
This content originally appeared on DEV Community and was authored by Max Shash
Learn a practical approach to using Machine Learning for Log Analysis and Anomaly Detection in the article below.
There are many articles on applying machine learning for log analysis. However, most of them are dated, academic in nature, or don’t focus on practical outcomes. On Dev.to, most of the articles cover ML courses or the difference between deep learning and machine learning.
In this article, we want to share our real-life experience on using ML/AI for log analysis and anomaly detection with the specific purpose of automatically uncovering the root cause of software issues.
We will also discuss the various approaches to ML-based log analysis, some of the existing challenges, and provide details of our approach to solving these problems.
Disclaimer: We are Zebrium and we work on a product that uses ML on logs to identify the root cause of the software incidents. Companies like Seagate, IraLogix, Basemap, Nebulon, and Reserved.ai rely on our product daily.
Current Approaches and Challenges for AI Log Analysis
While there have been a lot of academic papers on the subject, most approaches typically fall into two categories which are explained below:
1. Using Generalized Machine Learning Algorithms
This category refers to algorithms that have been designed to detect anomalous patterns in string-based data. Two popular models in this category are Linear Support Vector Machines (SVM) and Random Forest.
SVM, for example, classifies the probability that certain words in a logline are correlated with an incident. Some words such as “error” or “unsuccessful” may correlate with an incident and receive a higher probability score than other words such as “successful” or “connected”. The combined score of the message is used to detect an issue.
Both SVM and Random Forest models use supervised machine learning for training and require a lot of data to serve accurate predictions. As we discussed above, this makes them difficult and costly to deploy in most real-life environments.
2. Using Deep Learning (Artificial Intelligence)
Deep learning is a very powerful form of ML, generally called Artificial Intelligence (AI). By training neural networks on large volumes of data, Deep Learning can find patterns in data. It is most commonly used with Supervised training on labeled datasets. AI has been used for hard problems such as image and speech recognition with great results.
One of the best academic articles on how this can be applied to logs is the Deeplog paper from the University of Utah. Their approach uses deep learning to detect anomalies in logs. Interestingly, they have also applied machine learning to parse logs into event types, which has some similarities to Zebrium’s approach discussed later, as this significantly improves the accuracy of log anomaly detection.
The challenge with this approach is that again it requires large volumes of data to become accurate. This means new environments will take longer before they can serve accurate predictions, and smaller environments may never produce enough data for the model to be accurate enough.
In addition, unlike the statistical algorithms discussed previously, Deep Learning can be very compute-intensive to train. Many data scientists use expensive GPU instances to train their models more quickly but at a significant cost. Since we need to train the model on every unique environment individually, and continuously over time, this could be an extremely expensive way to perform automated log analysis.
Some vendors have trained deep learning algorithms on common 3rd party services (i.e. MySQL, Nginx, etc.). This approach can work as it can take a large volume of publicly available datasets and error modes to train the model, and the trained model can be deployed to many users. However, as few environments are only running these 3rd party services (most also have custom software), this approach is limited to only discovering incidents in 3rd party services, and not the custom software running in the environment itself.
Why Log Anomaly Detection Is Not Enough for Effective ML-driven Log Analysis
Many approaches to machine learning for logs focus on detecting anomalies. There are several challenges with this:
1. Log Volumes Are Ever-Growing and Logs Tend to Be Noisy and Mostly Unstructured
Log volumes are ever-growing and logs tend to be noisy and mostly unstructured. When troubleshooting, noticing that a rare event has occurred is usually significant. But how do you know if a log event is rare when each instance of the same event type isn't identical (event types have fixed and variable parts)?
At the very least, machine learning would need to be able to categorize log events by type to know which are anomalous. The most common technique for this is Longest Common Substring (LCS), but the variability of individual events of the same type makes LCS accuracy challenging.
2. Log Anomaly Detection Tends to Produce Very Noisy Results. This Can Be Exacerbated by Inaccurate Categorization
Logs typically have many anomalies with only a few that are useful when detecting and/or troubleshooting problems. Therefore, a skilled expert still needs to manually sift through and analyze the anomalies to spot the signal from the noise.
For effective ML-driven log analysis, something more is needed than just log anomaly detection.
For effective ML-driven log analysis, something more is needed than just log anomaly detection.
A New Way to Detect Anomalies in Logs
In order to address the limitations described above, Zebrium has taken a multi-layered approach to use machine learning for log analysis. This approach is both more effective at finding anomalies and also provides a higher-level construct that goes beyond just log anomaly detection.
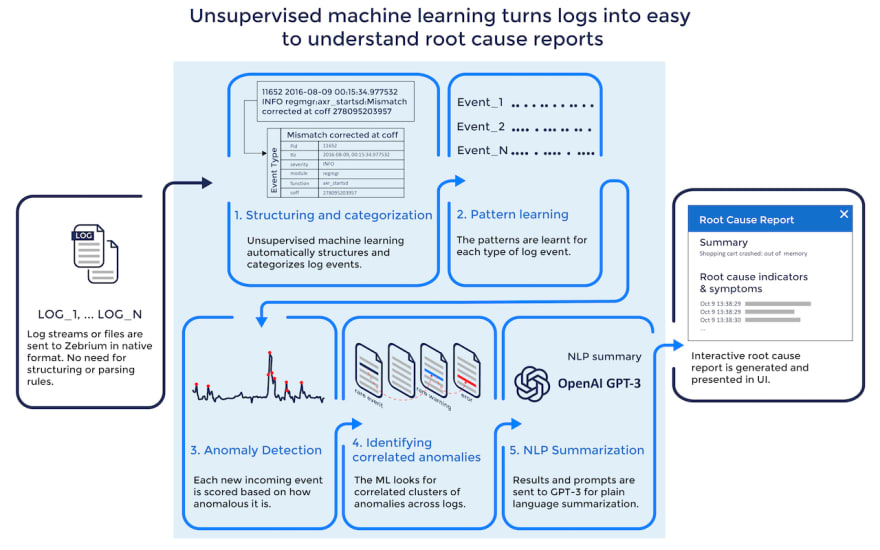
Source: zebrium.com
The technology described below is in production and relied upon by leading companies around the world.
Initially, log files or log streams are sent to the platform. Following are the key stages:
1. Structuring and Categorization of the Incoming Log Events
Zebrium starts by using unsupervised machine learning to structure and categorize log events by type automatically.
During the structuring phase, multiple ML techniques are used depending on how many examples of an event type have been seen. This allows for highly effective categorization even when there is just one, or only a few, examples. Side note: in root cause analysis, the identification of new or rare events is extremely important.
Overall, the model continues to improve with more data and is also able to adapt to changing event structures (e.g. a parameter is added to a logline), but typically achieves good accuracy within the first day.
2. Pattern Learning
Once the events have been categorized by type, the patterns for each “event type” are learned. This forms the foundation for accurate ML-based log analysis and anomaly detection.
3. Finding the Signal in the Noise-Correlated Clusters of Anomalies
As each new event is seen, it is scored based on how anomalous it is. Many factors go into anomaly scoring but the two of the biggest ones are "how rare an event is" and its severity ("how bad an event is").
Since the categorization of log events is very accurate, so too is Zebrium's ability to detect anomalous events. But even so, log anomalies on their own can still be noisy.
4. Identifying Correlated Anomalies
Machine learning next looks for hotspots of abnormally correlated anomalies across all logs. This eliminates the coincidental effect of random anomalies in logs.
The anomalous events that are uncovered as being correlated form the basis of a "root cause report" and typically contain both root cause indicators and symptoms.
5. NLP Summarization (the Last Mile Problem)
The Zebrium machine does a very good job of distilling details of a software problem down to just a few log lines, typically 5 to 20.
A summary of this, together with an appropriate prompt, is passed to the GPT-3 language model. The AI model returns a novel response that can be used for root cause summarization.
Although this feature is designated "experimental", real-world results so far have shown that approximately 40% of the time, the simple plain language summaries are very useful.
6. Delivering the Results of ML-Based Log Analysis as a Root Cause Report
An interactive root cause report is automatically created by combining the log lines from stage 4, with the plain language summary created in stage 5.
The report can be delivered via webhook to another application (such as an incident response tool) or viewed interactively in the Zebrium UI.
This Type of Log Analysis With Machine Learning Works Well in the Real World
The technology described above is in production and relied upon by leading companies around the world. There are two key use cases where users find value:
1. Finding the Root Cause of a Problem Automatically Instead of Manually Hunting Through Logs
Finding the root cause is often the biggest bottleneck in the incident response process. Using machine learning to uncover details of the problem means much faster mean time to resolution.
2. Proactive Detection of New or Unknown Problems or Incidents That Are Missed by Other Tools.
While most monitoring tools will notice when something major occurs, there are many problems that go unnoticed because they are not detected by any existing rules or thresholds.
Have you tried using ML/AI for Log Analysis? If yes, please share your results in the comments below. We would love to hear from you.
The article was originally posted on Dzone.
This content originally appeared on DEV Community and was authored by Max Shash
Max Shash | Sciencx (2021-11-23T21:58:11+00:00) Machine Learning for Anomaly Detection: Decreasing Time to Find Root Cause by Automating Log Analysis. Retrieved from https://www.scien.cx/2021/11/23/machine-learning-for-anomaly-detection-decreasing-time-to-find-root-cause-by-automating-log-analysis/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.