
This content originally appeared on DEV Community and was authored by huangl68
What is Federated Learning
Federated learning is a machine learning technique that trains an algorithm across multiple decentralized edge devices or servers holding local data samples, without exchanging them. Instead of collecting data on a single server, the data remains private on their servers and only the predictive models travel between the servers – never the data. The goal of federate learning is for each participant to benefit from a larger pool of data than their own, resulting in increased ML performance, while respecting data ownership and privacy.
Categorization of Federated Learning
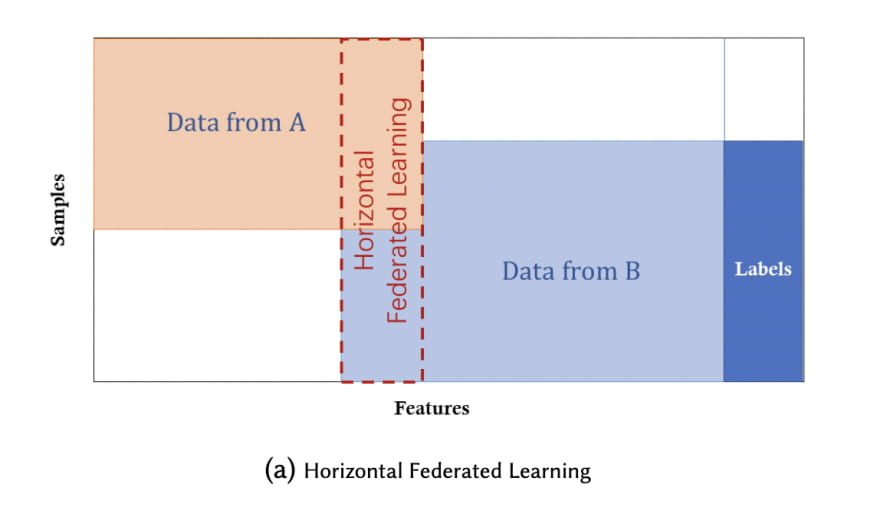
Horizontal Federated Learning
Horizontal federated learning is introduced in the scenarios that data sets share the same feature space but different in samples. For example, two regional banks may have very different user groups from their respective regions, and the intersection set of their users is very small. However, their business is very similar, so the feature spaces are the same.
Vertical Federated Learning
Vertical federated learning is applicable to the cases that two data sets share the same sample ID space but differ in feature space. For example, consider two different companies in the same city, one is a bank, and the other is an e-commerce company. Their user sets are likely to contain most of the residents of the area, so the intersection of their user space is large. However, since the bank records the user’s revenue and expenditure behaviour and credit rating, and the e-commerce retains the user’s browsing and purchasing history, their feature spaces are very different.

Architecture for Vertical Federated Learning
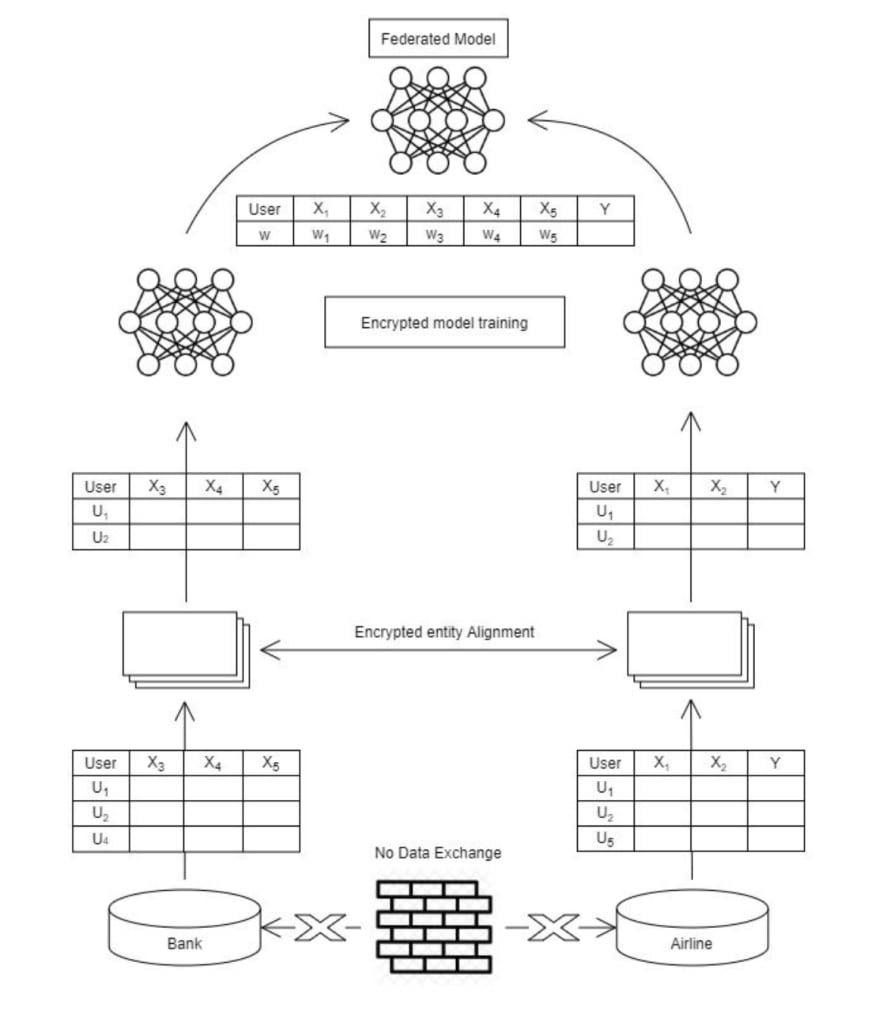
Encrypted entity alignment. Since the user groups of the two companies are not the same, the system uses the encryption-based user ID alignment techniques such as Private Intersection Set(PSI) to confirm the common users of both parties without exposing their respective data. During the entity alignment, the system does not expose users that do not overlap with each other.
-
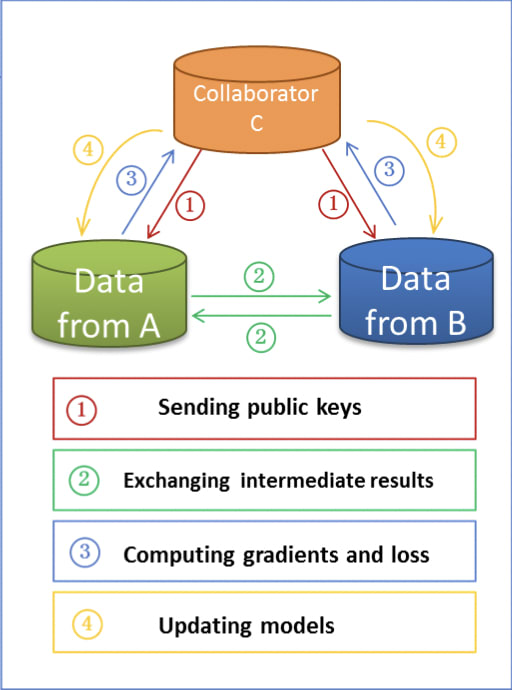
Encrypted model training. After determining the common entities, we can use these common entities’ data to train the machine learning model. The training process can be divided into the following four steps
- collaborator C creates encryption pairs, send public key to A and B;
- A and B encrypt and exchange the intermediate results for gradient and loss calculations;
- A and B computes encrypted gradients and adds additional mask, respectively,and B also computes encrypted loss; A and B send encrypted values to C;
- C decrypts and send the decrypted gradients and loss back to A and B; A and B unmask the gradients, update the model parameters accordingly.
This content originally appeared on DEV Community and was authored by huangl68
huangl68 | Sciencx (2021-12-10T23:27:23+00:00) Intro to Federated Learning. Retrieved from https://www.scien.cx/2021/12/10/intro-to-federated-learning/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.