
This content originally appeared on DEV Community and was authored by Nicolae Rotaru
Introduction
Zillow is a real estate company that offers various products targeted at both home buyers and sellers.
You can scrape listings from Zillow, with data including addresses, prices, descriptions, photos, URLs to perform:
- price monitoring
- trends analysis
- competitor analysis
Challenges
At first look, scraping Zillow doesn't seem to be a trivial task because of the following aspects:
- The content from the listing page is returned dynamically, based on scrolling events.
- The names of the CSS selectors are dynamically generated and cannot be used to pick the needed content, and we will use XPath selectors instead.
For this purpose, we will use Page2API - the scraping API that overtakes the challenges mentioned above with ease.
In this article, we will describe how to scrape two types of Zillow pages:
- Property listings page
- Property overview page
Prerequisites
To start scraping, you will need the following things:
- A Page2API account
- A location, in which we want to search for listed properties, let's use for example
Redwood City - A property overview page from Zillow. We will pick a random property link from the page mentioned above.
Scraping Zillow listings page
First what we need is to open the Homes page and type the name of the city that will show the properties we are searching for.
In our case we will open this page:
https://www.zillow.com/homes/
and search for Redwood City
It will change the browser URL to something similar to:
https://www.zillow.com/homes/Redwood-City,-CA_rb/
The resulted URL is the first parameter we need to start scraping the listings page.
The listings page must look similar to the following one:
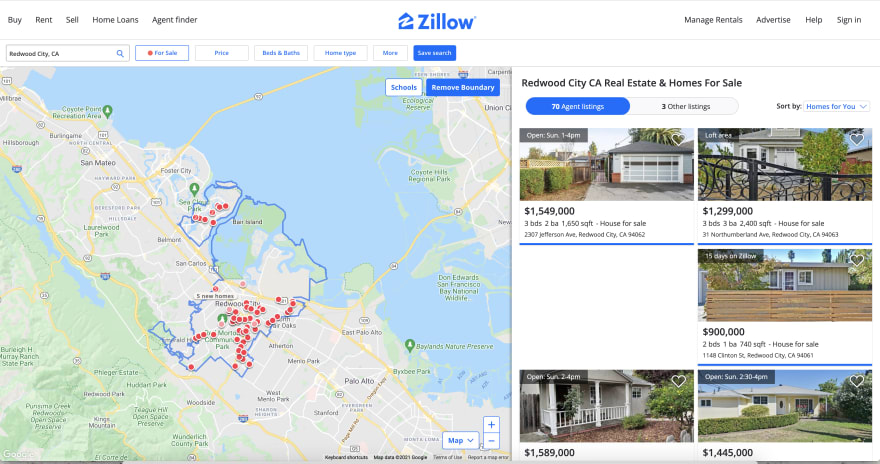
If you inspect the page HTML, you will find out that a single result is wrapped into an element that looks like the following:
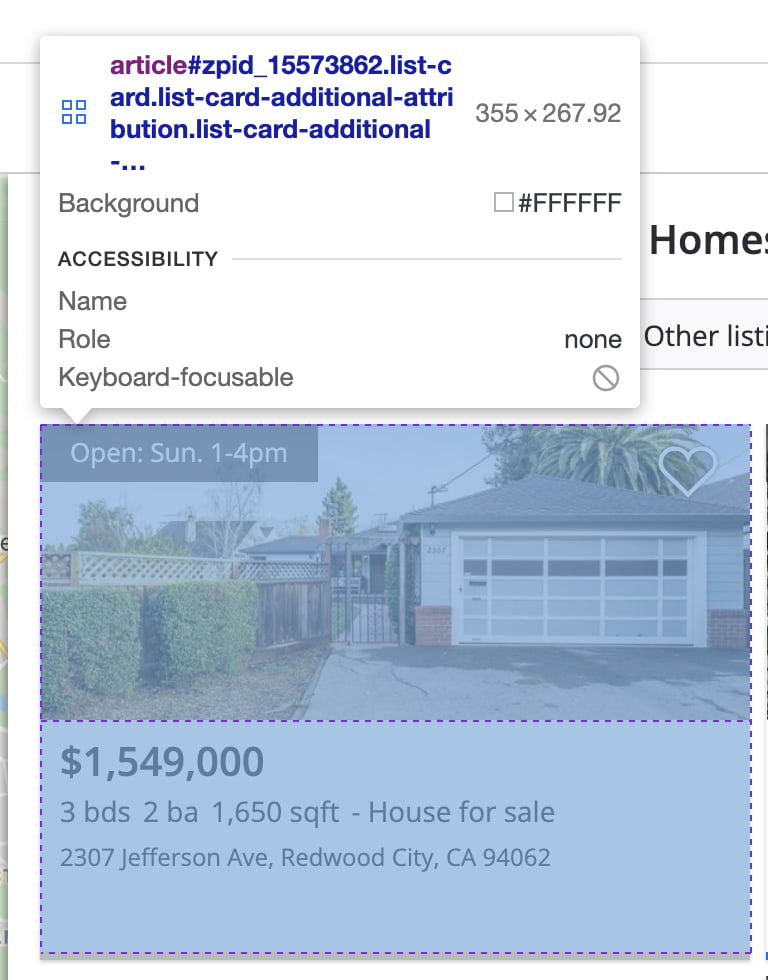
The HTML for a single result element will look like this:
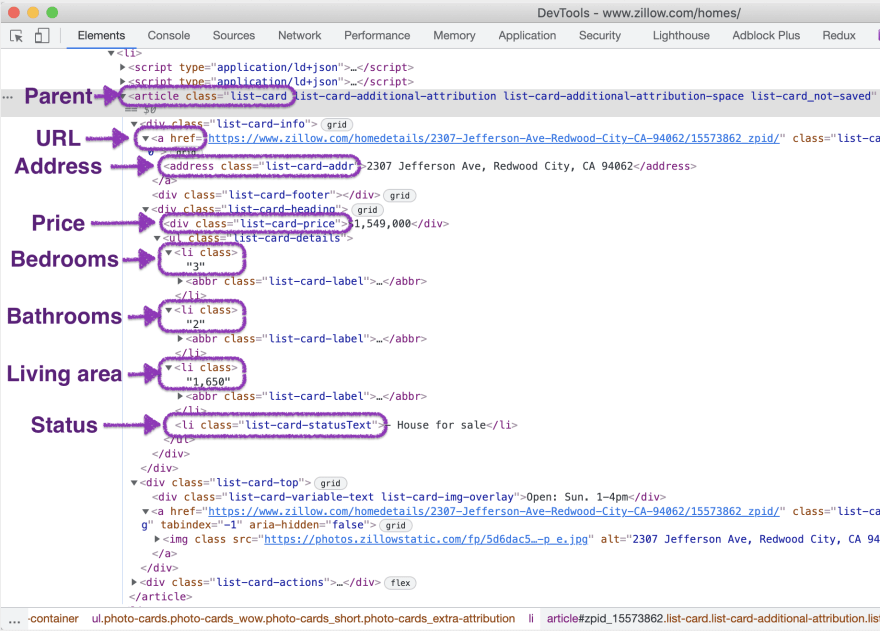
From the listing page, we will scrape the following attributes from each property:
- Price
- URL
- Bedrooms
- Bathrooms
- Living area
- Status
- Address
Each property container is wrapped in an article element with the following class: list-card.
Now, let's define the selectors for each attribute.
/* Parent: */
article.list-card
/* Price: */
.list-card-price
/* URL: */
a
/* Bedrooms: */
ul.list-card-details li:nth-child(1)
/* Bathrooms: */
ul.list-card-details li:nth-child(2)
/* Living area: */
ul.list-card-details li:nth-child(3)
/* Status: */
ul.list-card-details li:nth-child(4)
/* Address: */
a address.list-card-addr
Next is the pagination handling.
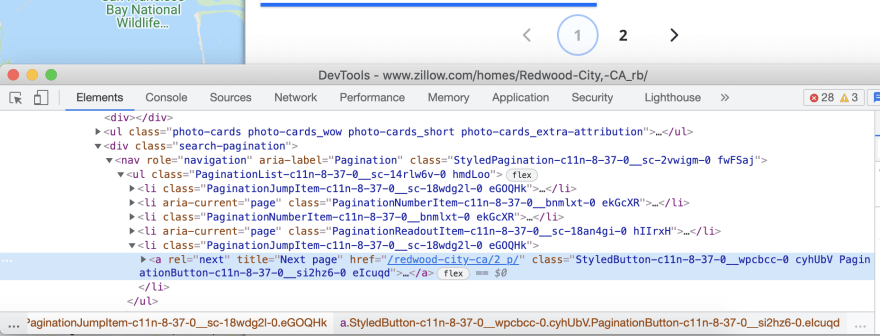
In our case, we must click on the next page link while the link will be active:
document.querySelector('.search-pagination a[rel=next]').click()
And stop our scraping request when the next page link became disabled.
In our case, a new attribute (disabled) is assigned to the pagination link.
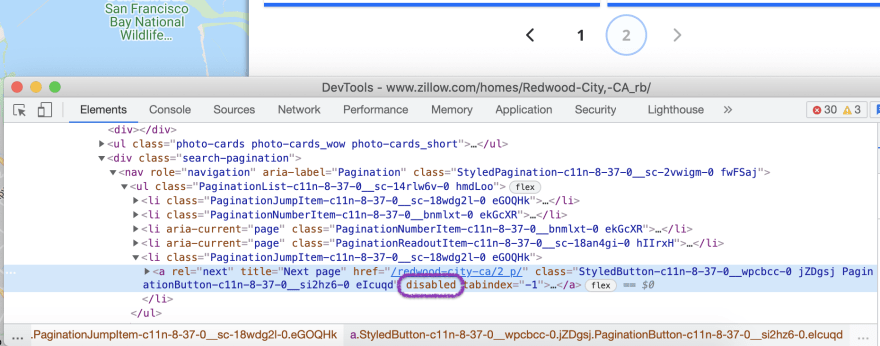
The stop condition for the pagination will look like this:
document.querySelector('.search-pagination a[rel=next]').getAttributeNames().includes('disabled')
// returns true if there is no next page
The last thing is handling the content that loads dynamically when we scroll down.
Usually, there are 40 items on the page, but when the page loads - it has only about 8 items.
To load all items we will do the next trick:
- Wait for the page to load
- Scroll down 3 times slowly, (with a short delay) until we see the last item
- Start scraping the page
Now let's build the request that will scrape all properties that the search page returned.
Setting the api_key as an environment variable:
export API_KEY=YOUR_PAGE2API_KEY
The payload for our scraping request will be:
{
"url": "https://www.zillow.com/homes/Redwood-City,-CA_rb/",
"real_browser": true,
"merge_loops": true,
"scenario": [
{
"loop": [
{ "wait_for": ".search-pagination a[rel=next]" },
{ "execute_js": "var articles = document.querySelectorAll('article')"},
{ "execute_js": "articles[Math.round(articles.length/4)].scrollIntoView({behavior: 'smooth'})"},
{ "wait": 1 },
{ "execute_js": "articles[Math.round(articles.length/2)].scrollIntoView({behavior: 'smooth'})"},
{ "wait": 1 },
{ "execute_js": "articles[Math.round(articles.length/1.5)].scrollIntoView({behavior: 'smooth'})"},
{ "wait": 1 },
{ "execute": "parse"},
{ "execute_js": "document.querySelector('.search-pagination a[rel=next]').click()" }
],
"stop_condition": "document.querySelector('.search-pagination a[rel=next]').getAttributeNames().includes('disabled')"
}
],
"parse": {
"properties": [
{
"_parent": "article.list-card",
"price": ".list-card-price >> text",
"url": "a >> href",
"bedrooms": "ul.list-card-details li:nth-child(1) >> text",
"bathrooms": "ul.list-card-details li:nth-child(2) >> text",
"living_area": "ul.list-card-details li:nth-child(3) >> text",
"status": "ul.list-card-details li:nth-child(4) >> text",
"address": "a address.list-card-addr >> text"
}
]
}
}
We have to encode our JS snippets in base64 to run the request in the terminal with cURL.
Running the scraping request with cURL:
curl -v -XPOST -H "Content-type: application/json" -d '{
"api_key": "'"$API_KEY"'",
"url": "https://www.zillow.com/homes/Redwood-City,-CA_rb/",
"real_browser": true,
"merge_loops": true,
"scenario": [
{
"loop" : [
{ "wait_for": ".search-pagination a[rel=next]" },
{ "execute_js": "dmFyIGFydGljbGVzID0gZG9jdW1lbnQucXVlcnlTZWxlY3RvckFsbCgnYXJ0aWNsZScp"},
{ "execute_js": "YXJ0aWNsZXNbTWF0aC5yb3VuZChhcnRpY2xlcy5sZW5ndGgvNCldLnNjcm9sbEludG9WaWV3KHtiZWhhdmlvcjogJ3Ntb290aCd9KQ=="},
{ "wait": 1 },
{ "execute_js": "YXJ0aWNsZXNbTWF0aC5yb3VuZChhcnRpY2xlcy5sZW5ndGgvMildLnNjcm9sbEludG9WaWV3KHtiZWhhdmlvcjogJ3Ntb290aCd9KQ=="},
{ "wait": 1 },
{ "execute_js": "YXJ0aWNsZXNbTWF0aC5yb3VuZChhcnRpY2xlcy5sZW5ndGgvMS41KV0uc2Nyb2xsSW50b1ZpZXcoe2JlaGF2aW9yOiAnc21vb3RoJ30p"},
{ "wait": 1 },
{ "execute": "parse"},
{ "execute_js": "ZG9jdW1lbnQucXVlcnlTZWxlY3RvcignLnNlYXJjaC1wYWdpbmF0aW9uIGFbcmVsPW5leHRdJykuY2xpY2soKQ==" }
],
"stop_condition": "ZG9jdW1lbnQucXVlcnlTZWxlY3RvcignLnNlYXJjaC1wYWdpbmF0aW9uIGFbcmVsPW5leHRdJykuZ2V0QXR0cmlidXRlTmFtZXMoKS5pbmNsdWRlcygnZGlzYWJsZWQnKQ=="
}
],
"parse": {
"properties": [
{
"_parent": "article.list-card",
"price": ".list-card-price >> text",
"url": "a >> href",
"bedrooms": "ul.list-card-details li:nth-child(1) >> text",
"bathrooms": "ul.list-card-details li:nth-child(2) >> text",
"living_area": "ul.list-card-details li:nth-child(3) >> text",
"status": "ul.list-card-details li:nth-child(4) >> text",
"address": "a address.list-card-addr >> text"
}
]
}
}' 'https://www.page2api.com/api/v1/scrape' | python -mjson.tool
The result:
{
"result": {
"properties": [
{
"price": "$600,000",
"url": "https://www.zillow.com/homedetails/464-Clinton-St-APT-211-Redwood-City-CA-94062/15638802_zpid/",
"bedrooms": "1 bd",
"bathrooms": "1 ba",
"living_area": "761 sqft",
"status": "- Condo for sale",
"address": "464 Clinton St APT 211, Redwood City, CA 94062"
},
{
"price": "$2,498,000",
"url": "https://www.zillow.com/homedetails/3618-Midfield-Way-Redwood-City-CA-94062/15571874_zpid/",
"bedrooms": "4 bds",
"bathrooms": "4 ba",
"living_area": "2,960 sqft",
"status": "- House for sale",
"address": "3618 Midfield Way, Redwood City, CA 94062"
},
...
]
}, ...
}
Scraping Zillow property overview page
From the Homes page, we click on any property.
This will change the browser URL to something similar to:
https://www.zillow.com/homedetails/464-Clinton-St-APT-211-Redwood-City-CA-94062/15638802_zpid/
We will see something like this when we will inspect the page source:
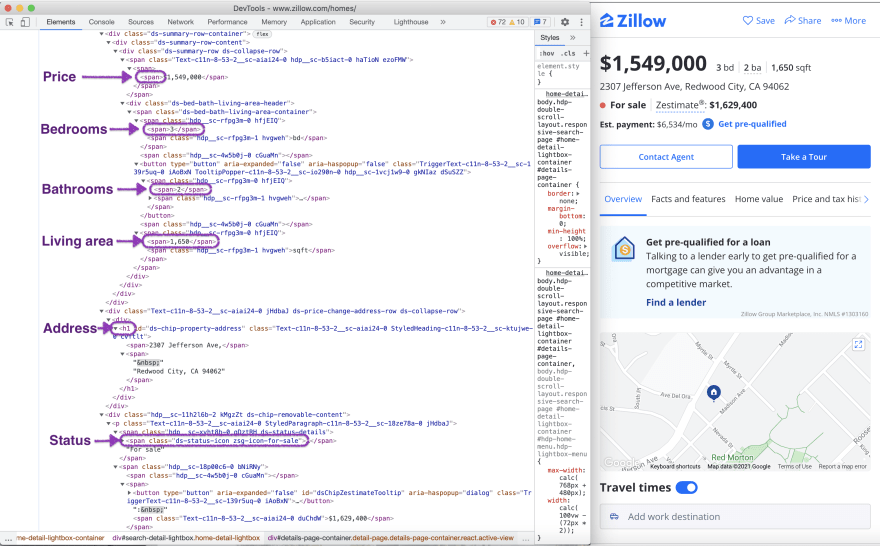
From this page, we will scrape the following attributes:
- Price
- Address
- Bedrooms
- Bathrooms
- Living area
- Status
- Overview
- Time on Zillow
- Views
- Saves
- Images
Let's define the selectors for each attribute.
/* Price: */
.ds-summary-row span
/* Address */
h1
/* Bedrooms: */
.ds-bed-bath-living-area-container span span
/* Bathrooms: */
.ds-bed-bath-living-area-container button span span
/* Living area: */
.ds-bed-bath-living-area-container span:nth-child(5) span
/* Status: */
.ds-status-details
/* Overview: */
//*[@id='home-details-content']/div/div/div[1]/div[2]/div[2]/div[3]/div/div/div/ul/li[2]/div[3]/div[1]/div[1]
/* Time on Zillow: */
//*[contains(text(),'Time on Zillow')]/../dd[1]/strong
/* Views: */
//*[contains(text(),'Time on Zillow')]/../dd[2]/strong
/* Saves: */
//*[contains(text(),'Time on Zillow')]/../dd[3]/strong
/* Images: */
.media-stream-tile picture img
The payload for our scraping request will be:
{
"url": "https://www.zillow.com/homedetails/31-Northumberland-Ave-Redwood-City-CA-94063/15567306_zpid/",
"real_browser": true,
"wait_for": ".ds-status-details",
"parse": {
"price": ".ds-summary-row span >> text",
"address": "h1 >> text",
"bedrooms": ".ds-bed-bath-living-area-container span span >> text",
"bathrooms": ".ds-bed-bath-living-area-container button span span >> text",
"living_area": ".ds-bed-bath-living-area-container span:nth-child(5) span >> text",
"status": ".ds-status-details >> text",
"overview": "//*[@id='home-details-content']/div/div/div[1]/div[2]/div[2]/div[3]/div/div/div/ul/li[2]/div[3]/div[1]/div[1] >> text",
"time_on_zillow": "//*[contains(text(),'Time on Zillow')]/../dd[1]/strong >> text",
"views": "//*[contains(text(),'Time on Zillow')]/../dd[2]/strong >> text",
"saves": "//*[contains(text(),'Time on Zillow')]/../dd[3]/strong >> text",
"images": [".media-stream-tile picture img >> src"]
}
}
Running the scraping request with cURL:
curl -v -XPOST -H "Content-type: application/json" -d '{
"api_key": "'"$API_KEY"'",
"url": "https://www.zillow.com/homedetails/31-Northumberland-Ave-Redwood-City-CA-94063/15567306_zpid/",
"real_browser": true,
"wait_for": ".ds-status-details",
"parse": {
"price": ".ds-summary-row span >> text",
"address": "h1 >> text",
"bedrooms": ".ds-bed-bath-living-area-container span span >> text",
"bathrooms": ".ds-bed-bath-living-area-container button span span >> text",
"living_area": ".ds-bed-bath-living-area-container span:nth-child(5) span >> text",
"status": ".ds-status-details >> text",
"overview": "//*[@id=\"home-details-content\"]/div/div/div[1]/div[2]/div[2]/div[3]/div/div/div/ul/li[2]/div[3]/div[1]/div[1] >> text",
"time_on_zillow": "//*[contains(text(), \"Time on Zillow\")]/../dd[1]/strong >> text",
"views": "//*[contains(text(),\"Time on Zillow\")]/../dd[2]/strong >> text",
"saves": "//*[contains(text(),\"Time on Zillow\")]/../dd[3]/strong >> text",
"images": [".media-stream-tile picture img >> src"]
}
}' 'https://www.page2api.com/api/v1/scrape' | python -mjson.tool
The result:
{
"result": {
"price": "$1,299,000",
"address": "31 Northumberland Ave, Redwood City, CA 94063",
"bedrooms": "3",
"bathrooms": "3",
"living_area": "2,400",
"status": "For sale",
"overview": "This move-in ready home with hardwood floors throughout has a large living room, dining room, and spacious kitchen with 2 large bedrooms downstairs and 2 full baths. Upstairs has a spacious loft area, bedroom and bathroom. The backyard is accessible off the dining and kitchen area which has 2 additional units. This home is in a great location near public transportation, shopping, and downtown.Read moreLoft area",
"time_on_zillow": "33 days",
"views": "5,291",
"saves": "96",
"images": [
"https://photos.zillowstatic.com/fp/c8a9884ca0f563fd38288ee61a219ec6-cc_ft_960.jpg",
"https://photos.zillowstatic.com/fp/f9d7a99109da7a7369cdd731e6dc1de1-cc_ft_576.jpg",
"https://photos.zillowstatic.com/fp/48a0adb1b3d34c0b1f5959ed4474aba5-cc_ft_576.jpg",
"https://photos.zillowstatic.com/fp/a730702c85aac3d69e6af9b184d0e1c2-cc_ft_576.jpg",
"https://photos.zillowstatic.com/fp/4e94c21078360505a68d4633237e48b3-cc_ft_576.jpg",
"https://photos.zillowstatic.com/fp/4559a516478e95d3218095a6b8dd3f64-cc_ft_576.jpg",
"https://photos.zillowstatic.com/fp/084a2b97777c80766dcd7f27746d18db-cc_ft_576.jpg"
]
}, ...
}
Conclusion
That's it!
In this article, you've discovered the easiest way to scrape a real estate website, such as Zillow, with Page2API - a Web Scraping API that handles any challenges for you.
The original article can be found here:
https://www.page2api.com/blog/how-to-scrape-zillow/
This content originally appeared on DEV Community and was authored by Nicolae Rotaru
Nicolae Rotaru | Sciencx (2021-11-22T15:51:40+00:00) How to scrape Zillow in no time. Retrieved from https://www.scien.cx/2021/11/22/how-to-scrape-zillow-in-no-time/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.