
This content originally appeared on DEV Community and was authored by Barbara
Why do we need distributed data technologies
If the dataset is larger than our memory, the program won't work.
We could fiddle around with data compression or read in the file in smaller chunks - io-chunking when using python pandas library.
But if we have to handle big amounts of data we need a different solution.
For most of the use cases the memory and the CPU are not the bottleneck, but the storage and the network is. Meaning getting the data out of the storage into the memory so that the CPU can process it. Loading data from a storage it is 300 times slower than reading it in the CPU. And we would have to move data all the time in and out of the memory to pass it to the CPU for the calculation. This is called trashing and is very slow.
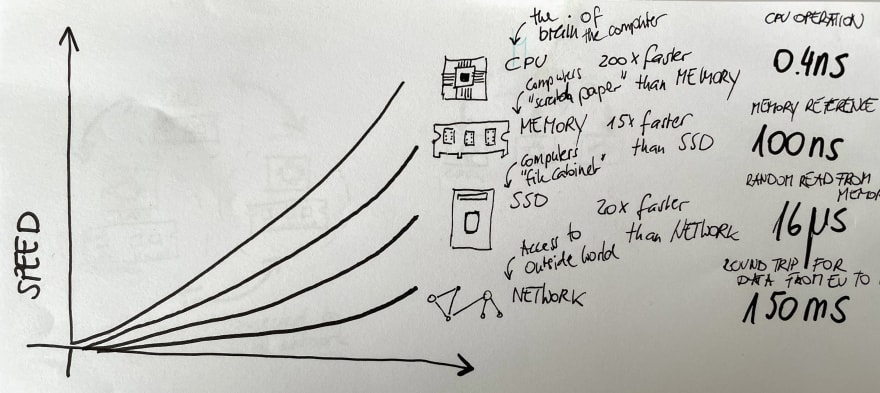
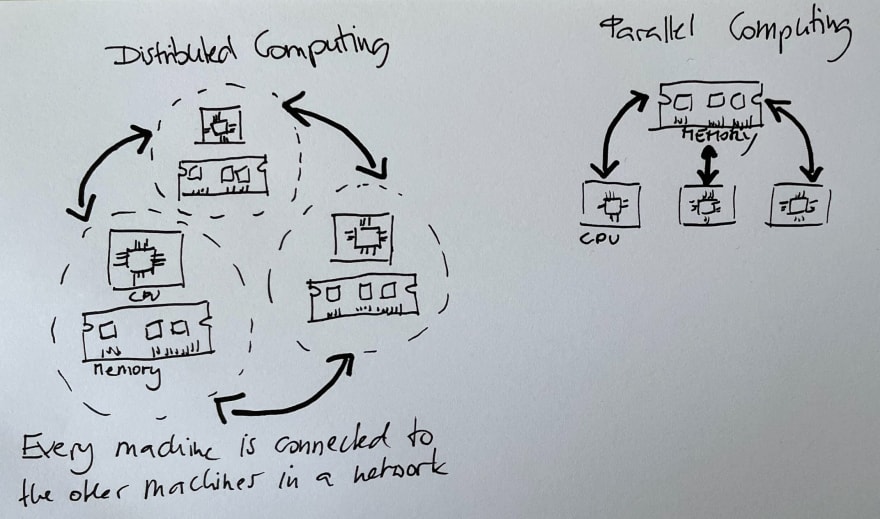
So we need a special system to distribute the data on several machines and process it in parallel.
Hadoop Framework
Hadoop is an ecosystem of tools for big data storage and data analysis. It is older than Spark and writes intermediate results to disk whereas Spark tires to keep data in memory whenever possible, so this is faster in many use cases.
Hadoop MapReduce - Data Processing
This is a system for processing and analysing large data sets in parallel. MapReduce is a programming technique for manipulation large data sets:
- Divide and distribute: In the first step a large dataset is divided and distributed across a cluster.
- Map: Each data is analysed and converted into a key-value pair.
- Shuffle: Those key-value pairs are shuffled across the cluster so that all keys are on the same machine.
- Reduce: All of those data points with the same key are brought into the same network node for further analysis
Hadoop YARN - Resource Manager
a resource manager, that schedules jobs across a cluster. The manager keeps track of what computer resources are available and then assigns those resources to specific tasks.
HDFS - Hadoop Distributed File System - Data Storage
This is a big data storage data system that splits data into chunks and stores the chunks across a cluster of computers.
Spark
Is a big data framework and currently one of the most popular tools for big data analytics.
It contains libraries for data analysis, machine learning, graph analysis and streaming live data. In general Spark is faster than Hadoop, as it does not write intermediate results to disk. It is not a data storage system.
We can use Spark on top of HDFS or read data from other sources like Amazon S3.
It is the designed for Data Analytics, Machine Learning, Streaming and Graph Analytics.
Limitations of Spark
- Streaming: Sparks Streamings's latency is at least 500ms, since it operates on micro-batches of records, instead of processing one record at a time. Native streaming tools like Storm, Apex or Flink might be better for low-latency applications.
- Machine Learning: Currently it only supports algorithms that scale linearly with the input data size and deep learning is not available. If this is a use case, we can use Tensorflow for deep learning.
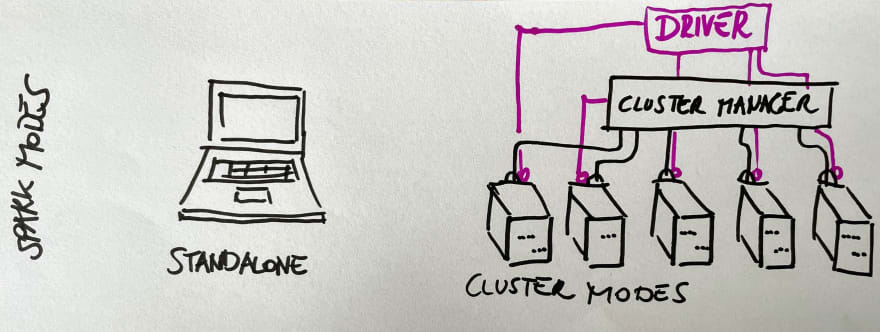
Spark Modes
- Local Mode: useful to learn the syntax and prototype a project
- Cluster Modes: We can use a cluster in Standalone version or via a clustermanager either YARN or Mesos.
Programming
It is written in Scala and provides APIs in Java, R and Python, called Pyspark. Under the hood Pyspark uses py4j to make calls to the JVM - Java Virtual Machine. The best way to run Spark on your computer is in a Docker container. Check out this tutorial to see how.
Pure functions
As we work with a distributed system we want to avoid side effects. As we don't want to trigger effects on variables outside a function scope. This functions are called pure functions.
DAG - Directed Acyclic Graph
Every Spark function makes a copy of its input data, because it does not want to mutate the input data. This is called immutable and makes sense when you have a single function. As we often have a function that is composed of a lot of subfunctions, we would run out of memory very fast. Thats why Spark uses lazy evaluation.
First step by step directions of what functions and data are needed. You can compare those directions to the steps of a recipe. In Spark this is called DAG. Spark always waits as long as possible to see if it can streamline the work. This is called Lazy Evaluation

If Spark would not do this, the system would end up doing something called trashing. As if you had to go for every single ingredient you need for your recipe to the supermarket instead of using a shopping list and pick up everything at one time at the supermarket.
Run Spark
Spark Context: Main entry point for Spark functionality. This connects the cluster with the application.
We can create objects within a SparkContext to create lower level of abstractions.
We need to create a Sparksession to read the dataframes.
from pyspark import SparkContext, SparkConf
from pyspark import SparkSession
configure = SparkConf().setAppName("yourAppName").setMaster("IP Adress")
sc = SparkContext(conf=configure)
spark = SparkSession.builder.appName('yourAppName').getOrCreate()
// takes in the log object and distributes the object across the machines of the cluster
distributed_data = sc.parallelize(your_data)
// will return the original dataset. As Spark is uses lazy evaluation we have to call the collect() method to get the results from all of the clusters and "collect" them into a single list on the master node.
distributed_data.collect()
RDDs - Resilient Distributed Data Set
They are fault-tolerant datasets distributed across a cluster. This is how Spark stores the data. In the first version of Spark we had to work directly with RDDs.
We can still use RDDs as part of our Spark code as we might need it in some cases. When working with RDDs we have to use imperative programming, this means we have to be very detailed with the programming instructions, therefore using Datasets API available since Spark Version 2.0 is much easier.
SPARK SQL and Dataframe
Spark dataframe offers methods that are quite similar to pandas dataframe
| General Functions | |
|---|---|
select() |
returns a new DataFrame with the selected clolumns |
filter() |
filters rows using the given condition |
where() |
alias for filter
|
groupBy() |
groups the DataFrame using the specified columns, so we can run aggregation on them |
sort() |
returns a new DataFrame sorted by the specified column(s). By default the second parameter 'ascending' is True |
dropDuplicates() |
returns a new DataFrame with unique rows based on all or just a subset of columns |
withColumn() |
return as a new DataFrame by adding a column or replacing the existing column that has the same name. |
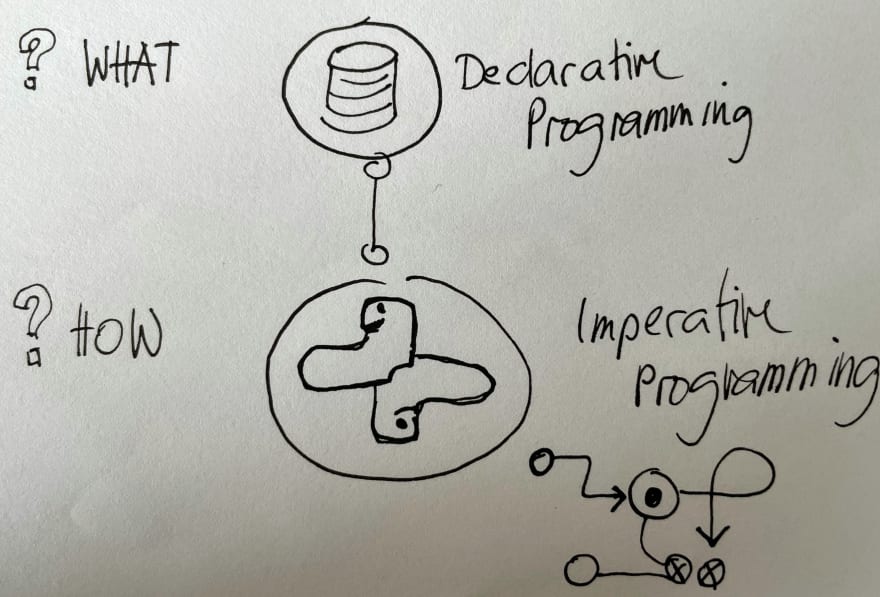
When using Spark SQL we can query data with a declarative approach. Declarative programming is more concerned about the what than about the how. In most cases this systems are an abstraction layer over an imperative system, that takes care of the how.
As a lot of people can read and write SQL. Spark will automise the SQL Code out of the box (Spark magic alarm) and this will speed up the process of manipulating and retrieving data.
ACHTUNG: Unlike a database table, the view in Spark is temporary
| Aggregate Functions | |
|---|---|
like: count(), countDistinct(), avg(), max(),min()
|
You can find out all available aggregate functions in the pyspark.sql.functions module. Make sure not to confuse those methods with the built-in methods of the Python Standard Library. |
| UDF - User Defined Functions | |
|---|---|
spark.udf.register("yourFunctionName", yourFunctionCode) |
In Spark SQL we can define our own functions with the udf module. But you can also use Lambda functions or build-in Python functions if needed like distributed_data_log.map(lambda lower_data: data.lower()).collect()
|
| Window Functions |
|---|
Window functions are a way of combining the values of ranges of rows in a DataFrame. When defining the window we can choose how to sort and group (with the partitionBy method) the rows and how wide of a window we'd like to use (described by rangeBetween or rowsBetween) |
Coding examples here.
This content originally appeared on DEV Community and was authored by Barbara
Barbara | Sciencx (2021-12-22T16:24:43+00:00) Spark for beginners – and you. Retrieved from https://www.scien.cx/2021/12/22/spark-for-beginners-and-you/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.