
This content originally appeared on DEV Community and was authored by Matvey Romanov
When we talk about data structures in JavaScript, we can't get past the most important structure of this language – the object. Let's take a look at what it has under the hood and why hashing algorithms are needed.
Associative array
JavaScript objects are an example of an associative array. Unlike regular arrays, associative arrays do not have indexes, but rather keys (usually strings). Otherwise, there is almost no difference – the keys are unique and each corresponds to a certain value. Associative arrays are also called dictionaries or maps (from the English map). They allow you to conveniently represent complex data of various types (for example, user information) and are very popular in JavaScript programming.
In terms of efficiency, associative arrays are superior to other data structures: all basic operations in them are performed in constant time O(1). For example, to add a new element to the middle of a simple array, you will have to reindex it (we talked about this in the first part). The complexity of this operation is O (n). In an associative array, you simply add a new key to which the value is associated.
Hash tables
However, associative arrays have their own weakness – they cannot be stored in the computer's memory as it is, unlike a regular indexed array. For storing associative arrays, a special structure is used – a hash table (hash map).
Associative arrays are in a sense syntactic sugar, a more convenient add-on to the hash table.
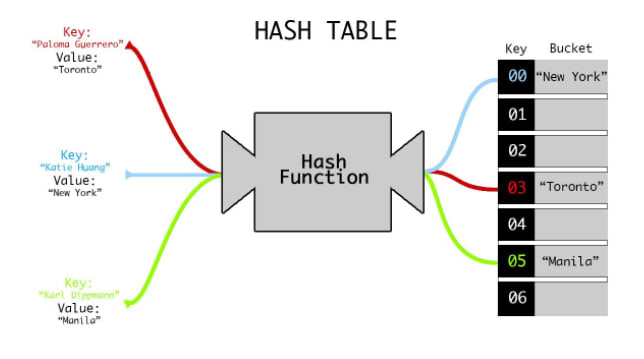
Schematic diagram of the hash table operation
Hashing
To turn the key of an associative array into an index of a regular one, you need to perform 2 operations:
- Find hash (hash the key);
- Convert the found hash to the index of the resulting array.
That is, the final task is to convert the key to a numeric index, but it is usually performed in two steps.
Calculating the hash
The hash function receives input data and converts it to a fixed – length hash string or number. You've probably heard about some of the hash algorithms: CRC32, MD5, and SHA. The key can be represented by any data type that the hash function can handle.
Example hash-ID of a commit in git. When you save changes, they are hashed and you get something like 0481e0692e2501192d67d7da506c6e70ba41e913. This is the hash calculated for your changes.
The implementation of a hash function can be very different. For example, you can use the simplest identity function, which takes an input parameter and returns it unchanged:
const hash = key => key;
If the keys are strings, you can calculate the sum of the codes of all characters:
const hash = string => {
let result = 0;
for (let i = 0; i < string.length; i++) {
result += string.charCodeAt(i);
}
return result;
};
For example, name the hash value for a key is 417, and the hash value for a key age is 301.
All of these are not very good examples of hash functions, they are usually more complex in real life, but it is important for us to understand the general principle. If you know what data your hash table is going to work with, you can choose a more specific hash function than in the general case.
Important: for the same input value, the hash function always returns the same result.
Casting to an index
Usually, the size of the resulting array is determined immediately, so the index must be within the specified limits. The hash is usually larger than the index, so it needs to be further converted.
To calculate the index, you can use the remainder of dividing the hash by the size of the array:
const index = Math.abs(hash) % 5;
It is important to remember that the longer the array is, the more space it takes up in memory.
Let's use our hash function and convert an associative array to a regular one:
// associative array
const user = {
name: 'John',
age: 23
};
// default array, length = 5
[
undefined,
['age', 23],
['name', 'John'],
undefined,
undefined
]
The key name corresponds to index 2, and the key age corresponds to index 1.
We store not only the values in the resulting array, but also the original keys. Why this is necessary, we will find out very soon.
If we now want to get an array element with a key name, then we need to hash this key again to find out at what index the associated element is located in the array.
Collisions
Do you already see the weak point of such transformations?
The key in an associative array can be absolutely any string of any length – the number of options is infinite. And the number of indexes in the array is limited. In other words, there are not enough indexes for all keys, and for some input data, the hash function will return the same result. This is called a collision.
There are two common ways to resolve collisions.
Open addressing
Let's assume that we passed the hash function some key of an associative array (key1) and received from it the 2-index of a regular array that corresponds to this key.
[ undefined, undefined, [key1, value1], undefined, undefined, undefined, undefined ]
Then we pass it another key – key2 – and again we get 2 – there was a collision. We can't write new data under the same index, so we just start looking for the first free space in the array. This is called linear probing. The next index after 2-3 – is free, we write new data to it:
[ undefined, undefined, [key1, value1], [key2, value2], undefined, undefined, undefined ]
For the third key key3, the hash function returns index 3 – but it is already occupied by the key key2, so we have to search for free space again.
[ undefined, undefined, [key1, value1], [key2, value2], [key3,value3], undefined, undefined ]
The record is clear, but how can you find the desired key in such a hash table, for example, key3? Similarly, we first run it through the hash function and get 3. We check the array element at this index and see that this is not the key we are looking for. That's why we store the source key in a hash table, so that we can make sure that the found element is exactly the one we need. We just start moving further through the array, iterating over each element and comparing it with the key we are looking for.
The more densely populated the hash table is, the more iterations you need to do to detect a key that is out of place.
Chain method
In this approach, values corresponding to a single index are stored as a linked list. each index of the array corresponds not to one element, but to a whole list of elements for which the hash function calculated one index. If a collision occurs, the new element is simply added to the end of the list.
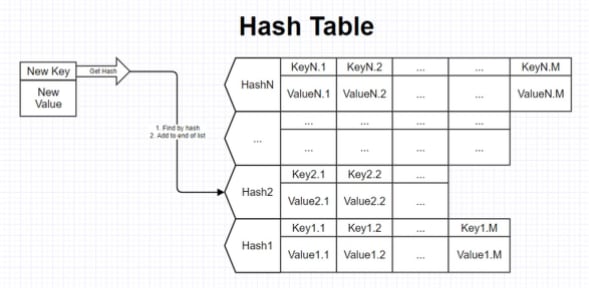
When searching for an element with a specific key in such a hash table, we first calculate its hash, determine the desired array index, and then look through the entire list until we find the desired key.
This implementation makes it easy to delete items from the table, because in a linked list, the delete operation takes constant time.
Implementing a hash table in JavaScript
The hash table must implement the associative array interface, i.e. provide three main methods:
- adding a new key-value pair;
- search for a value by key;
- deleting a pair by key.
The smaller the hash table size (array length), the more frequent collisions will occur. We'll take a small number, 32, as an example. In practice, prime numbers (which are divisible only by one and by themselves) are often used for the size of a hash table. It is assumed that this results in fewer collisions.
To resolve collisions, we will use the chain method. To do this, we need the linked list class LinkedList.
const hashTableSize = 32;
class HashTable {
constructor() {
this.buckets = Array(hashTableSize).fill(null);
}
hash(key) {
let hash = Array.from(key).reduce((sum, key) => {
return sum + key.charCodeAt(0);
}, 0);
return hash % hashTableSize;
}
set(key, value) {
// calculating the hash for the key
let index = this.hash(key);
// create if there is no list for this hash yet
if (!this.buckets[index]) {
this.buckets[index] = new LinkedList();
}
let list = this.buckets[index];
// check if the key was added earlier
let node = list.find((nodeValue) => {
nodeValue.key === key;
});
if (node) {
node.value.value = value; // updating the value for the key
} else {
list.append({ key, value }); // adding a new item to the end of the list
}
}
get(key) {
// calculating the hash for the key
let index = this.hash(key);
// we find the corresponding list in the array
let list = this.buckets[index];
if (!list) return undefined;
// we are looking for an item with the desired key in the list
let node = list.find((nodeValue) => {
return nodeValue.key === key;
});
if (node) return node.value.value;
return undefined;
}
delete(key) {
let index = this.hash(key);
let list = this.buckets[index];
if (!list) return;
let node = list.find((nodeValue) => nodeValue.key === key);
if (!node) return;
list.delete(node.value);
}
}
Efficiency of basic operations in the hash table
The main operations in a hash table consist of two stages::
- calculating the hash for a key and checking the element corresponding to this hash in the resulting array.
- iterate through other elements if you didn't find the right one right away.
The first stage always takes constant time, the second – linear, that is, it depends on the number of elements that need to be sorted.
The effectiveness of a hash table depends on three main factors::
- Hash function that calculates indexes for keys. Ideally, it should distribute indexes evenly across the array;
- The size of the table itself – the larger it is, the fewer collisions there are;
- Collision resolution method. For example, the chaining method reduces the operation of adding a new element to constant time.
In the end, the fewer collisions, the more efficient the table works, since you don't need to iterate through many elements if the search was not found immediately by hash. In general, the hash table is more efficient than other data structures.
Using hash tables
Hash tables are widely used in programming, for example, for authorization mechanisms, indexing large amounts of information (databases), caching, or searching. Another common case is the implementation of unordered sets, which we will discuss in the next part of the cycle.
In JavaScript, hash tables in their pure form are rarely used. Usually, all their work is successfully performed by ordinary objects (associative arrays) or more complex Maps. At the same time, at a lower level (program interpretation) hash tables are used to represent objects.
Objects and hash tables are often used as auxiliary structures when optimizing various actions. For example, to count the number of occurrences of different characters in a string.
function countSymbols(string) {
const hash = {};
[...string].forEach(s => {
let symbol = s.toLowerCase();
if (!(symbol in hash)) hash[symbol] = 0;
hash[symbol]++;
});
return hash;
}
countSymbols('Hello, world!');
/*
{ " ": 1, "!": 1, ",": 1, d: 1, e: 1, h: 1, l: 3, o: 2, r: 1, w: 1 }
*/
Hashing, encoding, and encryption
Hashing is an algorithm that works only in one direction. It is impossible to get the original value from the hash, and there is no practical need for this, because the main task of hashing is to distinguish input data, not to save it.
In some cases, we need a two-way transformation. For example, you want to leave a secret message to a friend that no one else can read. This is where encryption algorithms come to the rescue.
You convert the source text to some other sequence of characters using a cipher. Such a sequence is either completely unreadable (just a set of letters), or it has a completely different meaning. If someone intercepts this email, they simply won't understand what you were trying to say. Your friend knows that the message is encrypted and knows how to decrypt it. Thus, the main purpose of encryption is to hide information from unauthorized persons. To do this, use a secret key or even two keys – one for encryption, the second for decryption.
In addition to encryption, there is also encoding. It is close to encryption in essence, but different in purpose. Encoding is used to simplify the transmission of information, for example, over telecommunication lines. Your message is converted to a sequence of bits, delivered to the recipient over the wire, and restored again at the other end. No keys are used in this case. Such codes not only solve the problem of communication, but also often try to deal with possible interference during transmission, that is, they have the ability to repair damage. One of the most famous codes is Morse code.
Conclusion
While dealing with hash tables, we once again made sure that almost everything in programming is done through ... arrays. So associative objects under the hood also use them, calculating the index for each key using hash functions.
This content originally appeared on DEV Community and was authored by Matvey Romanov
Matvey Romanov | Sciencx (2021-12-19T20:09:01+00:00) Common algorithms and data structures in JavaScript: objects and hashing. Retrieved from https://www.scien.cx/2021/12/19/common-algorithms-and-data-structures-in-javascript-objects-and-hashing/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.