
This content originally appeared on Web Performance Calendar and was authored by Nic Jansma
Table of Contents
- The JS Self-Profiling API
- What is Sampled Profiling?
- API
- Who to Profile
- When to Profile
- Overhead
- Anatomy of a Profile
- Beaconing
- Analyzing Profiles
- Gotchas
- Conclusion
The JS Self-Profiling API
The JavaScript Self-Profiling API allows you to take performance profiles of your JavaScript web application in the real world from real customers on real devices. In other words, you’re no longer limited to only profiling your application on your personal machines (locally) from browser developer tools! Profiling your application is a great way to get insight into its performance. A profile will help you see what is running over time (its “stack”), and can identify “hot spots” in your code.
You may be familiar with profiling JavaScript if you’ve ever used a browser’s developer tools. For example, in Chrome’s Developer Tools in the Performance tab, you can record a profile. This profile provides (among other things) a view of what’s running in the application over time.
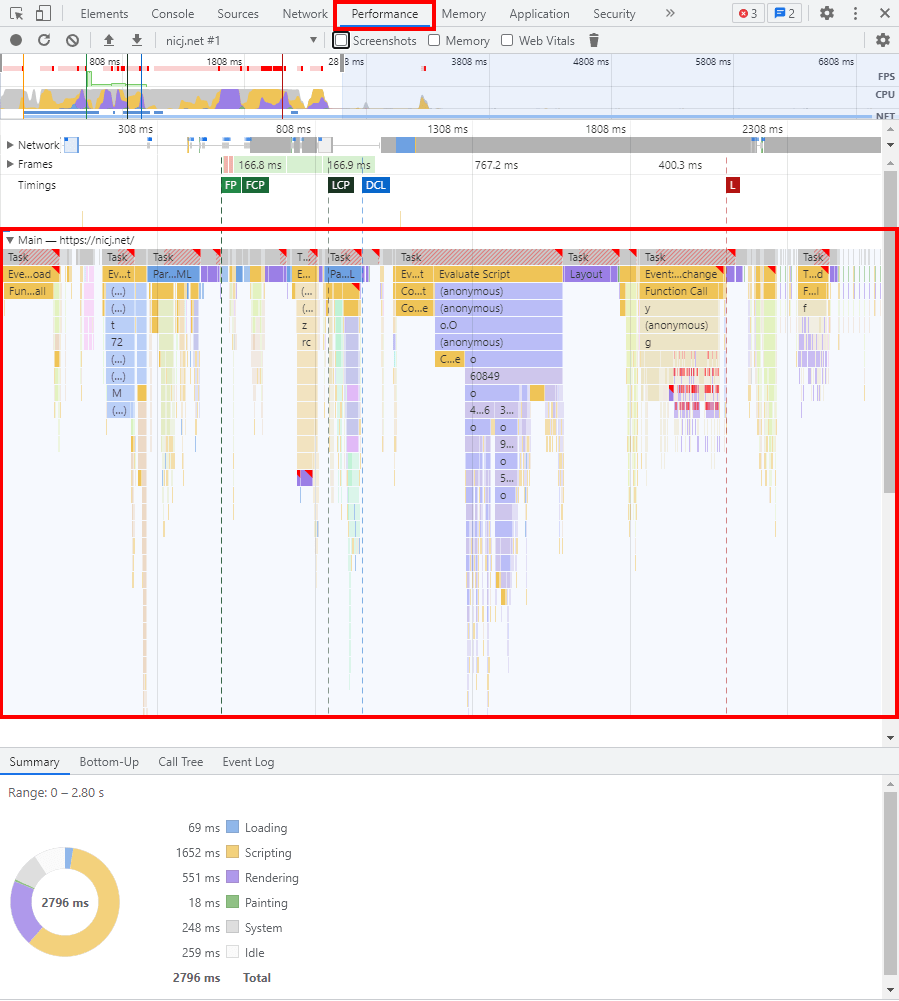
In fact, this API actually reminds me a bit more of the simplicity of the old JavaScript Profiler tab, which is still available in Chrome, but hidden in favor of the new Performance tab.
The JS Self-Profiling API is a new API, currently only available in Chrome versions 94+ (on Desktop and Android). It provides a sampling profiler that you can enable, from JavaScript, for any of your visitors.
The API is a currently a WICG draft, and is being evaluated by browsers before possibly being adopted by a W3C Working Group such as the Web Performance WG.
What is Sampled Profiling?
There are two common types of performance profilers in use today:
- Instrumented (or “structured” or “tracing”) Profilers, in which an application is invasively instrumented (modified) to add hooks at every function entry and exit, so the exact time spent in each function is known
- Sampled Profilers, which temporarily pause execution of the application at a fixed frequency to note (“sample”) what is running on the call stack at that time
The JS Self-Profiling API starts a sampled profiler in the browser. This is the same profiler that records traces in browser developer tools.
The “sampling” part of the profiler means that the browser is basically taking a snapshot at regular intervals, checking what’s currently running on the stack. This is a lightweight way of tracing an application’s performance, as long as the sampling interval isn’t too frequent. Each regularly-spaced sampling interrupt quickly inspects the running stack and notes it for later. Over time, these sampled stacks can give you a indication of what was commonly running during the trace, though sometimes samples can also mislead (see Downsides below).
Consider a diagram of the function stacks running in an application over time. A sampling profiler will attempt to inspect the currently-running stack at regular intervals (the vertical red lines), and report on what it sees:

The other common method of profiling an application, often called a instrumented or tracing or structured profiler, relies on invasively modifying the application so that the profiler knows exactly when every function is called, begins and ends. This invasive measurement has a lot of overhead, and can slow down the application being measured. However, it provides an exact measurement of the relative time being spent in every function, as well as exact function call-counts. Due to the overhead that comes from invasively hooking every function entry and exit, the app will be slowed down (spending time in instrumentation).
Instrumented profiling has a time and place, but it’s generally not performed in the “real world” on your visitors — as it will slow down their experience. This is why sampled profiling is more popular on the web, as it has a smaller performance impact on the application being sampled.
With this API, you can choose the sampling frequency. In my testing, Chrome currently doesn’t let you sample any more frequently than once every 16ms (Windows) or 10ms (Mac / Android).
If you want to learn more about the different types of profiling, I highly recommend viewing Ilya Grigorik’s Structural and Sampling JavaScript Profiling in Google Chrome slides from 2012. It goes into further details about when to use the two types of profilers and how they complement each other.
Note: further in this document I may use the term “traces” to describe the data from a Sampled Profiler, not from a Tracing Profiler.
Downsides to Sampled Profiling
Unlike Instrumented Profilers that trace each function’s entry and exit (which increases the measurement overhead significantly), Sampled Profilers simply poll the stack at regular intervals to determine what’s running.
This type of lightweight profiling is great for reducing overhead, but it can lead to some situations where the data it captures is misleading at best, or wrong at worst.
Let’s look at the previous call stack and the 8 samples it took, pretending the samples were 10ms apart:
Since the Sampled Profiler doesn’t know any better, it guesses that any hit during its regular sampling interval was running for that entire interval, i.e. 10ms.
If a Sampled Profiler was examining that stack at those regular intervals (the vertical red lines), it would report the overall time spent in these stacks as:
- A->B->C: 1 hit (10ms)
- A->B: 2 hits (20ms)
- A: 1 hit (10ms)
- D: 2 hits (20ms)
- idle: 2 (20ms)
While this is a decent representation of what was running over those 80ms, it’s not entirely accurate:
- A->B->C is over-reported by 6ms
- A->B is over-reported by 12ms
- A is under-reported by 8ms
- D is over-reported by 8ms
- D->D->D is missing and under-reported by 4ms
- idle is under-reported by 15ms
This mis-reporting can get worse in a few canonical cases. Most application stacks won’t be this simple, so it’s unlikely you’ll see this happen exactly as-is in the real world, but it’s useful to understand.
First, consider a case where your sampled profiler is taking samples every 10ms, and your application has a task that executes for 2ms approximately every 16ms. Will the Sampled Profiler even notice it was running?

Maybe, or maybe not — depends on when the sampling happens, and the frequency/runtime of the function. In this case, the function is executing for 12.5% of the runtime, but may get un-reported.
Taken to the extreme, this same function may have the exact same interval frequency as the profiler, but only execute for that 1ms that was being sampled:

In this case, the function may be only running for 12.5% of the runtime, but may get reported as running 100% of the time.
To the other extreme, you could have a function which runs at 10ms intervals but only for 8ms:

Depending on when the Sampling Profiler hits, it may not get reported at all, even though it’s executing for 80% of the time.
All of these are “canonically bad” examples, but you could see how some types of program behavior may get mis-represented by a Sampled Profiler. Something to keep in mind as you’re looking at traces!
API
Document Policy
In order to allow the JavaScript Self-Profiling API to be called, there needs to be a Document Policy on the HTML page, called js-profiling. This is usually configured via a HTTP response header called Document-Policy, or via a <iframe policy=""> attribute.
A simple example of enabling the API would be this HTTP response header (for the HTML page):
Document-Policy: js-profiling
Once enabled, any JavaScript on the page can start profiling, including third-party scripts!
API Shape
The JS Self-Profiling API exposes a new Profiler object (in browsers that support it).
Creating the object starts the Sampled Profiler, and you can later call .stop() on the object to stop profiling and get the trace back (via a Promise).
if (typeof window.Profiler === "function")
{
var profiler = new Profiler({ sampleInterval: 10, maxBufferSize: 10000 });
// do work
profiler.stop().then(function(trace) {
sendProfile(trace);
});
}
Or if you’re into whole await thing:
if (typeof window.Profiler === "function")
{
const profiler = new Profiler({ sampleInterval: 10, maxBufferSize: 10000 });
// do work
var trace = await profiler.stop();
sendProfile(trace);
}
The two main options you can set when starting a profile are:
sampleIntervalis the application’s desired sample interval (in milliseconds)- Once started, the true sampling rate is accessible via
profiler.sampleInterval
- Once started, the true sampling rate is accessible via
maxBufferSizeis the desired sample buffer size limit, measured in number of samples
There is usually a measurable delay to starting a new Profiler(), as the browser needs to prepare its profiler infrastructure.
In my testing, I’ve found that new profiles usually take 1-2ms to start (e.g. before new Profiler() returns) on both desktop and mobile.
Sample Interval
The sampleInterval you specify (in milliseconds) determines how frequently the browser wakes up to take samples of the JavaScript call stack.
Ideally, you would want to choose a small enough interval that gives you data as accurately as possible without there being measurement overhead.
The draft spec suggests you need to simply specify a value greater than or equal to zero (though I’m not sure what zero would mean), though the User Agent may choose the rate that it ultimately samples at.
In practice, in Chrome 96+, I’ve found the following minimum sampling rates supported:
- Windows Desktop: 16ms
- Mac/Linux Desktop, Android: 10ms
Meaning, if you specify sampleInterval: 1, you will only get a sampling rate of 16ms on Windows.
You can verify the sampling rate that was chosen by the User Agent by inspecting the .sampleInterval of any started trace:
const profiler = new Profiler({ sampleInterval: 1, maxBufferSize: 10000 });
console.log(profiler.sampleInterval);
In addition, it appears in Chrome that the chosen actual sample interval is rounded up to the next multiple of the minimum, so 16ms (Windows) or 10ms (Mac/Android).
For example, if you choose a sampleInterval of between 91-99ms on Android, you’ll get 100ms instead.
Buffer
The other knob you control when starting a trace is the maxBufferSize. This is the maximum number of samples the Profiler will take before stopping on its own.
For example, if you specify a sampleInterval: 100 and a maxBufferSize: 10, you will get 10 samples of 100ms each, so 1s of data.
If the buffer fills, the samplebufferfull event fires and no more samples are taken.
if (typeof window.Profiler === "function")
{
const profiler = new Profiler({ sampleInterval: 10, maxBufferSize: 10000 });
function collectAndSendProfile() {
if (profiler.stopped) return;
sendProfile(await profiler.stop());
}
profiler.addEventListener('samplebufferfull', collectAndSendProfile);
// do work, or listen for some other event, then:
// collectAndSendProfile();
}
Who to Profile
Should you enable a Sampled Profiler for all of your visitors? Probably not. While the observed overhead appears to be small, it’s best not to burden all visitors with sampling and collecting this data.
Ideally, you would probably sample your Sampled Profiler activations as well.
You could consider turning it on for 10% or 1% or 0.1% of your visitors, for example.
The main reasons you wouldn’t want to enable this for all visitors are:
- While minimal, enabling sampling has some associated cost, so you probably don’t want to slow down all visitors
- The amount of data produced by a sampled profiler trace is significant, and your probably don’t want your servers to have to deal with this data from every visitor
- As of 2021-12, the only browser that supports this API is Chrome, so your profiles will be biased towards that browser, as well as the above downsides
Enabling the profiler for a sample of specific page loads, or a sample of specific visitors seems ideal.
When to Profile
Now that you’ve determined that this current page or visitor should be profiled, when should you turn it on?
There are a lot ways you can utilize profiling during a session: specific events, user interactions, the entire page load itself, and more.
Specific Operations
Your app probably has a few complex operations that it regularly executes for visitors.
Instrumenting these operations (on a sampled basis) may be useful in the cases where you don’t know how the code is flowing and performing in the real world. It could also be useful if you’re calling into third-party scripts where you don’t fully understand their cost.
You could simply start the Profiler at the beginning of the operation and stop it once complete.
The trace data you capture won’t necessarily be limited to just the code you’re profiling, but that can also help you understand if your operations are competing with any other code.
function loadExpensiveThirdParty() {
const profiler = new Profiler({ sampleInterval: 10, maxBufferSize: 1000 });
loadThirdParty(async function onThirdPartyComplete() {
var trace = await profiler.stop();
sendProfile(trace);
});
}
User Interactions
User interactions are great to profile from time to time, especially if metrics like First Input Delay are important to you.
There are a couple approaches you could take regarding when to start the profiler when measuring user interactions:
- Have one always running. When a user interacts, trim the profile to a short amount of time before and after the events
- If you’re using EventTiming and have an active Profiler, you could measure from the event’s
startTimetoprocessingEndto understand what was running before, during and as a result of the event
- If you’re using EventTiming and have an active Profiler, you could measure from the event’s
- Turn on a Profiler once the mouse starts moving, or moving towards a known click-able target
- Turn on a Profiler once there’s an event like
mousedownwhere you expect the user to follow through with their interaction
If you wish to wait for a user interaction to start a profiler, note that creating a new Profiler() has a measurable cost (1-2ms) in many cases.
Here’s an example of having a long-running Profiler available for when there are user interactions, via EventTiming:
// start a profiler to be monitoring all times
let profiler = new Profiler({ sampleInterval: interval, maxBufferSize: 10000 });
// when there are impactful EventTiming events like 'click', filter to those samples and start a new Profiler
const observer = new PerformanceObserver(function(list) {
const perfEntries = list.getEntries().forEach(entry => {
if (profiler && !profiler.stopped && entry.name === 'click') {
profiler.stop().then(function(trace) {
const filteredSamples = trace.samples.filter(function(sample) {
return sample.timestamp >= entry.startTime && sample.timestamp <= entry.processingEnd;
});
// do something with the filteredSamples and the event
// start a new profiler
profiler = new Profiler({ sampleInterval: interval, maxBufferSize: 10000 });
});
}
});
})
.observe({type: 'event', buffered: true});
Page Load
If you want to profile the entire Page Load process, it’s best to start the Profiler via an inline <script> tag before any other Scripts in the <head> of your document.
You could then wait for the page’s onload event, plus a delay, before processing/sending the trace.
You may also want to listen to the pagehide or visibilitychange events to determine if the visitor abandons the page before it fully loads, and send the profile then. Note there are challenges when sending from unload events.
If you’re measuring other important aspects, metrics and events of the Page Load process, like Long Tasks or EventTiming events, having a Sampled Profiler trace to understand what was running during those events can be very enlightening.
Overhead
Any time you enable a profiler, the browser will be doing extra work to capture the performance data. Luckily a Sampled Profiler is a bit cheaper to do than an Instrumented Profiler, but what is its cost in the real-world?
Facebook, one of the primary drivers of this API, has reported that initial data suggests enabling profiling slows load time by <1% (p=0.05).
In my own experimentation on one of my websites, there was no noticeable difference in Page Load times between sessions with profiling enabled and those without.
This is great news, though I would love to see more experimentation and evaluation of the performance impacts of this API. If you’ve used the JS Self-Profiling API, please share your experimentation results!
Anatomy of a Profile
The profile trace object returned from the Profiler.stop() Promise callback is described in the spec’s appendix, and contains four main sections:
framescontains an array of frames, i.e. individual functions that could be part of a stack- You may see DOM functions (such as
set innerHTML) or evenProfiler(for work the Sampled Profiler is doing) here - If a frame is missing a
nameit’s likely JavaScript executing in the root of a<script>tag or external JavaScript file, see this note for a workaround
- You may see DOM functions (such as
resourcescontains an array of all of the resources that contained functions that have a frame in the trace- The page itself is often (always?) the first in the array, with any other external JavaScript files or pages following
samplesare the actual profiler samples, with a correspondingtimestampfor when the sample occurred and astackIdpointing at the stack executing at that time- If there is no
stackId, nothing was executing at that time
- If there is no
stackscontains an array of frames that were running on the top of the stack- Each stack may have an optional
parentId, which maps into the next node of the tree for the function that called it (and so forth)
- Each stack may have an optional
This format is unique to the JS Self-Profiling API, and cannot be used directly in any other tool (at the moment).
Here’s a full example:
{
"frames": [
{ "name": "Profiler" }, // the Profiler itself
{ "column": 0, "line": 100, "name": "", "resourceId": 0 }, // un-named function in root HTML page
{ "name": "set innerHTML" }, // DOM function
{ "column": 10, "line": 10, "name": "A", "resourceId": 1 } // A() in app.js
{ "column": 20, "line": 20, "name": "B", "resourceId": 1 } // B() in app.js
],
"resources": [
"https://example.com/page",
"https://example.com/app.js",
],
"samples": [
{ "stackId": 0, "timestamp": 161.99500000476837 }, // Profiler
{ "stackId": 2, "timestamp": 182.43499994277954 }, // app.js:A()
{ "timestamp": 197.43499994277954 }, // nothing running
{ "timestamp": 213.32999992370605 }, // nothing running
{ "stackId": 3, "timestamp": 228.59999990463257 }, // app.js:A()->B()
],
"stacks": [
{ "frameId": 0 }, // Profiler
{ "frameId": 2 }, // set innerHTML
{ "frameId": 3 }, // A()
{ "frameId": 4, "parentId": 2 } // A()->B()
]
}
To figure out what was running over time, you look at the samples array, each entry containing a timestamp of when the sample occurred.
For example:
"samples": [
...
{ "stackId": 3, "timestamp": 228.59999990463257 }, // app.js:A()->B()
...
]
If that sample does not contain a stackId, nothing was executing.
If that sample contains a stackId, you look it up in the stacks: [] array by the index (3 in the above):
"stacks": [
...
2: { "frameId": 3 }, // A()
3: { "frameId": 4, "parentId": 2 } // A()->B()
]
We see that stackId: 3 is frameId: 4 with a parentId: 2.
If you follow the parentId chain recursively, you can see the full stack. In this case, there are only two frames in this stack:
frameId:4 frameId:3
From those frameIds, look into the frames: [] array to map them to functions:
"frames": [
...
3: { "column": 10, "line": 10, "name": "A", "resourceId": 1 } // A() in app.js
4: { "column": 20, "line": 20, "name": "B", "resourceId": 1 } // B() in app.js
],
So the stack for the sample at 228.59999990463257 above is:
B() A()
Meaning, A() called B().
Beaconing
Once a Sampled Profile trace is stopped, what should you do with the data? You probably want to exfiltrate the data somehow.
Depending on the size of the trace, you could either process it locally first (in the browser), or just send it raw to your back-end servers for further analysis.
If you will be sending the trace elsewhere for processing, you will probably want to gather supporting evidence with it to make the trace more actionable.
For example, you could gather alongside the trace:
- Performance metrics, such as Page Load Time or any of the Core Web Vitals
- These can help you understand if the Sampled Profile trace is measuring a user experience that was “good” vs. “bad”
- Supporting performance events, such as Long Tasks or EventTiming events
- These can help you understand what was happening during “bad” events by correlating samples with events such as Long Tasks
- User Experience characteristics, such as User Agent / Device information, page dimensions, etc
- These can help you slice-and-dice your data, and help narrow down your search if you come across patterns of “bad” experiences
Sampled Profiles are most helpful when you can understand the circumstances under which they were taken, so make sure you have enough information to know whether the trace is a “good” user experience or a “bad” one.
Size
Depending on the frequency (sampleInterval) and duration (or maxBufferSize) of your profiles, the resulting trace data can be 10s or 100s of KB! Simply taking the JSON.stringify() representation of the data may not be the best choice if you intend on uploading the raw trace to your server.
In a sample of ~50,000 profiles captured from my website, where I was profiling from the start of the page through 5 seconds after Page Load, the traces averaged about 25 KB in size. The median page load time on this site is about 2 seconds, so these traces captured about 7 seconds of data. These traces are essentially the JSON.stringify() output of the trace data.
The good news is 25 KB is reasonable where you could just take the simplest approach and upload it directly to a server for processing.
Compression
You also have a few other options for reducing the size of this data before you upload, if you’re willing to trade some CPU time.
One option is the Compression Stream API, which gives you the ability to get a gzip-compressed stream of data from your string input. It should be available (in Chrome) whenever the JS Self-Profiling API is available. One downside is that it is (currently) async-only, so you will need to wait for a callback with the compressed bytes, before you can upload your compressed profile data.
If you expect to send this data via the application/x-www-form-urlencoded encoding, be aware that URL-encoding JSON.stringify() strings results in a much larger string. For example, a 25 KB JSON object from JSON.stringify() grows to about 36 KB if application/x-www-form-urlencoded encoded.
To avoid this bloat, you could alternatively consider something like JSURL. JSURL is an interesting library that looks similar to JSON, but encodes a bit smaller for URL-encoded data (like application/x-www-form-urlencoded data).
Besides these generic compression methods that can be applied to any string data, someone smart could probably come up with a domain-specific compression scheme for this data if they desired! Please!
Analyzing Profiles
Once you’ve started capturing these profiles from your visitors and have been beaconing them to your servers, now what?
Assuming you’re sending the full trace data (and not doing profile analysis in the browser before beaconing), you have a lot of data to work with.
Let’s split the discussion between looking at individual profiles (for debugging) and in bulk (aggregate analysis).
Individual Profiles
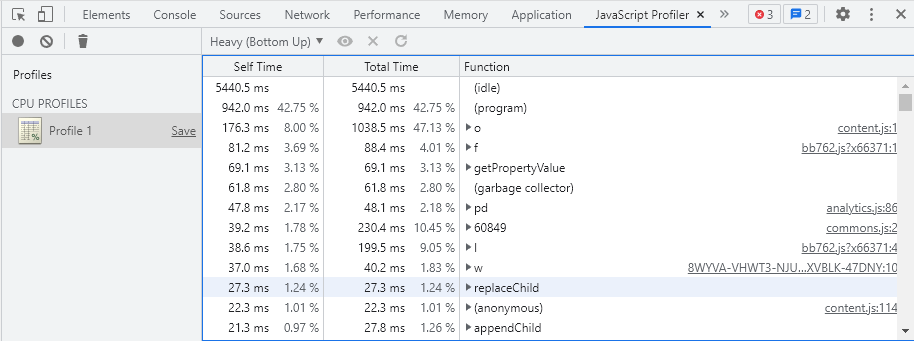
As far as I’m aware, there aren’t any openly-available ways of visualizing this trace data in any of the common browser developer tools.
While the JS Self-Profiling API Readme mentions that:
Mozilla’s perf.html visualization tool for Firefox profiles or Chrome’s trace-viewer (chrome://tracing) UI could be trivially adapted to visualize the data produced by this profiling API.
I do not believe this had been done yet.
Ideally, someone could either update one of the existing visualization tools, or write a converter to change the JS Self-Profiling API format into one of the existing formats. I have seen a comment from a developer that the Specto visualization tool may be able to display this data soon, which would be great!
Until then, I don’t think it’s very feasible to review individual traces “by hand”.
With the knowledge of the trace format and just a little bit of code, you could easily post-process these traces to pick out interesting aspects of the traces. Which brings us to…
Bulk Profile Analysis
Given a large number of sampled profiles, what insights could you gain from them?
This is an inherently challenging problem. Given a sample of visitors with tracing enabled, and each trace containing KB or MB of trace data, knowing how to effectively use that data to narrow down performance problems is no easy feat.
The infrastructure required to do this type of bulk analysis is not insignificant, though it really boils down to post-processing the traces and aggregating those insights in ways that make sense.
As a starting point, there are at least a few ways of distilling sampled profile traces down into smaller data points. By aggregating this type of information for each trace, you may be able to spot patterns, such as which hot functions are more often seen in slower scenarios.
For example, given a single sampled profile trace, you may be able to extract its:
- Top N function(s) (by exclusive time)
- Top N function(s) (by inclusive time)
- Top N file(s)
If you captured other supporting information alongside the profile, such as Long Tasks or EventTiming events, you could provide more context to why those events were slow as well!
Aggregating this information into a traditional analytics engine, and you may be able to gain insight into which code to focus on.
Gotchas
Of course, no API is perfect, and there are a few ways this API can be confusing, misleading, or hard to use.
Here are a few gotchas I’ve encountered.
Minified JavaScript
If your application contains minified JavaScript, the Sampled Profiles will report the minified function names.
If you will be processing profiles on your server, you may want to un-minify them via the Source Map artifacts from the build.
Named Functions
One issue that I came across while testing this API on personal websites was that I was finding a lot of work triggered by “un-named” functions:
{
"frames": [
...
{ "column": 0, "line": 10, "name": "", "resourceId": 0 }, // un-named function in root HTML page
{ "column": 0, "line": 52, "name": "", "resourceId": 0 }, // another un-named function in root HTML page
...
],
These frames were coming from the page itself (resourceId: 0), i.e. inline <script> tags.
They’re hard to map back to the original function in the HTML, since the page’s HTML may differ by URL or by visitor.
One thing that helped me group these frames better was to change the inline <script>‘s JavaScript so that they run from named anonymous functions.
e.g. instead of:
<script> // start some work </script>
Simply wrap it in a named IIFE (Immediately Invoked Function Expression):
<script>
(function initializeThirdPartyInHTML() {
// start some work
})();
</script>
Then the frames array provides better context:
{
"frames": [
...
{ "column": 0, "line": 10, "name": "initializeThirdPartyInHtml", "resourceId": 0 }, // now with 100% more name!
{ "column": 0, "line": 52, "name": "doOtherWorkInHtml", "resourceId": 0 },
...
],
Cross-Origin Scripts
When the API was first being developed and experimented with, it came with a requirement that the page being profiled have cross-origin isolation (COI) via COOP and COEP. If any third-party script did not enable COOP/COEP, then the API could not be used.
This requirement unfortunately made the API nearly useless for any site that includes third-party content, as forcing those third-parties into COOP/COEP compliance is tricky at best.
Thankfully, after some discussion, the implementation in Chrome was updated, and the COI requirement was dropped.
However, there are still major challenges when you utilize third-party scripts. In order to not leak private information from third-party scripts, they are treated as opaque unless they opt-in to CORS. This is primarily to ensure their call stacks aren’t unintentionally leaked, which may include private information. Any cross-origin JavaScript that is in a call-stack will have its entire frame removed unless it has a CORS header.
This is analogous to the protections that cross-origin scripts have in JavaScript error events, where detailed information (line/column number) is only available if the script is same-origin or CORS-enabled.
When applied to Sampled Profiles, this has some strange side-effects.
For any cross-origin script (that is not opt-in to CORS) that has a frame in a sample, its entire frame will be removed, without any indication that this has been done. As a result, this means that some of the stacks may be misleading or confusing.
Consider a case where your same-origin JavaScript calls into one or more cross-origin function:

Guess what the profiler will report?
sameOriginFunction()20ms
Even though the two functions crossOriginFunctionA() and crossOriginFunctionB() accounted for a most of the runtime, the JS Self-Profiling API will remove those frames entirely from the report, and limit its reporting to sameOriginFunction().
It’s even stranger if those cross-origin functions call back into same-origin functions. Consider a third-party utility library like jQuery that might do this?

The profiler will report:
sameOriginFunction()10mssameOriginFunction() -> sameOriginCallback()10ms
In other words, it pretends the cross-origin functions don’t even exist. This could make debugging these types of stacks very confusing!
To ensure your third-party scripts are CORS-enabled, you need to do two things:
- The origin serving the third-party JavaScript needs to have the
Access-Control-Allow-OriginHTTP response header set - The embedding HTML page needs to set
<script src="..." crossorigin="anonymous"></script>
Once these have been set, the third-party JavaScript will be treated the same as any same-origin content and its frame/function/line/column numbers available.
Sending from Unload Events
One challenge with using the JS Self-Profiling API is that to get the trace data, you need to rely on a Promise (callback) from .stop().
As a result, you really can’t use this function in page unload handlers like beforeunload or unload, where promises and callbacks may not get the chance to fire before the DOM is destroyed.
So if you want to use the JS Self-Profiling API, you won’t be able to wait until the page is being unloaded to send your profiles. If you want to profile a session for a long time, you would need to consider breaking up the profiles into multiple pieces and beacon at a regular interval to ensure you received most (but probably not the final) trace.
This is unfortunate for one scenario, which is page loads that are delayed due to a third-party resource or other heavy site execution. I would expect many consumers of this API to trace from the beginning of the page to the load event. But if the visitor leaves the page before it fully loads (say due to a delayed third-party resource), the unload event will fire before the load event, and there will be no opportunity to get the callback from the Profiler.stop().
I’ve filed an issue to see if there are any better ways of addressing unload scenarios.
Non-JavaScript Browser Work
One of the issues with the current profiler is that non-JavaScript execution isn’t represented in profiles.
As a result, top-level User Agent work like HTML Parsing, CSS Style and Layout Calculation, and Painting will appear as “empty” samples.
Other activity like JavaScript garbage collection (GC) will also be “empty” in samples.
There is a proposal for the User Agent to add optional “markers” for specific samples, if it wants the profiler to know about non-JavaScript work:
enum ProfilerMarker { "script", "gc", "style", "layout", "paint", "other" };
...
"samples" : [
{ "timestamp" : 100, "stackId": 2, "marker": "script" },
{ "timestamp" : 110, "stackId": 2, "marker": "gc" },
{ "timestamp" : 120, "stackId": 3, "marker": "layout" },
{ "timestamp" : 130, "stackId": 2, "marker": "script" },
{ "timestamp" : 140, "stackId": 2, "marker": "script" },
}
...
This is still just a proposal, but if implemented it will provide a lot more context of what the browser is doing in profiles.
Conclusion
The JS Self-Profiling API is still under heavy development, experimentation and testing. There are open issues in the Github repository where work is being tracked, and I would encourage anyone utilizing the API to post feedback there.
We’ve heard feedback from Facebook and Microsoft and others that the API has been useful in identifying and fixing performance issues from customers.
Looking forward to hearing others giving the API a try and their results!
(this post also appears on nicj.net)
This content originally appeared on Web Performance Calendar and was authored by Nic Jansma
Nic Jansma | Sciencx (2021-12-31T18:06:38+00:00) JS Self-Profiling API In Practice. Retrieved from https://www.scien.cx/2021/12/31/js-self-profiling-api-in-practice/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.