
This content originally appeared on DEV Community and was authored by Adriano Sastre Vieira
Hi, I'm Adriano Sastre Vieira, software developer at Inatel Competence Center.
In this article I'll talk about AWS Serverless, also called managed services (because you don't have to manage a server in order to deploy these services), with more focus on DynamoDB and the Single Table Design concept.
Not recommended, but click here if you want to skip the theory and go strait to the hands on.
Serverless!
DynamoDB is a AWS managed database service. When we talk about AWS managed service, we're also talking about Serverless.
Serverless is the practice of using managed services with event driven compute functions to avoid or minimize infrastructure management, configuration, operations, and idle capacity.
But it's not just about computing, there is a wide range of things an application architecture may need, e.g. Compute, Storage, Data, Monitoring, Queue, Notification ...
So, it is correct to say that DynamoDB is a serverless database, or more specifically, an AWS managed database service.
Serverless is a big paradigm shift, potentially even more impactful than the move to the Cloud before it!
Check the articles below if you want to go deeper into Serverless:
Microservices
Yet on the related concepts, we have the Microservices.
The Microservice architectural style is an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API.
These services are built around business capabilities and independently deployable by fully automated deployment machinery.
Many people are using Serverless applications to build a Microservice architecture!
I believe this is the number one article for those who wants to go deeper on Microservices - from Martin Fowler.
Serverless and the AWS Cloud
Ok, some important things about AWS before we cut to the chase.
AWS - Fundamentals (The 5 Pillars, new "mental models")
When starting working with AWS, it's normal to feel quite lost, as it has about 200 services, many of them overlapping others on their responsibilities, doing similar stuff, and the AWS extensive documentation does not seem to help beginners, it's difficult to FOCUS and use what is best for each case.
In addition, when we change from a monolithic architecture to micro services, it's a big shift, it's like changing from classical physics to quantum physics!
So, a very good start point is to understand the AWS Fundamentals, which talks about the 5 pillars that requires new mental models, and summarizes the AWS services and concepts for each one:
- Operational excellence: thinking about operations as automation (CloudFormation, CDK ...)
- Security: zero trust, the principle of least privilege (IAM, data encryption ...)
- Reliability: using fault isolation zones to limit blast radius (regions, quotas, throttling ...)
- Performance Efficiency: think of your services as cattle, not pets. (horizontal vs vertical scaling, auto scaling ...)
- Cost Optimization: OpEx (pay-as-you-go) instead of CapEx (one-time purchase)
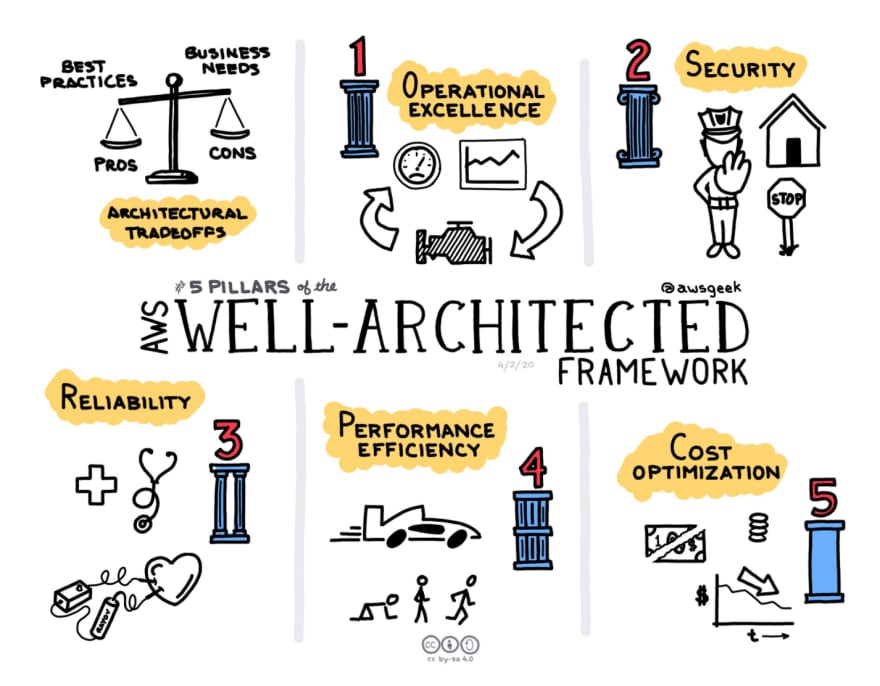
So if you didn't yet, now it's a good opportunity to check the AWS Fundamentals!
The AWS Managed Services
When we talk about AWS managed services, these are the main ones:

There are many pros on using managed services:
- Cost reduction: the initial cost tend to zero (free tier for most of them, after that pay as you use)
- Security: e.g. no need to install security patches on servers
- NoOps: e.g. no servers / storage to manage or to scale, no need for a infrastructure team
- More scalable
- High performance
- Greener: if you don't need, you're not using the server resources
- Productivity: developers focus on delivering business value
Some cool links to learn more about Serverless on AWS:
- Serverless on AWS
- AWS Deep Dive Serverless
- Serverless Land
- AWS Free Tier - in order to check if a AWS service is free or how much it costs
Minimum Stack: API Gateway + Lambda + DynamoDB
While this article focus is the DynamoDB, in order to talk about it in a more practical way, it's important to think in a minimum sample architecture where it fits.
The classical AWS example is:
- An API (e.g. some CRUD) implemented via API Gateway;
- This API is accessed by a client (e.g, the Postman, or a mobile/web app);
- Lambda function(s) in order to manage this API and interface with the database
- And the DynamoDB table in order to store data.

I'll briefly talk about API Gateway and Lambda before going to DynamoDB. Pay attention to the italic words, they are related to the Serverless concepts.
API Gateway
https://aws.amazon.com/api-gateway
Fully managed service that makes it easy for developers to create, publish, maintain, monitor, and secure APIs at any scale.
Handles all the tasks involved in accepting and processing up to hundreds of thousands of concurrent API calls, including traffic management, CORS support, authorization and access control, throttling, monitoring, and API version management.
Lambda
AWS Lambda is an event-driven, serverless computing platform provided by Amazon as a part of Amazon Web Services.
Runs code in response to events and automatically manages the computing resources required by that code.
Triggered by events (e.g. HTTP Calls via API Gateway, S3 new objects on a bucket, new SQS in a queue, new item in a DynamoDB table ...)
DynamoDB
https://aws.amazon.com/dynamodb/
Now we're talking. DynamoDB definitions and main characteristics from AWS:
Fast and flexible NoSQL database service for any scale. Key-value and document database that delivers single-digit millisecond performance at any scale.
Fully managed, multi-region, multi-active, durable database with built-in security, backup and restore, and in-memory caching for internet-scale applications.
Free-tier forever applied, up to 25GB storage, 25 read/write provisioned units (about 200M requests/month). After that: cost by storage and requests.
For those who are curious about its roots, read "The Dynamo Paper". Summary: it was created by Amazon (2004-2007), public released by AWS in 2012.
DynamoDB as part of a Serverless Architecture
When we first saw these propaganda, it seems all good news alright?
But wait, it is not that simple.
First, adopting DynamoDB in place of a relational database is just part of moving to a Serverless Architecture, although a very important one.
The idea of using NoSQL for any and all core business requirements is quite new, and this is because the whole system now works at a scale and event-driven nature before inexistent.
Bad designed DynamoDB tables has often the major impact on a serverless architectured system, both on performance and costs!
Don't get me wrong, DynamoDB is really great! There are lots of benefits on using it, as easily integrating it with other managed services like lambdas and very low initial cost.
And yes, it is possible to use it correctly on the majority of the systems (remember: Amazon uses it on its shopping cart, so why can't we?); but in summary: DynamoDB is complex, doing it well even more so!
DynamoDB NoSQL design vs RDBMS
NoSQL design requires a different mindset than RDBMS design.
With RDBMS, you can go ahead and create a normalized data model without thinking about access patterns.
By contrast, you shouldn't start designing the schema for DynamoDB until you know the questions that need to be answered. Understanding the business problems and the application use cases up front is essential!.
To clarify, it follows some common access patterns examples:
- Get a user's profile data
- List the user's orders
- Get an order and its items
- List the user's orders by status
Of course, on a real system there are lots more.
DynamoDB design considerations
This AWS documentation "NoSQL Design" goes deeper on the concepts I've summarized in this image:

After you identify specific query requirements, you can organize data according to general principles that govern performance:
Keep related data together. Keeping related data in close proximity has a major impact on cost and performance. Instead of distributing related data items across multiple tables, you should keep related items in your NoSQL system as close together as possible.
Use sort order. Related items can be grouped together and queried efficiently if their key design causes them to sort together. This is an important NoSQL design strategy.
Distribute queries. It is also important that a high volume of queries not be focused on one part of the database, where they can exceed I/O capacity. Instead, you should design data keys to distribute traffic evenly across partitions as much as possible, avoiding "hot spots".
Using indexes. By creating specific global secondary indexes, you can enable different queries than your main table can support, and that are still fast and relatively inexpensive.
These general principles translate into some common design patterns that you can use to model data efficiently in DynamoDB.
This presentation Advanced Design Patterns for Amazon DynamoDB is great for better understanding it.
DynamoDB - table capacity
Per DynamoDB table, it is possible to configure the capacity as:
OnDemand: automatic and "infinite" scaling
Provisioned: possible to define independent read and write unit capacities; also possible to configure auto-scaling rules, e.g. min/max scaling
When correctly configured, a provisioned capacity costs less than an on demand capacity.
It is possible to change between OnDemand and Provisioned once a day! This is very useful for scenarios where on a specific time range, it is not possible to predict the scaling (e.g. e-commerce system on Black Fridays).
DynamoDB pk, sk, attributes
As key-value and document database, each DynamoDB table item may have different attributes!
But it is mandatory to define the primary key. In a nutshell:
Primary Key:
PK = Partition Key (aka hash key) (mandatory)
SK = Sort Key (aka range key) (optional)
Attributes: Binary, Number or String
Can be grouped in a JSON-like structure
This image exemplifies the DynamoDB structure:
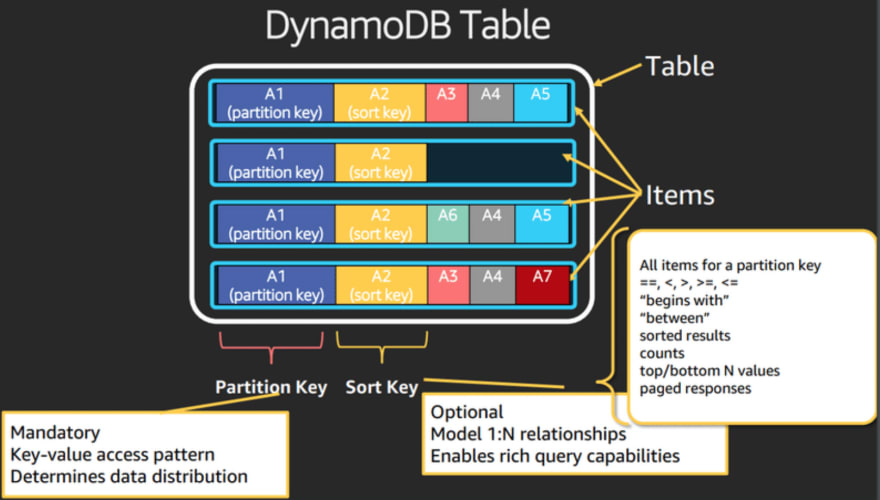
And this shows an example of a populated DynamoDB table:

DynamoDB - How to query data
Querying data is normally the most important consideration when designing DynamoDB schema, as usually there are much more reading than writing operations.
There are basically 3 ways of querying DynamoDB data:
- Get = one specific item, by PK or PK/SK
- Query = several items, by PK/SK or indexed attributes
- Scan = several items, by any table attribute
This is very important: the get and query operations are much faster comparing to the scan operation, which has a poor performance and a high cost.
So it is crucial to model a DynamoDB table in a way that it is possible to query all necessary data, for every access pattern, using get or query operations, and avoiding scan operations.
DynamoDB indexes
We may define 2 kinds of indexes on DynamoDB:
- GSI = Global Secondary Index = more common, applied to all table items
- LSI = Local Secondary Index = applied to a particular table partition (pk)
It follows the main pros and cons of using DynamoDB indexes:
- Pros: performance: with an index, it is possible to query (instead of scan) on attributes other than the PK/SK
- Cons: behind the scenes, each GSI duplicates the table storage, along with its storage costs
There is also a limit of 20 GSI per table.
The following image provides more details on DynamoDB indexes:

DynamoDB TTL (time to live)
Optionally, a time to live attribute can be defined on DynamoDB tables, and it is very useful on scenarios where items have to be deleted after certain time is reached.
Another interesting behavior, each table item may have a different time to live value, or no TTL value at all!
DynamoDB - Single Table Design
Different from relational databases where we have to normalize the data, it is an AWS recommendation to maintain as few tables as possible when modeling with DynamoDB, as stated on NoSQL Design for DynamoDB documentation.
When we normalize data, we make the data access very flexible, but it reduces the scalability, due to the high cost of the joins operations.
But DynamoDB was built for enormous, high-velocity use cases, such as the Amazon.com shopping cart. Rather than working to make joins scale better, DynamoDB sidesteps the problem by removing the ability to use joins at all!
Again, DynamoDB was build with web scale in mind. It can grow almost infinitely without degrading performance. In order to achieve this DynamoDB removed joins completely.
You have to model the data in such a way that you can read the data, ideally, in a single request by denormalizing the data.
The main reason for using a DynamoDB single table is to retrieve multiple, heterogenous item types using a single request.
The following links are great to understand more about the single table design concepts:
- The What, Why, and When of Single-Table Design with DynamoDB
- Comparing multi and single table approaches to designing a DynamoDB data model
- Microservices with DynamoDB: should you use a single table or use one table per microservice?
Single Table Desing - Pros and Cons
Summary of the advantages and disadvantages of applying the single table design:
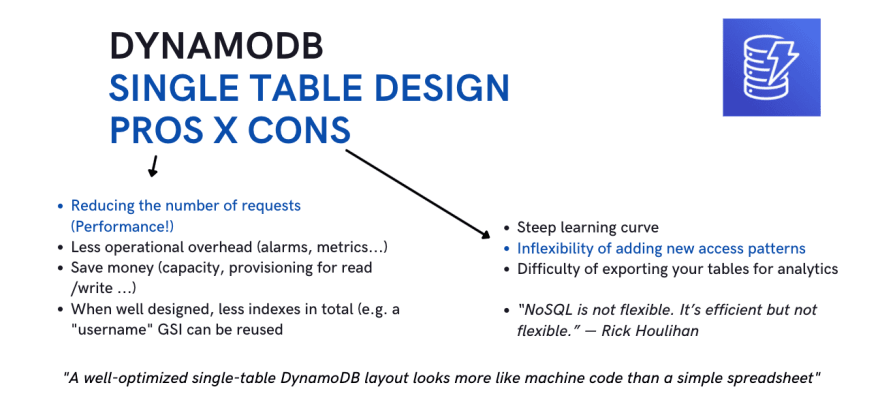
DynamoDB - When and how (not) to use
I summarize in the following images when and how to use and not to use DynamoDB:

More about the true microservice here. In a nutshell, it favors using a DynamoDB single table per microservice, but not per the whole system.

Indeed the Faux SQL is a common mistake when starting using a NoSQL database as DynamoDB or MongoDB. More about the Faux SQL here.
DynamoDB - Hands on!
From Relational to NoSQL
In order to get the hands dirty on the DynamoDB single table design, let's imagine a simple system where we have users and orders.
RDBMS:
In the relational world we would have the following model:
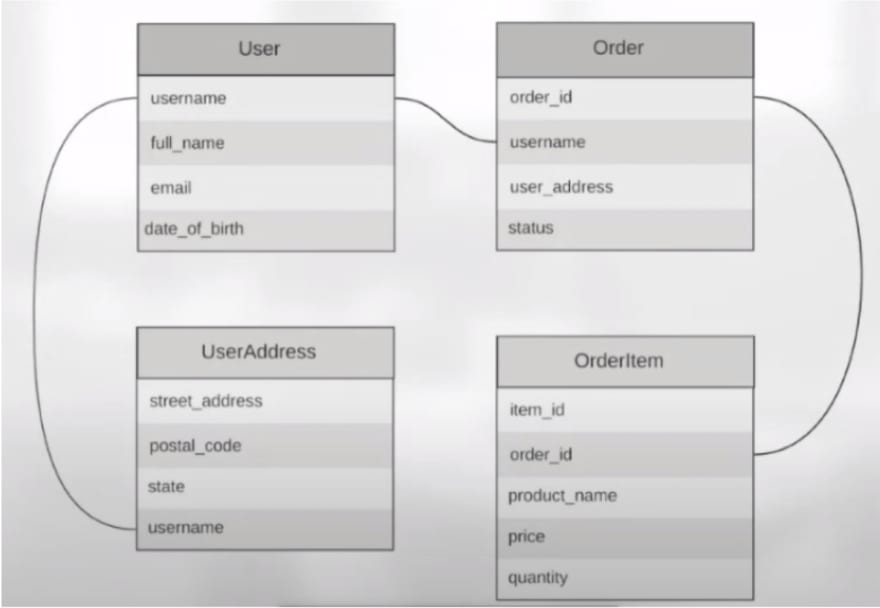
DynamoDB
When we model it with DynamoDB, the first and more important question is: What are the access patterns for my system?
In other words, how the system will query the data in the database?
In this case, we can think about the following access patterns:
- List all users
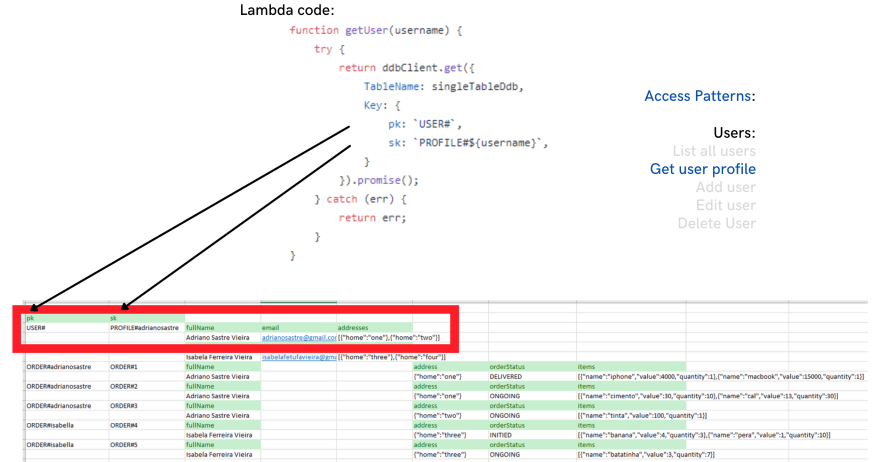
- Get user profile
- Add user
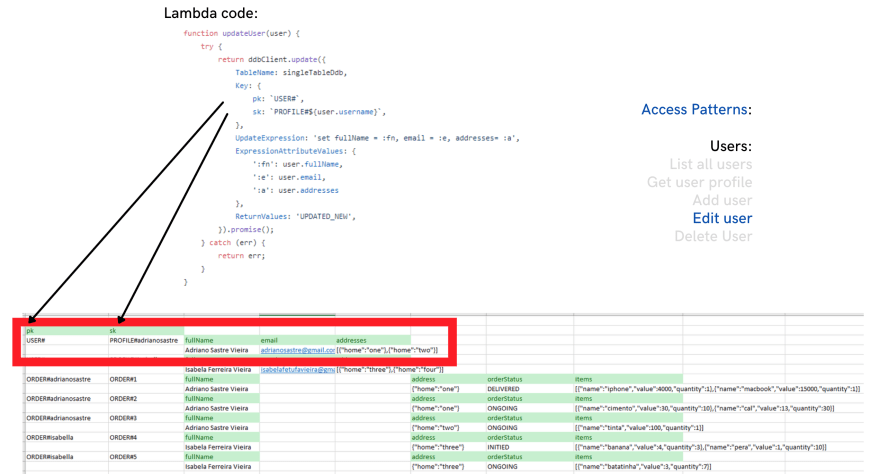
- Edit user
- Delete User
- List all users orders
- List users orders by status
- List users order items
- Add user order
- Edit user order
- Delete user order
With that in mind, we have the following schema for a DynamoDB single table on this scenario:

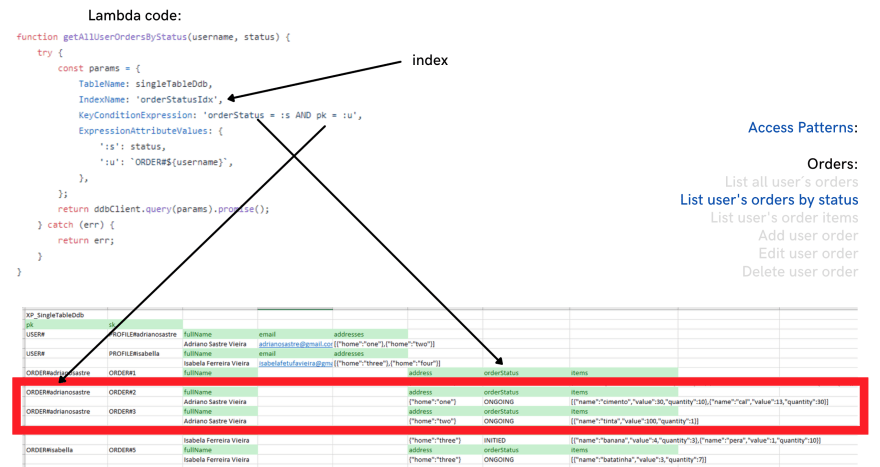
Notice that we have in the same table, different items for users and orders information. They even have different attributes. But the important is that they have different patterns in their pk and sk values, and these patterns are used in order to query data for all access patterns.
Again, there are more detailed articles explaining how to go from a relational to a NoSQL database, if you wanna go further:
- From relational DB to single DynamoDB table: a step-by-step exploration
- How to switch from RDBMS to DynamoDB in 20 easy steps
IaC - the Infrastructure as Code
Before configuring the AWS services and coding the business logic, let's do it right!
Having the infrastructure as code is essential in order to code versioning (ex: git) all the AWS services configuration, instead of making it through the AWS Console (and totally losing control when something goes wrong!).
IaC is also critical to implement CI/CD pipelines.
CloudFormation
https://aws.amazon.com/cloudformation/
When it comes to the AWS IaC, the most basic level is the CloudFormation. Basically, it consists on yaml or json templates that describes your resources and its dependencies so you can launch and configure them together as a stack.
In other words, it is an automated process for resources creation. But it is still quite hard and error-prone to program IaC with CloudFormation.
CDK - The Cloud Development Kit
https://docs.aws.amazon.com/cdk/api/v2/
Released on 2019, we now have the AWS CDK: the official AWS open source software development framework to define your cloud application resources using familiar programming languages. And now in the end of 2021, we have CDK v2 released.
With CDK, you can model the infrastructure resources in high-level languages like Java, Typescript, Python or C#.
Behind the scenes, the CDK will generate the CloudFormation templates and deploy them as AWS CloudFormation Stacks.
It is much safe, easy and fun to program AWS IaC code with CDK that with CloudFormation!! Also, when compared to other IaC frameworks (e.g. serverless, terraform, etc), it has the following advantages:
- Implemented and maintained by AWS
- Easy integration with AWS services
- More secure (e.g. roles automatically generated for services, from read/write permissions)
Step by step
Let's get the hands dirty!
Prerequisites
If not yet, create / install / configure the following:
1 - Create an AWS Account if you don't have yet.
2 - After logged into the AWS Console, add an IAM user with "Access type: Programatic access" and for the sake of this example, add the "Administrator Access" policy to this user. Copy its "Access key ID" and "Secret access key", we'll use them soon.
3 - Download and install VS Code: https://code.visualstudio.com/
4 - Install Node and NPM: https://nodejs.org/en/download/
After installing, check their version. At the moment of this writing I have node v16.13.1 and npm 8.3.0
node -v
npm -v
5 - Download and install AWS cli: https://aws.amazon.com/cli/
After installing, check its version and configure it to your AWS account IAM user created on step 2:
aws --version
aws configure
6 - Install AWS CDK:
Install CDK via NPM and check its version. At the moment I have 2.3.0 (build beaa5b2)
npm install -g aws-cdk
cdk --version
7 - Download and install Docker: https://www.docker.com/products/docker-desktop
Docker is only used in order to deploy the CDK project into AWS, we do not have containerized AWS services in this example.
8 - Download and install Postman: https://www.postman.com/ (used in order to test the APIs)
Architecture

As per the above architecture, this project consists on:
- API Gateway, with the /users and /products RESTful resources
- Lambdas: functions for users and orders, they handle the APIs and DynamoDB data
- DynamoDB: one single table to store users and orders data
Open project on VS Code
This project was implemented with CDK v2 with Typescript, and is public available on github:
github.com/adrianosastre/DynamoDB-CDK-Hands-On
Please clone and open it on VS Code, and look at these important chunks of code:
1 - Resources application stack
The lib/resources-application-stack.ts file is IaC code, it creates the DynamoDB table and the users and orders Lambdas.
Important things to note:
- The "grantReadWrite" method that manages the lambda permissions on the DynamoDB table.
- The lambdas were implemented as class readonly public attributes.
2 - API stack
The lib/api-gateway-stack.ts file, also an IaC code, creates the API Gateway with our users and orders resources.
Note that it uses the lambdas exposed on the lib/resources-application-stack.ts file in order to create the resources integration with the lambdas.
3 - The CDK main file
The file under the bin directory, in this case the bin/dynamoDB-CDK-Hands-On-Project.ts file, is the main file in the CDK structure.
It instantiates the stacks and care about its dependencies.
4 - Lambdas code
The users.js and orders.js files under lambda directory are not IaC code.
Instead, they are the "core" of the system, containing the business logic code behind the lambdas, and are executed every time the lambdas are triggered.
Deploying on AWS
Note: AWS cli must be correctly configured as explained in the Prerequisites session.
Only once, it is necessary to execute the following command so the CDK will deploy into your AWS account the required resources for it to deploy projects:
cdk bootstrap
After that, you can deploy the project to your AWS account via the following command:
cdk deploy --all
Every time you change the IaC or lambda code, you can use this command to redeploy, and it does not impact the services usage!
After the project is deployed, you can check in your AWS account the following resources:
- CloudFormation: the stacks with the resources programmed via CDK were deployed here:
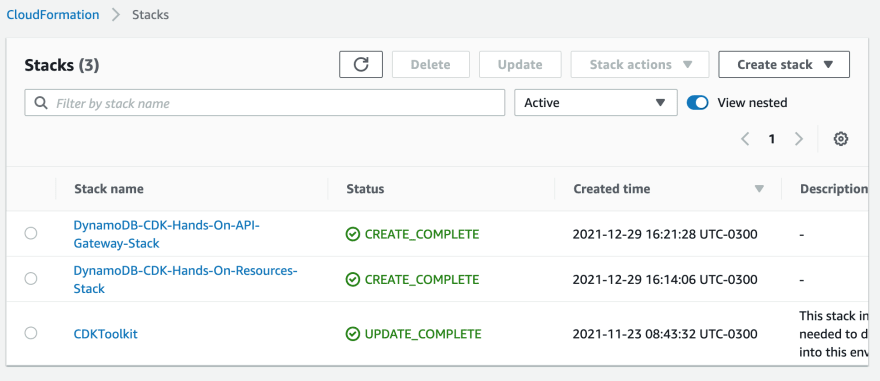
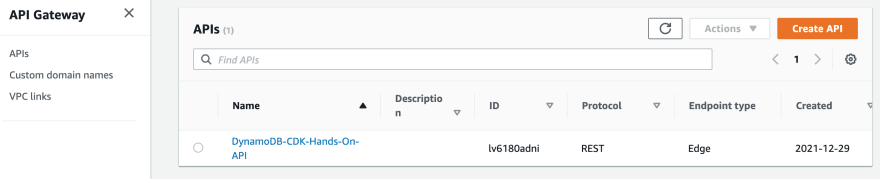
- API Gateway: the DynamoDB-CDK-Hands-On-API API is deployed and public available:
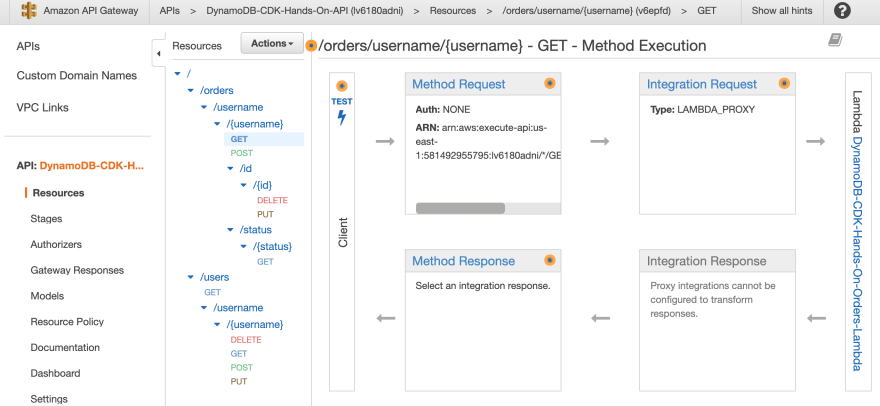
And the API expanded showing its resources:
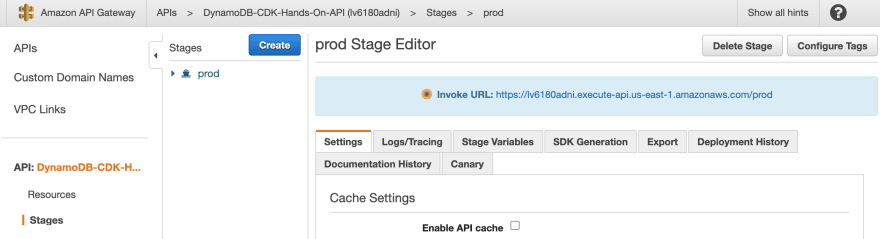
In addition, the Stages > prod > Invoke URL shows the base URL for this API, so you can use it, for example, with Postman:
- Lambda: the functions to handle users and orders are deployed:

- DynamoDB: The DynamoDB-CDK-Hands-On-Single-Table table was also created and deployed:
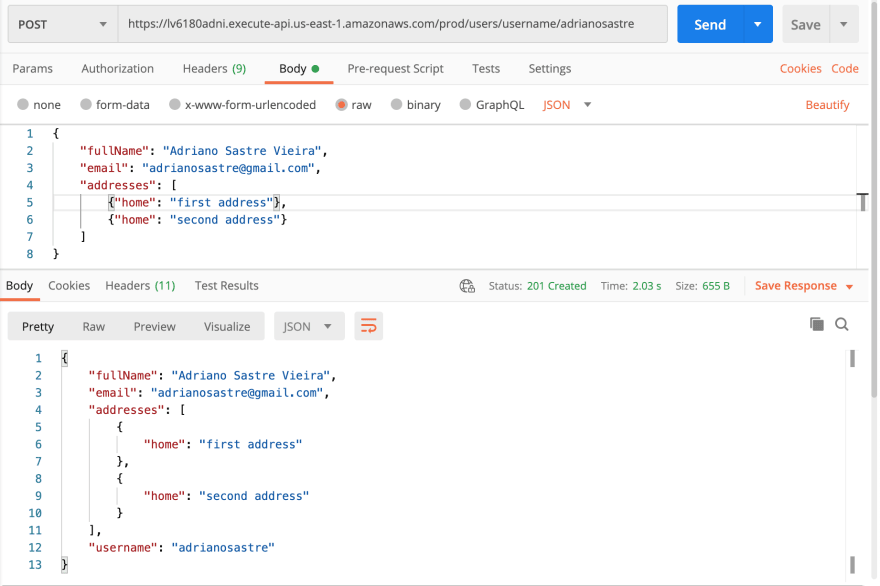
Test with Postman
After deployed, it is possible to test all the project URLs with Postman. Take the following images as references and use Postman with your API base URL.
- Adding users:

- Listing all users:


- Getting a user profile data:

- Editing a user:

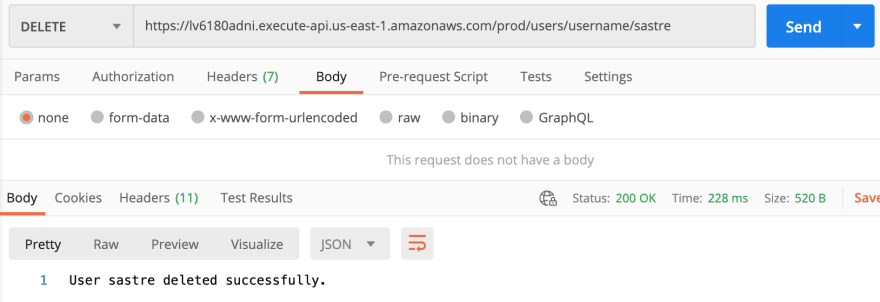
- Deleting a user:

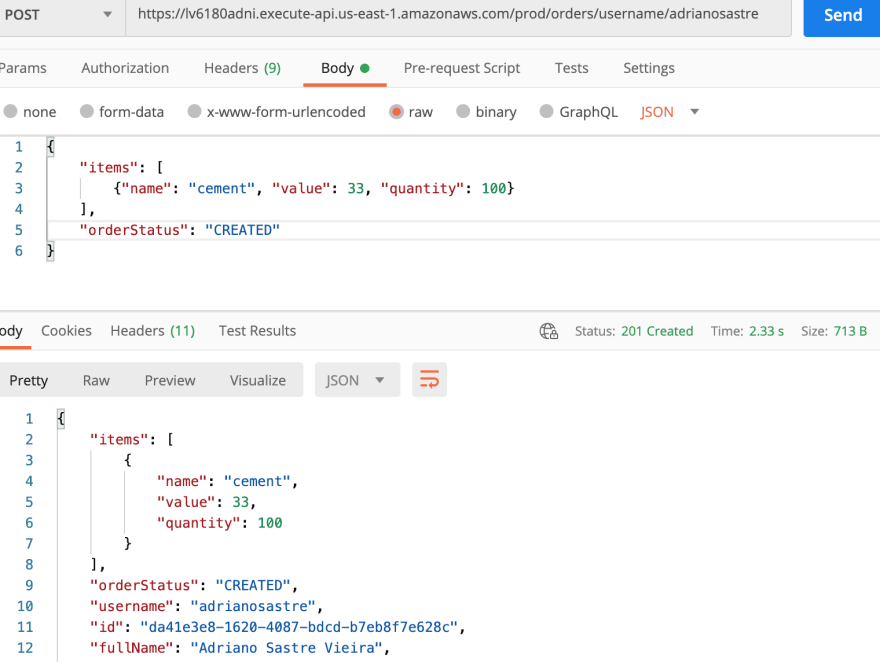
- Adding an order for a user:
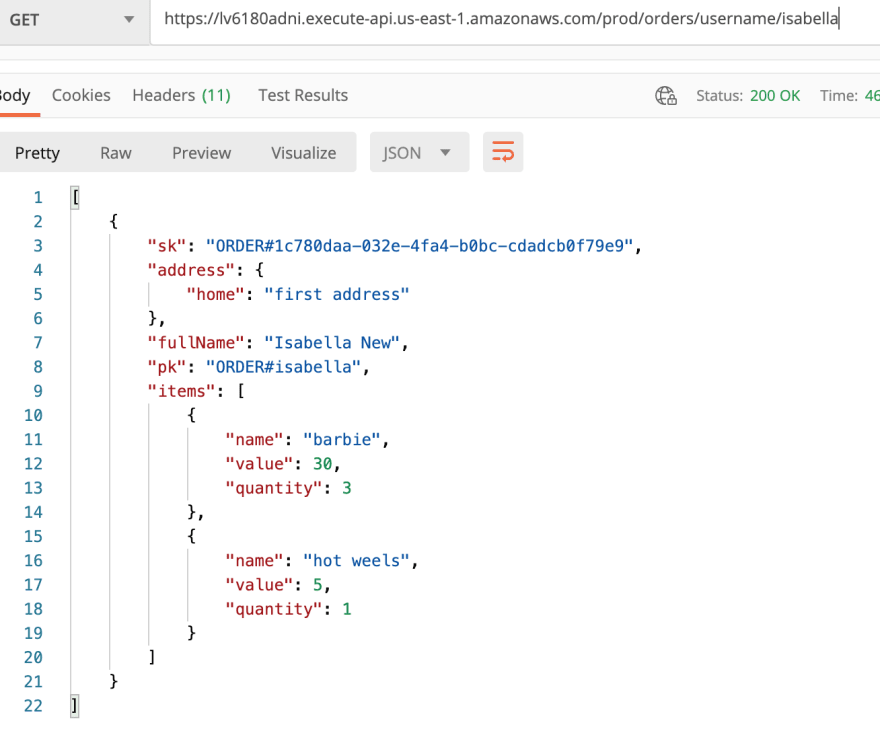
- Listing all orders for each user:

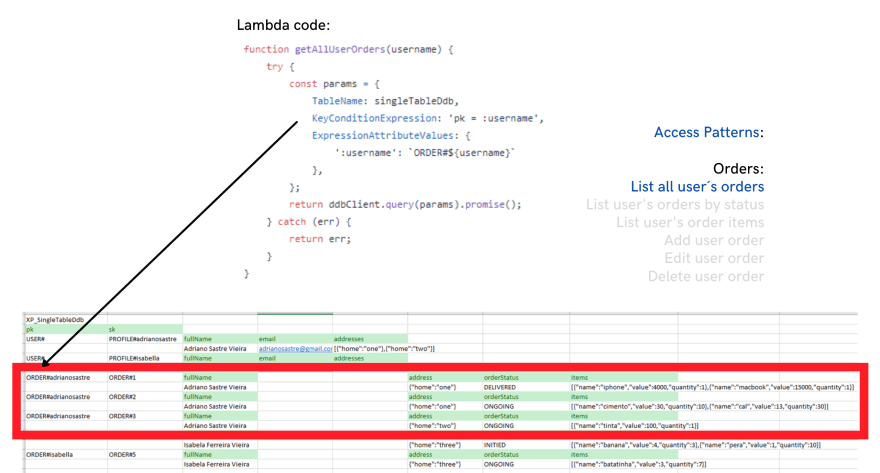
- Listing users orders by status:
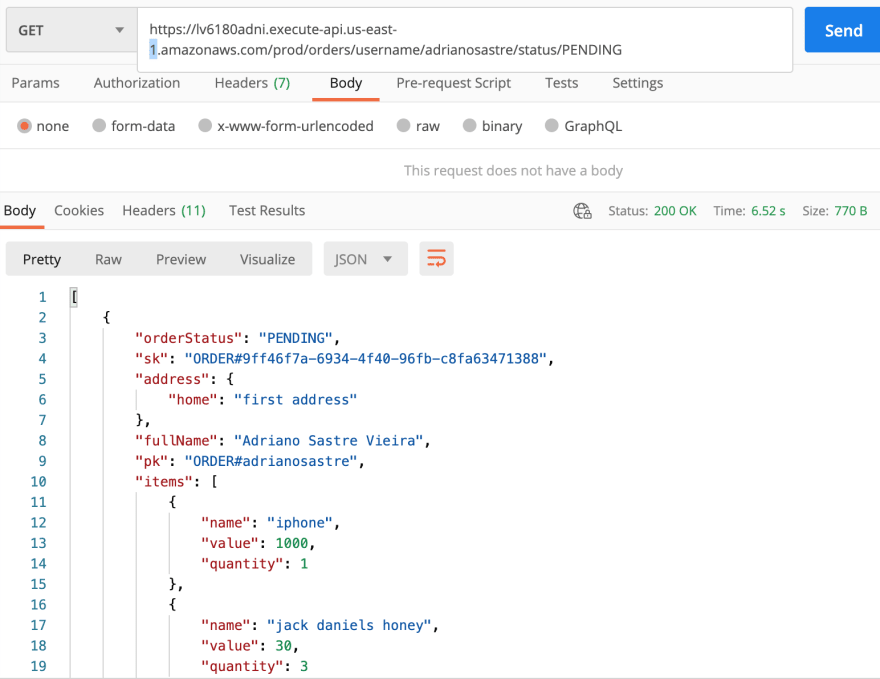
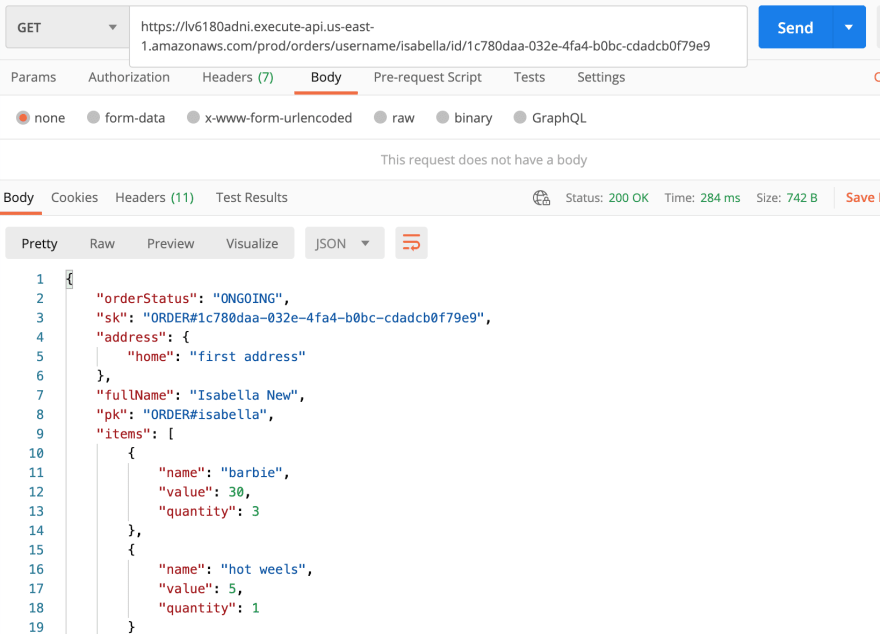
- Listing a user specific order items:
- Editing user order:

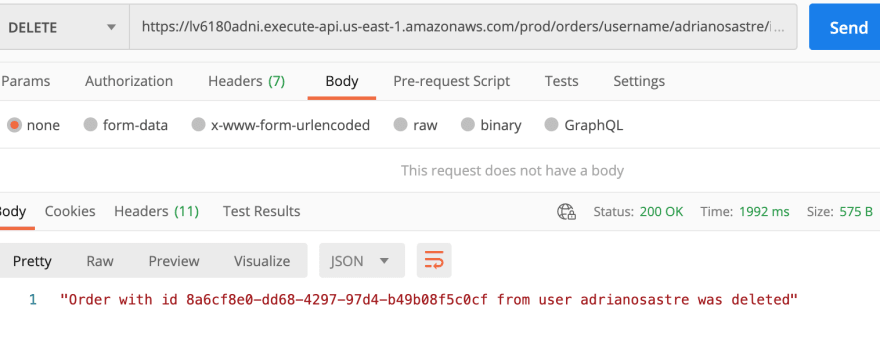
- Deleting user order:
AWS troubleshooting
Things does not always go right from the first time.
In order to troubleshoot AWS services, e.g. the lambdas code, their logs results that can be double-checked on AWS CloudWatch Log Groups. Just click on the respective log group:
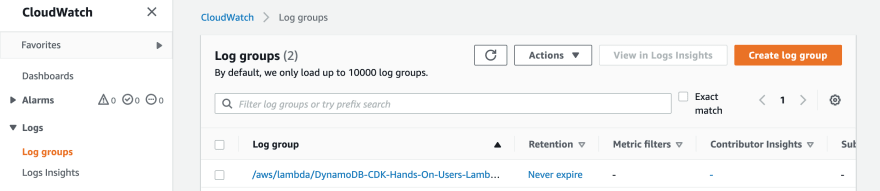
And after that, in the log stream messages:

Remember, logs are our best friends! As stated on this great old Optimal Logging article, "With optimal logging, you can even eliminate the necessity for debuggers!"
Last but not least, in order to track performance, this project lambdas also have X-Ray enabled so you can verify X-Ray traces in ServiceLens.
It is so cool and useful to graphically see the services flow and how much time was spent in each service or function!
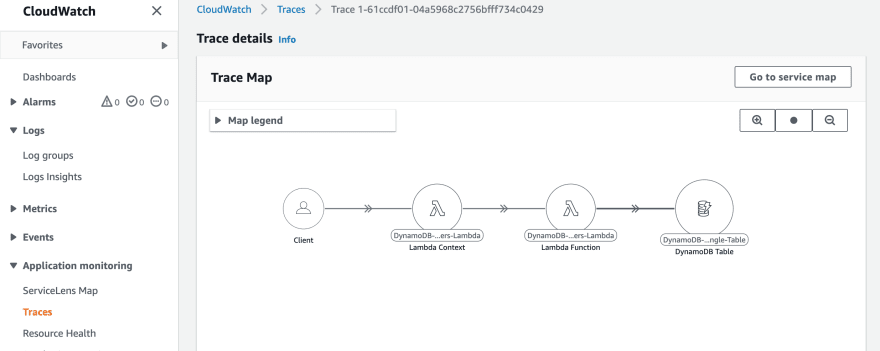
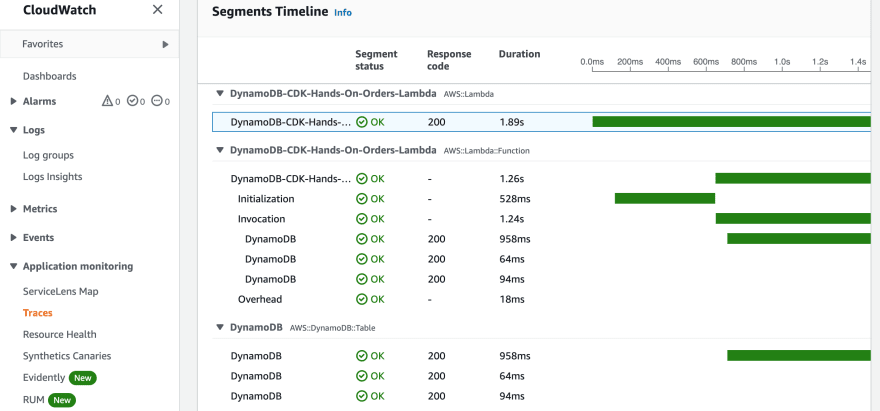
That's all folks!
I hope this article was helpful, and I'm available for any comments or questions here or via adrianosastre@gmail.com
Thanks and have a nice 2022 :)
This content originally appeared on DEV Community and was authored by Adriano Sastre Vieira
Adriano Sastre Vieira | Sciencx (2021-12-30T00:25:12+00:00) AWS Serverless and the DynamoDB Single Table Design – Hands On with CDK v2. Retrieved from https://www.scien.cx/2021/12/30/aws-serverless-and-the-dynamodb-single-table-design-hands-on-with-cdk-v2/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.