
This content originally appeared on DEV Community and was authored by Nitzan Hen
Perhaps the greatest lesson I've learned from creating Agrippa so far is just how important tests are. Of course I knew they were important before - everybody does - but it's so easy to just push it aside and focus on more exciting code, or write some perfunctory tests that don't really, well, test anything. Eventually, however, slacking off on testing comes back to bite you; for me, luckily, it did when things were only getting started, but the point was clear - writing good tests is a top priority.
A challenging tool to test
For Agrippa, however, writing good tests is far from trivial - it's a CLI for generating React components based on a project's environment (dependencies, existence of config files, etc.), as well as an optional .agripparc.json config. In other words, a lot of its work is reading & parsing command-line arguments, looking up and reading certain files, and its end result is writing additional files. All of those are non-pure side effects, which are difficult to cover properly with just unit tests.
Additionally, because Agrippa's defaults greatly depend on the project's environment, it's easy for tests to return false results because of the presence of an unrelated file or dependency.
This is best explained with an example: when run, Agrippa auto-detects whether a project uses Typescript or not, by the existence of a tsconfig.json file in it. However, Agrippa itself is written in Typescript, which means there's a tsconfig.json file at its root. As a result, whenever running Agrippa in any sub directory of the project root, it generates Typescript (.ts/.tsx) files unless explicitly told otherwise. And, if tests were stored, for example, in a test folder in the project repository - they would all be tampered with (at least, those where files are looked up). A similar problem is cause by the existence Agrippa's own package.json.
With this in mind, when planning the implementation of testing I decided on these two key principles:
- There need to be good integration tests which test the process - including all of its non pure effects (parsing CLI options, reading files, writing files) - from start to finish, under different conditions and in different environments.
- The integration tests have to be executed in a space as isolated as possible, due to the process being greatly dependent on the environment it's run in.
The second point is where you can see the need for Docker - initially, I tried implementing the tests in a temporary directory created by Node and running the tests there, but this turned out to be too much work to build and maintain, and the created directory could still theoretically be non-pure.
Docker, on the other hand, is all about spinning up isolated environments with ease - we have complete control over the OS, the file structure, the present files, and we're more explicit about it all.
In our case, then, running the tests inside a docker container would get us the isolation we need. So that's what we went with:
The solution
# Solution file structure (simplified)
test/integration/
├─ case1/
│ ├─ solution/
│ │ ├─ ComponentOne.tsx
│ │ ├─ component-one.css
│ ├─ testinfo.json
├─ case2/
│ ├─ solution/
│ │ ├─ ComponentTwo.tsx
│ │ ├─ component-two.css
│ ├─ testinfo.json
├─ case3/
│ ├─ ...
├─ integration.test.ts
├─ jest.integration.config.js
Dockerfile.integration
The end solution works like so:
Integration test cases are stored under test/integration, in the Agrippa repository. Each case contains a testinfo.json file, which declares some general info about the test - a name, a description and the command to be run - and a directory solution, with the directories and files that are meant to be created by the command. The test/integration directory also contains a Jest config, and integration.test.ts, which contains the test logic itself.
When the test:integration Node script is run, it builds a Docker image from Dockerfile.integration, located at the project root. This is a two-stage build: the first stage copies the project source, builds it and packs it into a tarball, and the second copies & installs that tarball, then copies the test/integration directory. After building the image, a container is created from it, which runs the tests inside.
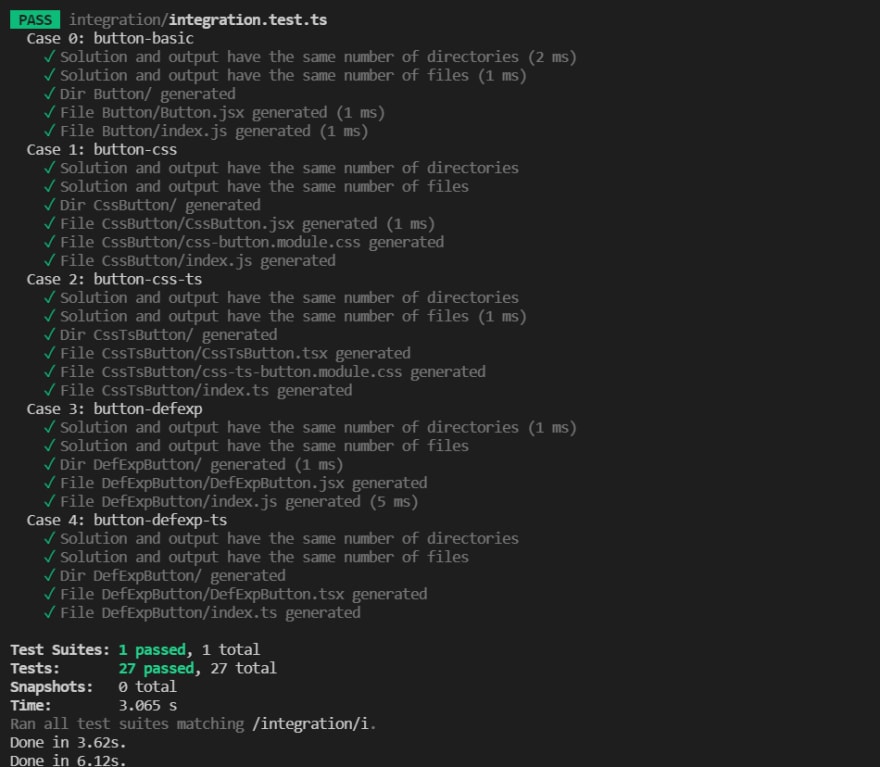
The testing logic is non-trivial, too. It scans the test/integration directory for cases, and creates a test suite for each (using describe.each()). The test suite for each case starts by running the case - scanning the solution directory, running the agrippa command, then scanning the output directory - then compares the two results. A case is considered successful if (and only if) both solution and output have exactly the same directories, the same files, and the content in each file is the same.
Further improvements
So far, the solution has been working well. The script takes longer to run than a standard testing script, because of the time it takes for Docker to set up (about 60-70 seconds if Docker needs to build the image, a few seconds otherwise). However, it's simpler, more robust, and safer than implementing a custom solution (with temporary directories, for example), and adding new test cases is easy and boilerplate-free.
The output (shortened for display purposes) looks like this:
One problem with the implementation, unrelated to Docker, is about using Jest as the testing framework. As it turns out, Jest is limited when it comes to asynchronous testing, and combining a dynamic number of test suites (one for each case), a dynamic number of tests in each, as well as asynchronous setup before all tests (scanning test/integration for cases) and before each test (running the case) simply doesn't work out.
When I get to it, I hope to switch to a different testing framework - Mocha looks good for this particular scenario, and seems fun to get into.
Conclusion
Since Agrippa is greatly sensitive to the environment it's run in,
we needed complete isolation of our testing environment for the tests to truly be accurate. Docker provides exactly that - and therefore we turned to it. The solution using it took some time to properly implement - but it turned out well.
What do you think? do you have an improvement to suggest, or something to add? I'd love to hear from you!
Thanks for your time.
This content originally appeared on DEV Community and was authored by Nitzan Hen
Nitzan Hen | Sciencx (2021-12-29T21:11:09+00:00) Why we used Docker for testing. Retrieved from https://www.scien.cx/2021/12/29/why-we-used-docker-for-testing/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.