a folder called results.json.
If you have followed the tutorial till this point, your code should run successfully and you shouldhave the following data in your results.json file, which is created in your project directory.
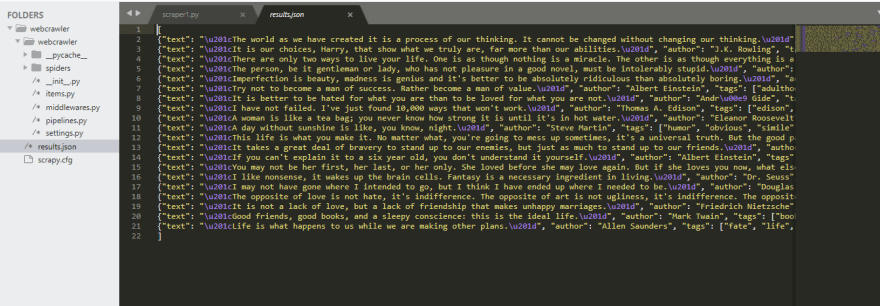
Conclusion
Congratulations, on building your first web scraper. This is how simpler it is to create a web crawler and scrape data from it. By now you should have a basic idea of how web crawlers and web scrapers work and how it's being implemented with search engines to extract data from the web.
There are a lot of things you can do with scrapy and web scrapy. Data scientists and AI engineers used web scraping to get a substantial amount of data to perform various data analyses and train a model with this data.
I hope you enjoyed the tutorial and it was helpful. Be sure to build projects get a vast knowledge in performing web scraping and web crawling.
This content originally appeared on DEV Community and was authored by Salem Olorundare👨💻
Salem Olorundare👨💻 | Sciencx (2021-11-22T20:27:02+00:00) Build a web crawler from scratch. Retrieved from https://www.scien.cx/2021/11/22/build-a-web-crawler-from-scratch/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.