
This content originally appeared on DEV Community and was authored by Adnan Rahić
With datasets becoming enormous, developers need to find new ways of making data apps fast, responsive, and cost-effective. Pre-aggregations, one of the most powerful features of Cube, simplify this monumental feat significantly.
Today, I want to talk about using and managing pre-aggregations with Cube, an open-source API layer for data apps, and Cube Cloud, a fully managed platform that runs and scales Cube apps in production.
I want to give you a detailed insight into what pre-aggregations are, which scenarios you might encounter while working with them, and how both self-hosted Cube and Cube Cloud can help in solving them.
What are Pre-Aggregations
Pre-aggregations are condensed versions of the source data. They are materialized ahead of time and persisted as tables separately from the raw data. Querying pre-aggregations reduces the execution time, as the queried data is orders of magnitude smaller than the raw data.

Pre-aggregations are highly recommended to be used in virtually any Cube app in production. Let's talk about popular scenarios you might encounter while working with pre-aggregations.
How to Store Pre-Aggregations
Pre-aggregation data should be stored separately from the raw data. The recommended way is to store pre-aggregations in Cube Store, a purposefully built and performant storage layer. How do you set up and run Cube Store?
Self-hosted Cube. When developing Cube apps locally and running Cube in dev mode, you don't need to set up anything. Cube Store will run automatically within the Cube process, and pre-aggregation data will be stored as files under the .cubestore directory.
Running Cube in production will require setting up more complex infrastructure. You need an API instance, a refresh worker, a Redis instance as well as a Cube Store cluster that will consist of a single router node and at least a couple of worker nodes. If needed, you'll scale Cube Store by adding more worker nodes.
You can find a Kubernetes deployment example in the docs and a Helm chart example on GitHub that might help you to set everything up on-premise or in a cloud provider of your choice like AWS or GCP.

Cube Cloud. When developing and running Cube apps in Cube Cloud, you can use readily available managed infrastructure that includes a Cube Store cluster. Cube Cloud will automatically scale the Cube Store cluster as needed and allocate other services such as a refresh worker once you select "Cluster mode" in Settings.

How to Create a Pre-Aggregation
Queries won't be accelerated until pre-aggregations are defined and built.
Self-hosted Cube. You can write the pre-aggregation definition by hand. Please see the docs on pre-aggregation definitions in the data schema where every parameter is explained.
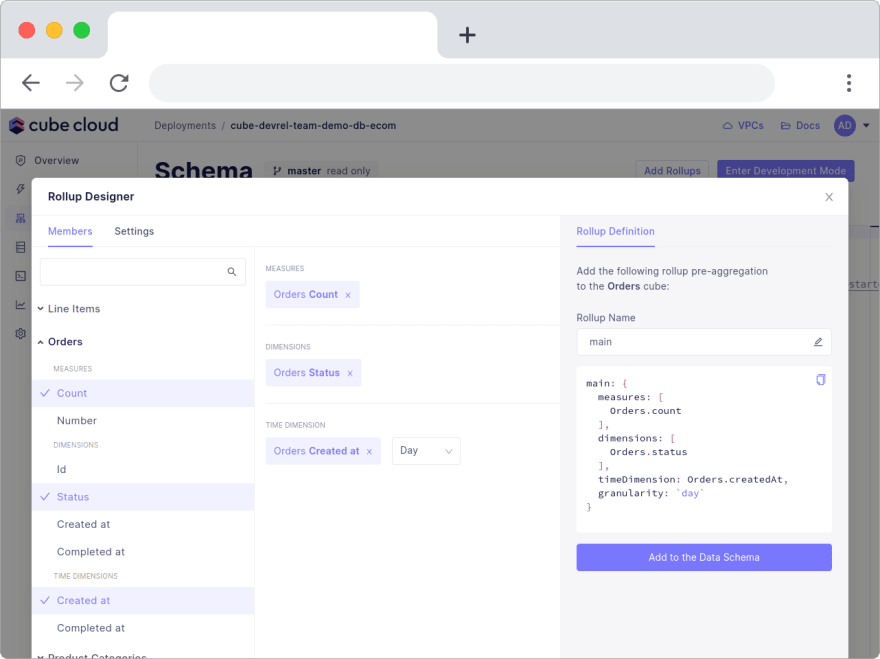
However, what I like doing is to run the query I want to accelerate first. Then, use the Rollup Designer by clicking on the Query was not accelerated with pre-aggregation → link to configure a pre-aggregation definition.

In the Members section you see the measures, dimensions, and time dimensions the pre-aggregation will be configured to accelerate. These need to match the query in order for it to be accelerated. You can make sure to get a match in the Query Compatibility tab.

You can make further improvements to the pre-aggregation's performance with partitions, refreshing, and incremental builds.

Once you're happy with the configuration in the Rollup Designer, click the Add to the Data Schema button to add the pre-aggregation to the schema file.

Cube Cloud. The process is exactly the same for Cube Cloud, with one added convenience. You can also use Rollup Designer on the Schema page when you're working with the data schema.
How to Build Pre-Aggregations
Pre-aggregations are built on-demand or based on a schedule. The build process always takes time.
Self-hosted Cube. Pre-aggregation builds can be triggered in two ways, either by a Cube refresh worker or on-demand when the Cube API instance gets a query that matches a pre-aggregation definition.
In the latter case, the API will trigger a build of the pre-aggregation and be stuck waiting for it to finish in order to return a value. You do not want this to happen, ever!
A Cube refresh worker will trigger pre-aggregation builds periodically and make sure Cube Store always has pre-aggregations ready and waiting to be queried.
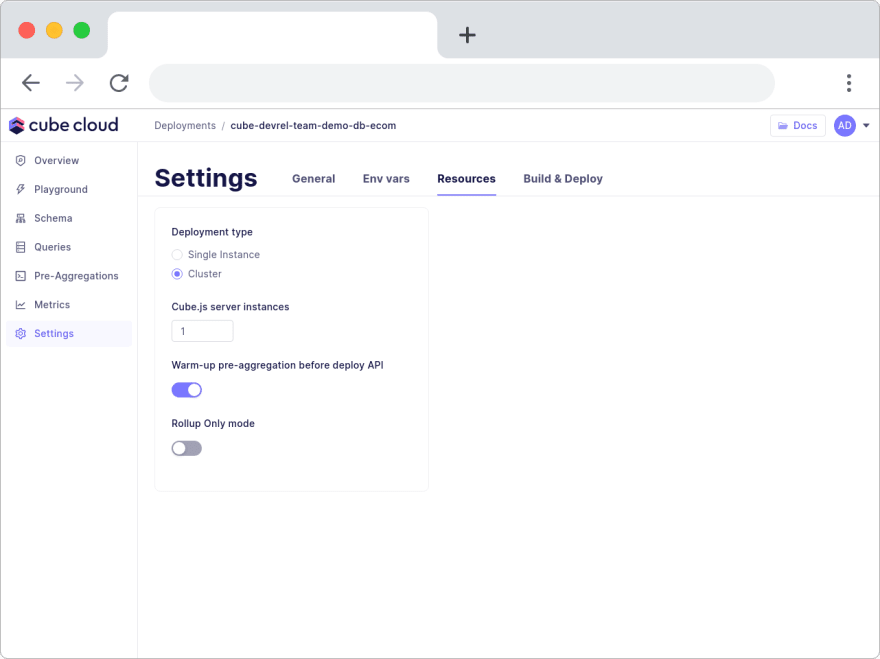
Cube Cloud. Enabling the warm-up of pre-aggregations before deploying the API will make sure to first build all pre-aggregations before deploying a new version of the API. You do this under Settings → Resources by enabling the Warm-up pre-aggregations before deploy API toggle.
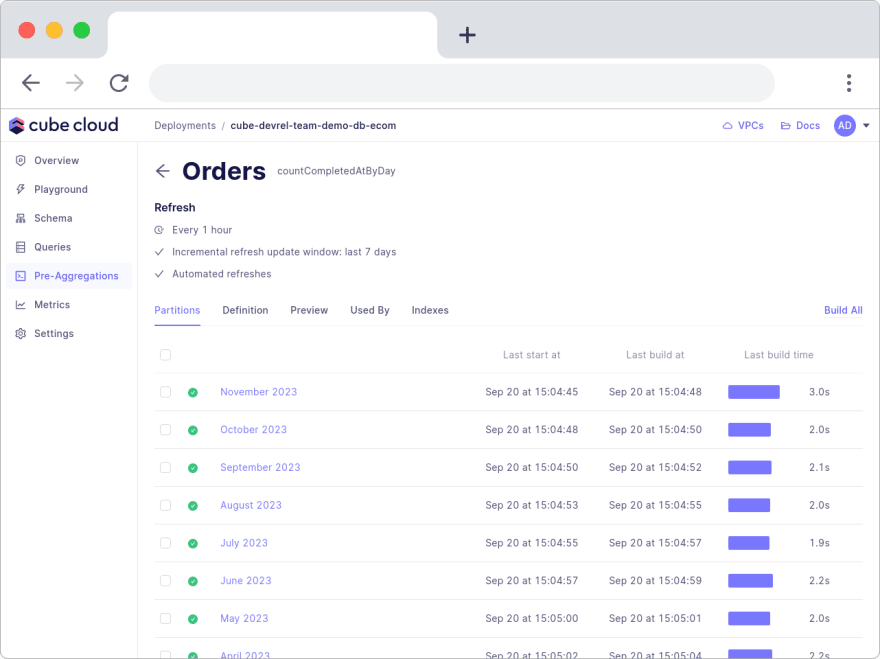
You can also build pre-aggregations manually with the Build All button, or select individual partitions to build. This is helpful when you explicitly need to re-build pre-aggregations. It might be because you deployed a new version of your Cube app or you edited an existing pre-aggregation definition. Another option might be if you decide to disable warming up the pre-aggregations before deploying the API.
How to Optimize Pre-Aggregation Build Times
The time it takes to build pre-aggregations can vary based on the size of the partitions. The bigger a partition is, the longer it will take to build. Additionally, a major pitfall is not having detailed insight into when pre-aggregation builds are triggered and how long they took.
Self-hosted Cube. The two key factors that improve pre-aggregation build times are the partitionGranularity and refreshKey parameters.
The partitionGranularity defines a partition based on a time dimension. A partition is a shard of data. The process of partitioning will shard data into multiple tables. If you set the partitionGranularity: 'month', it will partition the data into one table per month.
Partitioning is a huge performance improvement for pre-aggregation build and refresh times. This is improved further by incrementally refreshing only the last set of partitions. It leads to less data being re-built, meaning faster builds with reduced cost.
The refreshKey parameter is, by default, set to every 1 hour. We set it to every 1 hour by default as it fits most generic use cases. Having a refreshKey with an every field defines the frequency with which the pre-aggregation is rebuilt. Every 1 hour would mean on the hour, every hour. Meaning at 12:00 AM, 1:00 AM, 2:00 AM, and so on.
Adding the incremental: true parameter will refresh the most recent partition, which is incredibly useful if you are working with historical data that won't change.
Lastly, adding a updateWindow: '7 day' means going back for a specified amount of time and refreshing the partitions that fit into that time frame.
Cube Cloud. Building pre-aggregations without partitionGranularity takes longer than building them as partitions.
Using a pre-aggregation definition with partitioning, versus without partitioning does not look very different. In the sample below you can see that adding partitioning only requires three lines of code.
countCreatedAtByDay: {
measures: [Orders.count],
dimensions: [Orders.status],
refreshKey: {
every: `1 hour`,
updateWindow: `7 day`, // refresh partitions in this timeframe
incremental: true // only refresh the most recent partition
},
partitionGranularity: `month`, // adds partitioning by month
timeDimension: Orders.createdAt,
granularity: `day`
},
However, the build times speak for themselves.

Additionally, you get detailed insight into when pre-aggregations were last built and exactly how long the builds took.
How to Check the Status of Pre-Aggregations and Partitions
After adding pre-aggregation definitions to your schema, you need to be aware if pre-aggregations have been successfully built. Not knowing pre-aggregation build history, if partitions were built at all and when, how long the builds took, can all negatively impact user experience.
If you have multiple pre-aggregations with different or complex refreshKeys, you need to know how up-to-date the pre-aggregated data is and when the pre-aggregation is going to be rebuilt.
This will make sure your users are seeing up-to-date data with peak performance at all times.
Self-hosted Cube. The Cube refresh worker and Cube Store routers log the state of pre-aggregations. You can see when the execution, loading, or saving of a pre-aggregation happens. This is what a sample log from the Cube Store routers looks like.
Executing Load Pre Aggregation SQL: scheduler-40686894-bd8f-417c-a341-af4c1e4e6bf6
--
SELECT
"orders".status "orders__status", date_trunc('day', ("orders".created_at::timestamptz AT TIME ZONE 'UTC')) "orders__created_at_day", count("orders".id) "orders__count"
FROM
public.orders AS "orders" WHERE ("orders".created_at >= '2023-11-01T00:00:00.000Z'::timestamptz AND "orders".created_at <= '2023-11-30T23:59:59.999Z'::timestamptz) GROUP BY 1, 2
--
2021-09-08 08:44:34,959 INFO [cubestore::cluster] <pid:1> Running job completed (12.55392ms): IdRow { id: 535, row: Job { row_reference: Table(Tables, 535), job_type: TableImportCSV("temp://dev_pre_aggregations.orders_main20231101_z034ipqc_sntekhp5_1gjgtvi.csv.gz"), last_heart_beat: 2021-09-08T08:44:34.958894076Z, status: Completed } }
Cube Store supports a subset of MySQL protocol. It exposes port 3306. You can use the standard MySQL CLI client to connect to Cube Store, or any other client compatible with the MySQL protocol.
You connect to Cube Store with the MySQL CLI client like this:
mysql -h <CUBESTORE_IP> --user=cubestore -pcubestore
Once connected to the MySQL CLI, run this SQL command to see which tables are stored in Cube Store.
mysql> SELECT * FROM information_schema.tables;
+----------------------+-----------------------------------------------+
| table_schema | table_name |
+----------------------+-----------------------------------------------+
| dev_pre_aggregations | orders_main20210101_5qjmf21t_nm2ig41s_1gjgraf |
| dev_pre_aggregations | orders_main20210201_uobzqlem_sz20hm0u_1gjgrag |
| dev_pre_aggregations | orders_main20210301_wslzhgsp_qyh1uclp_1gjgrah |
| dev_pre_aggregations | orders_main20210401_3saakqgn_gsq0jl30_1gjgrai |
| dev_pre_aggregations | orders_main20210501_u0u2qipc_eserpdse_1gjgrai |
| dev_pre_aggregations | orders_main20210601_recoxqse_pwslyqod_1gjgraj |
| dev_pre_aggregations | orders_main20210701_yfs1mnjz_q5l4tjwz_1gjgraj |
| dev_pre_aggregations | orders_main20210801_frhjq5yg_hevt225i_1gjgrak |
| dev_pre_aggregations | orders_main20210901_zceilsss_saxibkj0_1gjgral |
| dev_pre_aggregations | orders_main20211001_bykzagbx_frt1vmhn_1gjgral |
| dev_pre_aggregations | orders_main20211101_ooxvqjhl_rikgvl0q_1gjgram |
| dev_pre_aggregations | orders_main20211201_4lz4evnw_tuyd1tz_1gjgran |
| dev_pre_aggregations | orders_main20211001_2qjkvn24_apusbfpo_1gjgrjb |
| dev_pre_aggregations | orders_main20210601_irjg1lj1_vhtdn2q_1gjgrjb |
| dev_pre_aggregations | orders_main20210401_sb5f5vwh_jbkn43cn_1gjgrjb |
| dev_pre_aggregations | orders_main20210901_wzxpxmyl_qs3yhswd_1gjgrjb |
| dev_pre_aggregations | orders_main20210501_0zj2jntl_c0ku1ixv_1gjgrjb |
| dev_pre_aggregations | orders_main20211101_ekkyobcj_uld514mr_1gjgrjb |
| dev_pre_aggregations | orders_main20210301_2cbcp1up_tmvran0t_1gjgrjb |
| dev_pre_aggregations | orders_main20210701_gmqrnxo2_igl1uczp_1gjgrjb |
| dev_pre_aggregations | orders_main20210101_j3kmnnak_msfmdqko_1gjgrjb |
| dev_pre_aggregations | orders_main20210201_vfcrnd42_5gpbrwfj_1gjgrjb |
| dev_pre_aggregations | orders_main20210801_rozcl2rd_t5nefwhv_1gjgrjb |
| dev_pre_aggregations | orders_main20211201_255cpz4u_e43gsbpt_1gjgrjb |
+----------------------+-----------------------------------------------+
24 rows in set (0.00 sec)
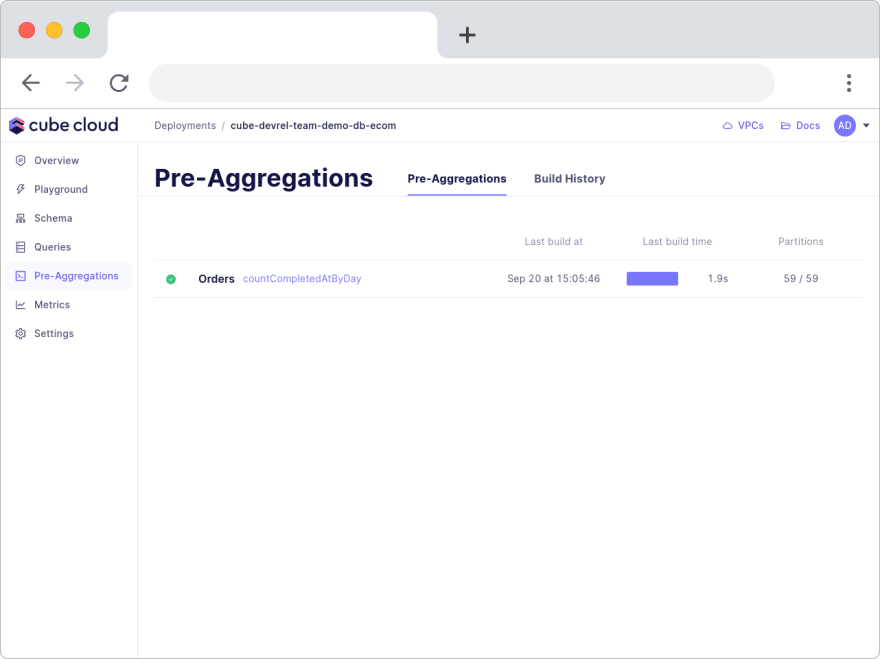
Cube Cloud goes a step further and simplifies the use of pre-aggregations significantly. If you select the pre-aggregations tab, you can view all your pre-aggregations in one place. This lets you view build history, partitions, build times, refresh times, indices, and much more.
How to Track Pre-Aggregation Build History Over Time
Having a detailed history of when pre-aggregation builds happen can help determine issues with stale data or even failing builds.
Self-hosted Cube. When a Cube Refresh Worker triggers a pre-aggregation build, and Cube Store runs the actual build, it will always log a message with a timestamp. But, these logs are ephemeral, and can often get lost in the stdout stream.
You can tail these logs and track build history over time. However, a much better option would be to use a custom logger like Winston or dedicated log monitoring agent like Fluentbit to forward these logs to a central location like Elasticsearch or any Log Management tool on the market.
Here's a guide from our docs showing how to forward logs to Loggly.
Cube Store simplifies this process by giving you a Build History tab to get a list of when every pre-aggregation build happened.
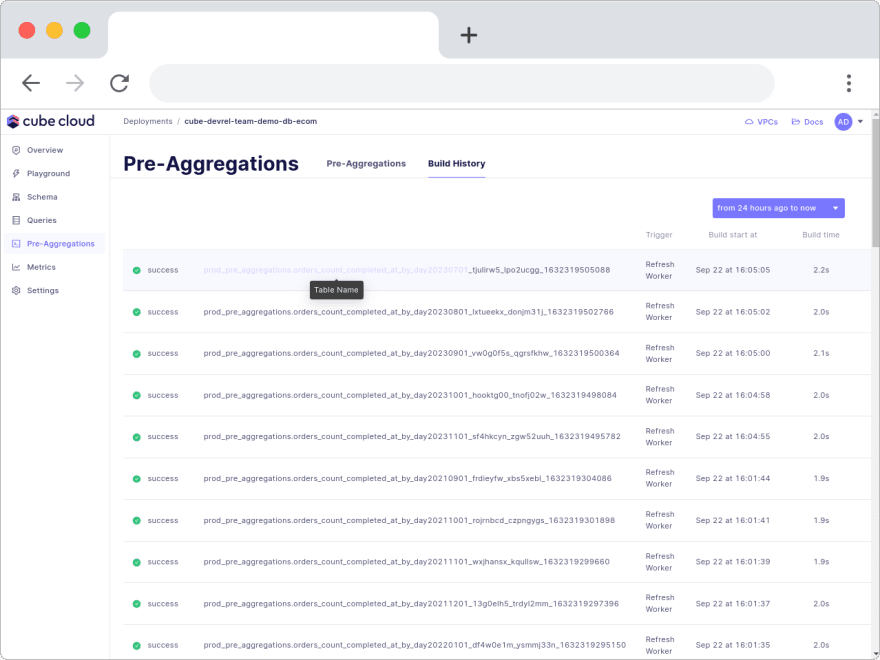
You can also see the anatomy of pre-aggregation names on hover.
How to Preview Pre-Aggregation Data
Even though you know pre-aggregation builds are successful, you still don't know if the data is valid. You need a way to preview the tables and their content in Cube Store to be absolutely sure.
Self-hosted Cube. You can preview the pre-aggregation tables the same way you looked into the state of pre-aggregations, by connecting to Cube Store with the MySQL CLI client, or any other client you prefer.
Use a SELECT command to see the content of a pre-aggregation table.
mysql> select * from dev_pre_aggregations.orders_main20231101_ayw2ads4_sntekhp5_1gjk5dh;
+----------------+--------------------------+---------------+
| orders__status | orders__created_at_day | orders__count |
+----------------+--------------------------+---------------+
| completed | 2023-11-02T00:00:00.000Z | 4 |
| completed | 2023-11-03T00:00:00.000Z | 2 |
| completed | 2023-11-04T00:00:00.000Z | 2 |
| processing | 2023-11-02T00:00:00.000Z | 4 |
| shipped | 2023-11-01T00:00:00.000Z | 1 |
| shipped | 2023-11-02T00:00:00.000Z | 1 |
| shipped | 2023-11-03T00:00:00.000Z | 4 |
| shipped | 2023-11-04T00:00:00.000Z | 1 |
| shipped | 2023-11-05T00:00:00.000Z | 1 |
+----------------+--------------------------+---------------+
9 rows in set (0.01 sec)
In the example above, the pre-aggregation table is stored in Cube Store. Alternatively, you can also store pre-aggregation data in cloud storage like AWS S3 or GCS. To view the data, access the S3 or GCS bucket directly through your cloud provider.
Sadly, previewing pre-aggregation tables in Cube Store is rarely done when using self-hosted Cube simply because there are a few hoops to jump through.
Cube Cloud makes it much easier with a dedicated Preview tab that's visible after drilling down to a single pre-aggregation.

Can you see the similarity to the sample drawing from the beginning of the article? You can clearly see how rows are grouped similarly to how a GROUP BY statement works in SQL.
How to Serve Requests Only from Pre-Aggregations
Serving requests solely from pre-aggregations is a great way to keep query latency low, but there is a significant overhead you need to be aware of in order to enable it.
You need to have a Cube cluster configured with a Cube refresh worker and a Cube Store cluster. This ensures pre-aggregations are always available for queries. It's not before then you can set the Cube API instance to only return data from pre-aggregations.
Self-hosted Cube. You use the CUBEJS_ROLLUP_ONLY environment variable and set it to true in the Cube API instance. This prevents serving data from the source database and building pre-aggregations on-demand.
Cube Cloud. You enable the Rollup Only Mode toggle in the settings.

Conclusion
Self-hosted Cube deployments are equipped with a decent set of tools and options to work with pre-aggregations. However, Cube Cloud provides a few additional tools as well as the managed infrastructure to make working with pre-aggregations hassle-free.
You can register for Cube Cloud right away!
I'd love to hear your feedback about Cube Cloud in the Cube Community Slack. Click here to join!
Until next time, stay curious, and have fun coding. Also, feel free to leave Cube a ⭐ on GitHub if you liked this article. ✌️
This content originally appeared on DEV Community and was authored by Adnan Rahić
Adnan Rahić | Sciencx (2021-12-20T12:19:14+00:00) Cube Cloud Deep Dive: Mastering Pre-Aggregations. Retrieved from https://www.scien.cx/2021/12/20/cube-cloud-deep-dive-mastering-pre-aggregations/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.