
This content originally appeared on Chromium Blog and was authored by Chromium Blog

Chrome is fast, but there's always room for improvement. Often, that's achieved by carefully crafting the algorithms that make up Chrome. But there's a lot of Chrome, so why not let computers do at least some part of our work? In this installment of The Fast And the Curious, we'll show you several changes in how we build Chrome to achieve a 25.8% higher score on Speedometer on Windows and a 22.0% increase in browser responsiveness.
Why speed?
So why do we care about performance benchmarks? It's not a simple "higher numbers is better" chasing of achievements - performance was so important to Chrome that we embedded in our core principles, the "4Ss" - Speed, Security, Stability, Simplicity. And speed matters because we want a browser that responds quickly. Speed matters so much because we want to build a faster and more responsive browser. And by improving the speed of the browser, there's the additional benefit of maximizing battery use, so you don't have to charge your laptop/devices as often.Speed? Size? Something Else?
Let's look at a typical optimization.int foo();int fiver(int num) {for(int j = 0; j < 5; j++)num = num + foo();return num;}
The compiler can either compile this as a loop (smaller), or turn it into five additions in a row (faster, but bigger)
You save the cost of checking the end of the loop and incrementing a variable every time through the loop. But in exchange, you now have many repeated calls to foo(). If foo() is called a lot, that is a lot of space.
And while speed matters a lot, we also care about binary size. (Yes, we see your memes!) And that tradeoff - exchanging speed for memory, and vice versa, holds for a lot of compiler optimizations.
So how do you decide if the cost is worth it? One good way is to optimize for speed in areas that are run often, because your speed wins accumulate each time you run a function. You could just guess at what you inline (your compiler can do this, it's called "a heuristic", it's an educated guess), and then measure speed and code size.
The result: Likely faster. Likely larger. Is that good?
Ask any engineer a question like that, and they will answer “It depends”. So, how do you get an answer?
The More You Know… (profiling & PGO)
The best way to make a decision is with data. We collect data based on what gets run a lot, and what gets run a little. We do that for several different scenarios, because our users do lots of different things with Chrome and want them to be fast.Our goal is collecting performance data in various scenarios, and using that to guide the compiler. There are 3 steps needed:
- Instrument for profiling
- Run that instrumented executable in various scenarios
- Use the resulting performance profile to guide the compiler.
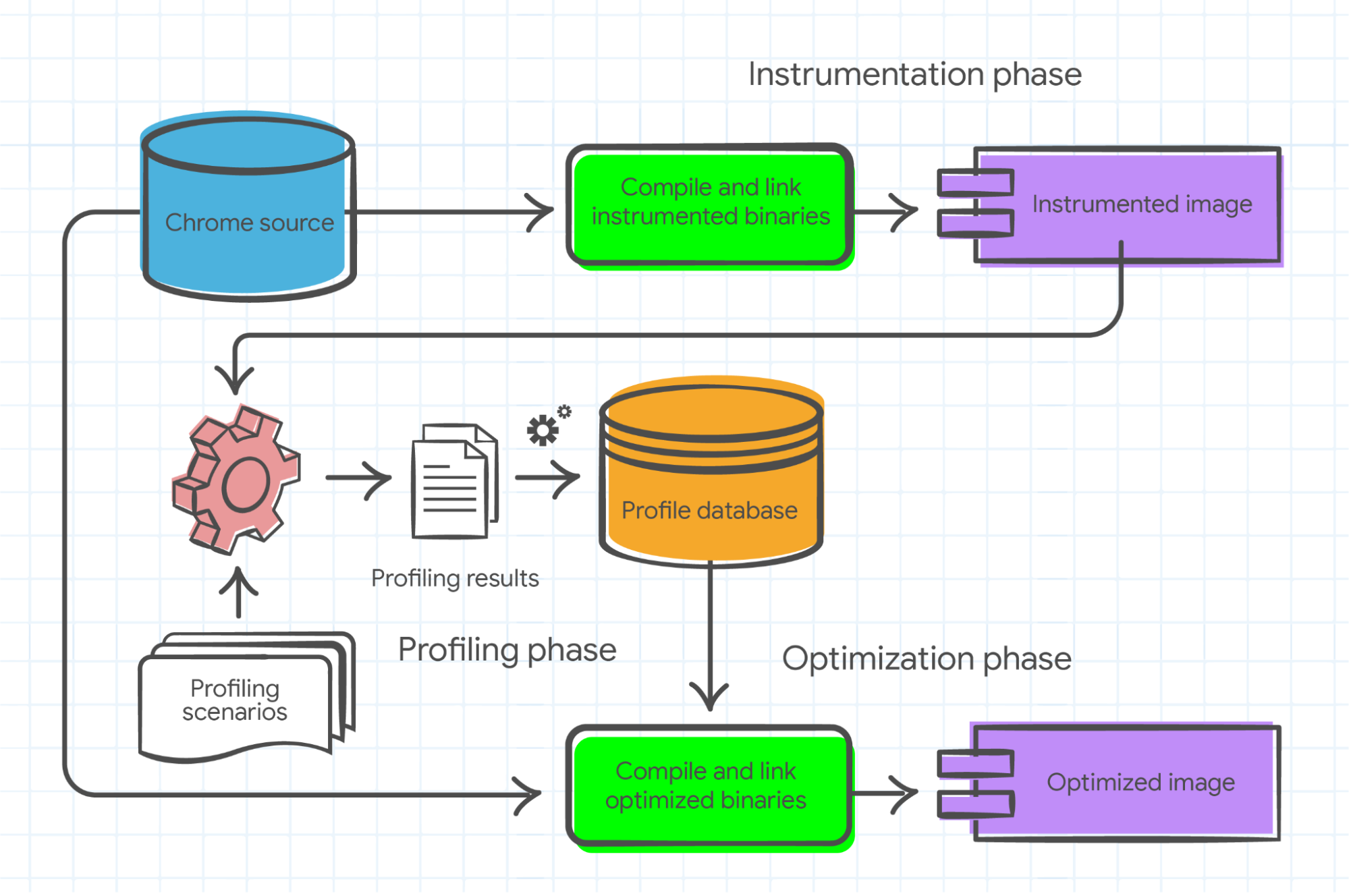
But we can do more (ThinLTO)
That's a good start, but we can do better. Let's look at inlining - the compiler takes the code of a called function and inserts all of it at the callsite.inline int foo() { return 3; };int fiver_inline(int num) {for(int j = 0; j < 5; j++)num = num + foo();return num;}
When the compiler inlines foo(), it turns into
int fiver_inline(int num) {for(int j = 0; j < 5; j++)num = num + 3;return num;}
Not bad - saves us the function call and all the setup that goes with having a function. But the compiler can in fact even do better - because now all the information is in one place. The compiler can apply that knowledge and deduce that fiver_inline() adds the number three and does so 5 times - and so the entire code is boiled down to
return num + 15;
Which is awesome! But the compiler can only do this if the source code for foo() and the location where it is called are in the same source file - otherwise, the compiler does not know what to inline. (That's the fiver() example). A trivial way around that is to combine all the source files into one giant source file and compile and link that in one go.

There's just one downside - that approach needs to generate all of the machine code for Chrome, all the time. Change one line in one file, compile all of Chrome. And there's a lot of Chrome. It also effectively disables caching build results and so makes remote compilation much less useful. (And we rely a lot on remote compilation & caching so we can quickly build new versions of Chrome.)
So, back to the drawing board. The core insight is that each source file only needs to include a few functions - it doesn't need to see every single other file. All that's needed is "cleverly" mixing the right inline functions into the right source files.

Now we're back to compiling individual source files. Distributed/cached compilation works again, small changes don't cause a full rebuild, and since "ThinLTO" does just inline a few functions, and it is relatively little overhead.
Of course, the question of "which functions should ThinLTO inline?" still needs to be answered. And the answer is still "the ones that are small and called a lot". Hey, we know those already - from the profiles we generated for Profile Guided Optimization (PGO). Talk about lucky coincidences!
But wait, there's more! (Callgraph Sorting)
We've done a lot for inlined function calls. Is there anything we can do to speed up functions that haven't been inlined, too? Turns out there is.One important factor is that the CPU doesn't fetch data byte by byte, but in chunks. And so, if we could ensure that a chunk of data doesn't just contain the function we need right now, but ideally also the ones that we'll need next, we could ensure that we have to go out and get chunks of data less often.
In other words, we want functions that are called right after the other to live next to each other in memory also ("code locality"). And we already know which functions are called close to each other - because we ran our profiling and stored performance profiles for PGO.
We can then use that information to ensure that the right functions are next to each other when we link.
I.e.
g.cextern int f1();extern int f2();extern int f3();int g() {f1();for(..) {f3();}f1();f2();}
could be interpreted as "g() calls f3() a lot - so keep that one really close. f1() is called twice, so… somewhat close. And if we can squeeze in f2, even better". The calling sequence is a "call graph", and so this sorting process is called "call graph sorting".
Just changing the order of functions in memory might not sound like a lot, but it leads to ~3% performance improvement. And to know which functions calls which other ones a lot… yep. You guessed it. Our profiles from the PGO work pay off again.
One more thing.
It turns out that the compiler can make even more use of that profile data for PGO. (Not a surprise - once you know where the slow spots are, exactly, you can do a lot to improve!). To make use of that, and enable further improvements, LLVM has something called the "new pass manager". In a nutshell, it's a new way to run optimizations within LLVM, and it helps a lot with PGO. For much more detail, I'd suggest reading the LLVM blog post.Turning that on leads to another ~3% performance increase, and ~9MB size reduction.
Why Now?
Good question. One part of that is that PGO & profiling unlock an entire new set of optimizations, as you've seen above. It makes sense to do that all in one go.The other reason is our toolchain. We used to have a colorful mix of different technologies for compilers and linkers on different platforms.

And since this work requires changes to compilers and linkers, that would mean changing the build - and testing it - across 5 compilers and 4 linkers. But, thankfully, we've simplified our toolchain (Simplicity - another one of the 4S's!). To be able to do this, we worked with the LLVM community to make clang a great Windows compiler, in addition to partnering with the LLVM community to create new ELF (Linux), COFF (Windows), and Mach-O (macOS, iOS) linkers.

And suddenly, it's only a single toolchain to fix. (Almost. LTO for lld on MacOS is being worked on).
Sometimes, the best way to get more speed is not to change the code you wrote, but to change the way you build the software.
Posted by Rachel Blum, Engineering Director, Chrome Desktop
This content originally appeared on Chromium Blog and was authored by Chromium Blog
Print
Share
Comment
Cite
Upload
Translate
Updates

There are no updates yet.
Click the Upload button above to add an update.
APA
MLA
Chromium Blog | Sciencx (2021-12-01T18:00:00+00:00) Faster Chrome – Let The Compiler do the work. Retrieved from https://www.scien.cx/2021/12/01/faster-chrome-let-the-compiler-do-the-work/
" » Faster Chrome – Let The Compiler do the work." Chromium Blog | Sciencx - Wednesday December 1, 2021, https://www.scien.cx/2021/12/01/faster-chrome-let-the-compiler-do-the-work/
HARVARDChromium Blog | Sciencx Wednesday December 1, 2021 » Faster Chrome – Let The Compiler do the work., viewed ,<https://www.scien.cx/2021/12/01/faster-chrome-let-the-compiler-do-the-work/>
VANCOUVERChromium Blog | Sciencx - » Faster Chrome – Let The Compiler do the work. [Internet]. [Accessed ]. Available from: https://www.scien.cx/2021/12/01/faster-chrome-let-the-compiler-do-the-work/
CHICAGO" » Faster Chrome – Let The Compiler do the work." Chromium Blog | Sciencx - Accessed . https://www.scien.cx/2021/12/01/faster-chrome-let-the-compiler-do-the-work/
IEEE" » Faster Chrome – Let The Compiler do the work." Chromium Blog | Sciencx [Online]. Available: https://www.scien.cx/2021/12/01/faster-chrome-let-the-compiler-do-the-work/. [Accessed: ]
rf:citation » Faster Chrome – Let The Compiler do the work | Chromium Blog | Sciencx | https://www.scien.cx/2021/12/01/faster-chrome-let-the-compiler-do-the-work/ |
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.