
This content originally appeared on DEV Community and was authored by Stephen Borsay
When working with data from devices transmitted to AWS, serverless IoT workflows can save the customer a tremendous amount of money.
Instead of setting up an “always on” EC2 instance the client can engage individual AWS services only as needed. This multi-part IoT series will cover a variety of methods, with increasing levels of sophistication and functionality, to visualize IoT data on a static web host using various IoT centric services on AWS. The overall cost of using these AWS serverless services, even assuming you are off the free tier, will be pennies for normal use.
This hands-on workshop series will start off with an easy use case: synchronous polling of IoT data from a S3 bucket being held as a IoT data repository delivered from AWS IoT Core. For reasons which will soon be obvious this isn't an optimal design. However there is an undeniable, inverse correlation between complexity and functionality in this use case, so this is a good place to start. If you are ok with “near real-time” IoT, and some lost IoT data payloads are acceptable, than this simplified technique, explained in this first tutorial in the series, will be of interest. As a special bonus I will provide all the code necessary to complete this lab and visualize your own IoT data on your own AWS account. It is sure to impress your friends and family (as long as we keep them in the dark about some initial shortcomings to be remedied later). I have also created a series of videos hosted on YouTube to help you to complete the workshop and clear up any ambiguities from this written tutorial.
YouTube: https://youtu.be/MsyzeXMu23w
An assumption of this first AWS IoT serverless workshop is that you have a device programmed to send IoT data payloads to AWS IoT Core. I’m not going provide device code here or explain how to implement the code on a device. You can reference my classes on AWS IoT on Udemy for coding various devices to communicate with AWS IoT Core utilizing a variety of IDE’s. However, good news, you don’t need to program any devices for this tutorial series as I will show you how to use the AWS MQTT test client as well as an automated Bash script to send fake IoT JSON payloads to the MQTT broker on AWS IoT Core. This is a functional substitute for a real embedded device producing real IoT data. For actual use cases you can always implement code on your device later if you want to add the device component for real IoT data publishing.
This first article in this hands-on workshop series will use synchronous polling in JavaScript to extract data from an S3 bucket in near real time. The next article in the series will switch to use AWS WebSockets with Lambda using API Gateway to transmit “real-time" data to our JavaScript visualization without the need to store data in S3 as a temporary repository. From there we will move on to using WebSockets with Lambda, MQTT, and the AWS IoT JavaScript SDK in the browser for a more professional look and feel while also taking advantage of real-time IoT transmissions. Finally we will conclude the series by using the newest real-time techniques for serverless IoT that utilize GraphQL for real-time data visualizations which should obviate the need, if not the performance, of AWS WebSockets. To get the advantage of asynchronicity we are reliant on using a "server push" model as opposed to the "client pull" model we use in this tutorial. The "server push" model has been traditionally problematic for a serverless environment.
Table of contents:
- Step 1 - Creating a public bucket in S3 for your IoT data
- Step 2 - Creating an Action and Rule in AWS IoT Core
- Step 3 – Testing your Serverless IoT design flow
- Step 4 – Converting your S3 bucket into a static webhost
- Step 5 – Uploading your HTML and JavaScript code to create a Visualization for your IoT data.
- Step 6 – Populating the visualization using an automated IoT data producer
All the code posted in this tutorial can also be found at:
https://github.com/sborsay/Serverless-IoT-on-AWS/tree/master/Level4_design/1_Synchronous_IoT
✅ Step 1 - Creating a public bucket in S3 for your IoT data
Whenever we create a public bucket the first caveat is to confirm the bucket will only store data that we don’t mind sharing with the world. For our example we are just using the S3 bucket to hold IoT JSON data showing temperature, humidity, and timestamps. I think sharing basic environmental data from an unknown location is not too much of a privacy risk. The advantage of using a public bucket for our static webhost, with an open bucket policy and permissive CORS rule, is that it makes the website easily accessible from anywhere in the world without having to use a paid service like AWS CloudFront and Route 53.
Since re:Invent 2021 AWS has changed the process in which to make a S3 bucket public. They have added one extra default permission which must be proactively changed to insure you are not declaring a public bucket by mistake. AWS is especially concerned with people making buckets public unintentionally, the danger being that they will hold sensitive or personal data, and in the past unethical hackers have used search tools to find private data in S3 public buckets to exploit them. Fortunately for our use case, we don’t care about outsiders viewing our environmental data.
Many of you already know how to make a S3 public bucket for a static webhost on AWS. For those that don’t know how to do this in 2022, I will document it below. I have also created a short video you can watch here:
YouTube link: https://youtu.be/NRroUUR9kdg

Making a Public S3 Bucket
The process of creating a public S3 bucket for website hosting
Go to AWS S3 and then select “Create bucket”
A) Give your bucket a globally unique name, here I call mine a catchy name: mybucket034975
B) Keep your S3 bucket in the same region as the rest of your AWS services for this lab.
C) Switch “Object Ownership” to “ACL’s enabled”, this is new for late 2021! We now must first enable our Access Control Lists to make them public.

D) Unblock your S3 bucket and acknowledge your really want to do this. Scary anti-exculpatory stuff! 😧
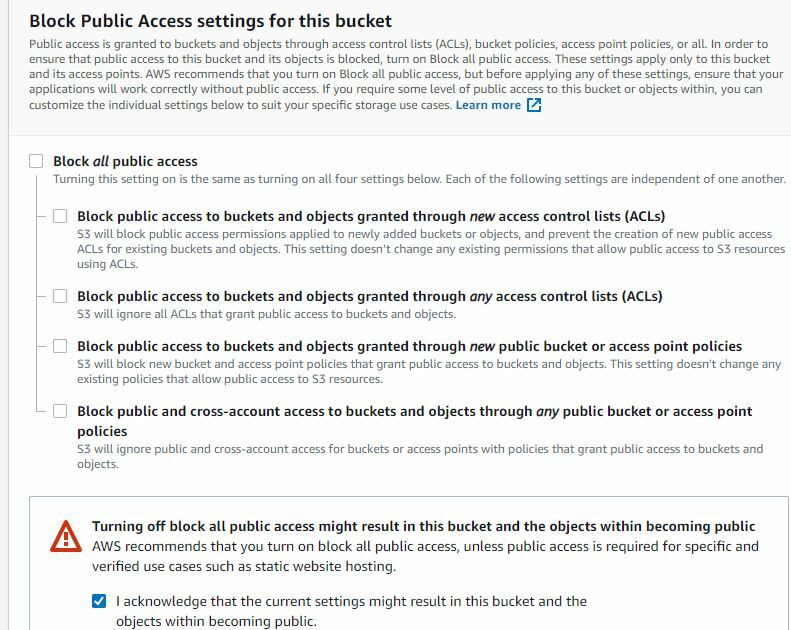
F) Finally, select the “Create bucket” button at the bottom of the screen. That's all you have to do for this page, but don’t worry, we are going to have more opportunity to make sure we really, really, and truly want to create a public bucket soon. 👍

G) Now go back into your newly created bucket and click on the “Permissions” tab.
F) Go to Bucket Policy and choose “Edit.” We will paste and save a basic read-only policy.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "PublicRea2411145d",
"Effect": "Allow",
"Principal": "*",
"Action": [
"s3:GetObject",
"s3:GetObjectVersion"
],
"Resource": "arn:aws:s3:::<Paste-Your-Bucket-Name-Here>/*"
}
]
}
You must paste the name of your bucket into the policy then follow it by ‘/*’ to allow access to all Get/Read partitions within the bucket. Also it's a good idea to change the “Sid” to something unique within your account.
G) Now we get a chance to visit that ACL we enabled earlier in this process. Click “Edit” then make the changes as shown below:
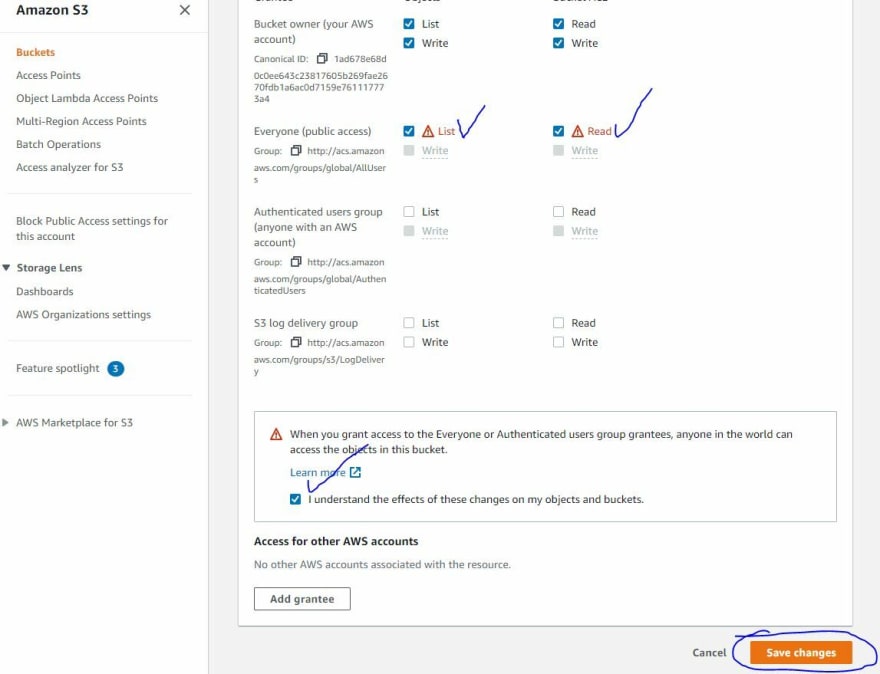
We are giving “Everyone,” or at least those know or can discover our unique bucket URL, permission to read our bucket info. Click on the 'List' and 'Read' buttons where shown and then acknowledge again that you are extra special certain that you want to do this 😏. Then click “Save changes.”
H) Wow, we are at our last step in creating a public bucket. Now we should set the CORS policy so we don’t get any pesky “mixed use” access-control non-allowed origin issues for cross domain access – I hate those 😠! CORS rules used to be in XML only format and then AWS decided to keep everything consistent and switch the CORS format to JSON. Even though this change caused some legacy conflict issues with existing XML CORS rules it was the right choice as JSON is clearly better than XML despite what the SOAP fans on social media will tell you 👍. Below is a generic CORS JSON document you can use in your own S3 bucket:
[
{
"AllowedHeaders": [
"Authorization"
],
"AllowedMethods": [
"GET"
],
"AllowedOrigins": [
"*"
],
"ExposeHeaders": [],
"MaxAgeSeconds": 6000
}
]
That’s it for making your cheap and easily accessible public bucket!
In my Udemy course I speak more about inexpensive ways to add security while avoiding paying for CloudFront or Route 53 for accessible public buckets and static websites in S3. However I will tacitly reveal “one weird trick” that I find very effective for pretty good protection regarding free S3 public bucket security: Simply google “restrict IP range in a S3 public bucket policy.”
✅ Step 2 - Create an Action and Rule in AWS IoT Core
AWS IoT Core is a great service with a built-in server side MQTT broker that has the functionality to dispatch our incoming IoT data payloads to a variety of AWS services. For this first lab we will simply be sending our data to our S3 bucket. To do this we need to create an 'Action' and 'Rule' in IoT Core, then we design our rule to send our IoT data to the S3 public bucket that we just created.
The first step is to create a new rule in IoT Core:

Now give your Rule a name of your choice. Next, we need to edit the Rules Query Statement (RQS) to select what information we will extract or add to our JSON IoT Payload. To make things easier we will use one of the built-in functions AWS provides for the RQS to enrich our IoT data payload:
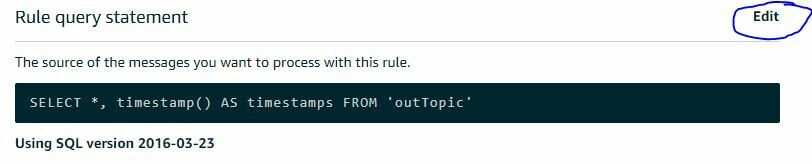
For our use case we are adding a Unix/Epoch timestamp to our incoming IoT JSON payload. I rename the timestamp as 'timestamps'. The reason for this specific name is that I want the name to be a literal match for how I designate the variable in the JavaScript Code on our upcoming website. The MQTT topic name itself is unimportant for this first tutorial, you can call your MQTT topic whatever name you like, here I call mine ‘outTopic’ (as it is coming ‘out’ from my device). In the tutorials coming up it will be more important how we name and format our topic in the RQS.
Next, we have to add an 'Action' for our 'Rule.' We want to send our IoT message to the S3 bucket we just created so select that as your rule:

Now press the “Configure action” button at the bottom of the screen.
Next we must select the bucket we just created and name the 'Key' in which we will save our IoT data. We also have to create a Role which gives our Action a permission policy to send our IoT data between IoT Core and our S3 bucket. We will let AWS automatically create this Role.
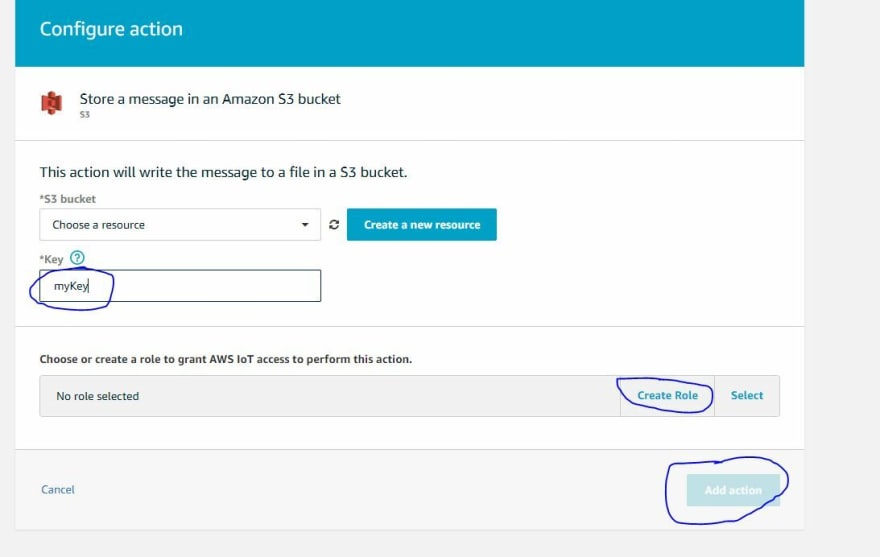
The things to do here:
- 1. Select the S3 public open bucket you just created in the S3 bucket field.
- 2. Give your key (blob object) a name.
- 3. Create a role to give your Action the correct permissions.
- 4. Press the “Add action” button.
Finally, insure your action is “Enabled” in the next screen by using the breadcrumbs next to the Rule name you just created (usually at the bottom of the list as your last Rule).
✅ Step 3 - Test your Serverless IoT design flow
At this point let's test the serverless IoT design flow we developed to make sure everything is working before we move on to uploading our code to our static webhost on S3. To test our design flow we should send some fake IoT data to S3 from the MQTT Test client in AWS IoT Core. To do this go to the "MQTT test client" tab on the left and select the “Publish” tab. This will allow us to send IoT JSON payloads to our public S3 bucket using the Action/Rule we just created. Let's enter a sample IoT JSON payload of temperature and humidity as shown below. Remember, we don’t need to use a "timestamps” key value in our IoT payload because our RQS adds a UNIX timestamp to our payload automatically. We will publish our JSON IoT payload under to topic name of ‘outTopic’ or whatever you choose to name you topic that matches the RQS.
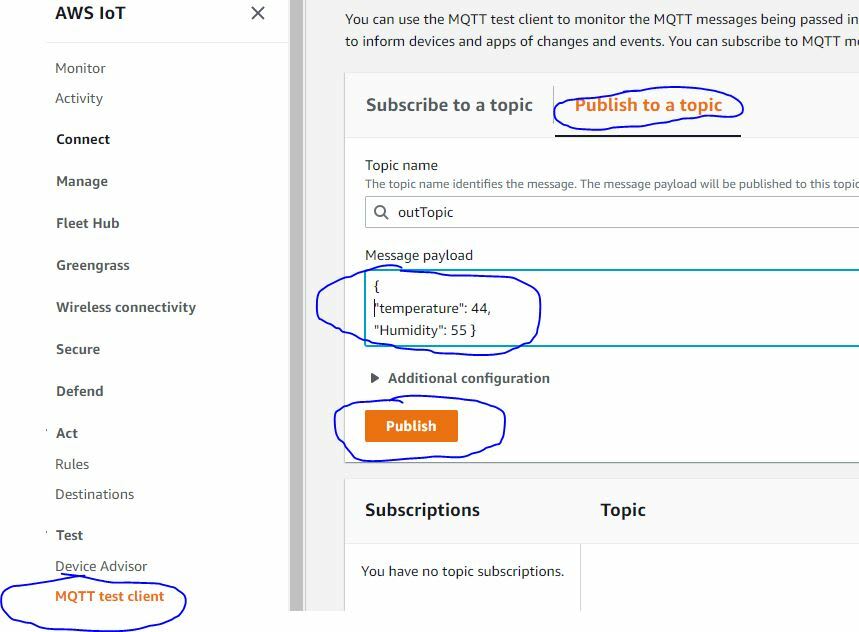
Things to do here:
- 1. Select MQTT test client.
- 2. Select the Publish tab.
- 3. Type a test payload in proper JSON format like: { “temperature”: 44, “humidity”: 55}
- 4. Press the “Publish” button.
Now go to the public bucket you just created in S3. Look under the key object that you designated in your Rule/Action in IoT Core. It should be something like an anomalous object named “myKey” in our example. Go ahead and download the blob object named "myKey" and open it in the editor of your choice:

Now if everything was done correctly you should see the JSON payload you just sent from IoT Core. If you sent multiple payloads you will only see the last payload sent as the object is overwritten in S3 with each successive payload. You can't concatenate or edit blob objects in S3. As an aside there is an easy way to create a data lake with multiple objects with the S3 Action we just created but I won't go over that here. For our purposes we are only going to fetch the last JSON payload held within the S3 object store on a given interval (polling).
✅ Step 4 - Convert your S3 bucket into a static Webhost
As I said before AWS makes it so the same S3 bucket can be enabled to both hold IoT data and to host a static website with a static IP address for pennies a month.
We are now ready to convert our public bucket so that it can facilitate hosting a static website. We could have easily have done this in Step 1 and still use the same bucket as a blob object store, as well as a website, but converting it to a static website now makes more procedural sense. The conversion is quite simple.
Go to your S3 public bucket, select the "Properties" tab, then scroll down to the bottom where we can edit "Static website hosting" and select "Edit."

Now enable website hosting and name your index document “index.html”, this will be our landing page for our visualization website. Click “Save changes” at the bottom of the page and you are good to go.

That’s it! Now your open public bucket is configured as a webhost with a unique URL address that is statically available worldwide. You have just changed your uber cheap and accessible public bucket into a uber cheap and accessible public bucket that can also host a static website with a static IP address. 😲
✅ Step 5 - Upload your HTML and JavaScript code to create a visualization for your IoT Data.
We have two documents to upload to our public bucket and our newly created webhost. The files are called 'index.html' and 'main.js'.
The index.html is our launch page. Copy the following code and save it locally as "index.html":
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Dashboard</title>
</head>
<body>
<div class="container">
<h1>Synchronous Weather Data on Interval</h1>
<div class="panel panel-info">
<div class="panel-heading">
<h3 class="panel-title"><strong>Line Chart</strong></h3>
</div>
<div class="panel-body">
<div id="container1"></div>
</div>
</div>
</div>
<script src="https://code.jquery.com/jquery-3.1.1.min.js"></script>
<script src="https://code.highcharts.com/highcharts.js"></script>
<script src="./main.js"></script>
</body>
</html>
The main.js is our JavaScript page. Copy the following code save it as "main.js":
let humArr = [], tempArr = [], upArr = [];
let myChart = Highcharts.chart('container1', {
title: {
text: 'Line chart'
},
subtitle: {
text: 'subtitle'
},
yAxis: {
title: {
text: 'Value'
}
},
xAxis: {
categories: upArr
},
legend: {
layout: 'vertical',
align: 'right',
verticalAlign: 'middle'
},
plotOptions: {
series: {
label: {
connectorAllowed: false
}
}
},
series: [{
name: 'Humdity',
data: []
}, {
name: 'Temperature',
data: []
}],
responsive: {
rules: [{
condition: {
maxWidth: 500
},
chartOptions: {
legend: {
layout: 'horizontal',
align: 'center',
verticalAlign: 'bottom'
}
}
}]
}
});
let getWheatherData = function () {
$.ajax({
type: "GET",
url: "<Insert-Your-IoT-Data-Bucket-With-Key-Here>", //example: https://mydatabucket.s3.amazonaws.com/myKey"
dataType: "json",
async: false,
success: function (data) {
console.log('data', data);
drawChart(data);
},
error: function (xhr, status, error) {
console.error("JSON error: " + status);
}
});
}
let drawChart = function (data) {
let { humidity, temperature, timestamps } = data;
humArr.push(Number(humidity));
tempArr.push(Number(temperature));
upArr.push(Number(timestamps));
myChart.series[0].setData(humArr , true)
myChart.series[1].setData(tempArr , true)
}
let intervalTime = 3 * 1000; // 3 second interval polling, change as you like
setInterval(() => {
getWheatherData();
}, intervalTime);
The only change you need to make to the code is on line 62 of the main.js file. You need to insert the URL of your 'key' which is a "Object URL" listed in your S3 bucket.
You can find your data object address (URL) by copying it from your bucket as demonstrated by the image below. It is the ‘Object URL’ with the 'https://' prefix. This object URL should look something like this:
https://yourbucket.s3.amazonaws.com/myKey
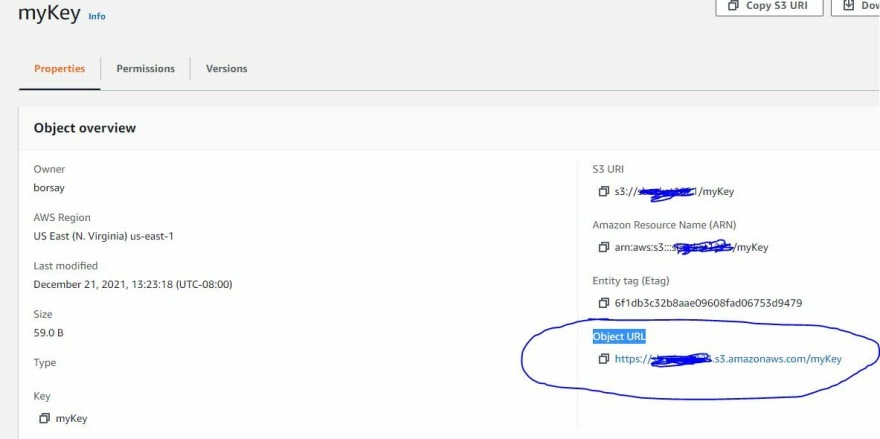
After changing this line of code in 'main.js' to your own data location URL in S3, you are now ready to upload the files you just saved locally into your bucket. To do this simply select the 'Objects' tab in your S3 bucket and drag both files to the base level of your bucket. Both files, and your IoT data object ('myKey'), should be on the same level of the partition hierarchy.

Press the 'upload' button on the bottom right of your screen, and then after both files have been uploaded select the 'close' button. You should now have three objects in you bucket; your IoT data object with your JSON readings (myKey), as well as your two web code files('index.html' and 'main.js').
The Highcharts code works by fetching data from or S3 bucket by a configurable number of seconds. Obviously it can over and under fetch data on the set interval but it will provide a nice visualization given a certain amount of delay and inaccuracy, assuming that is acceptable. We will remedy most of these issues in the coming workshops when we use AWS WebSockets with AWS Lambda for asynchronous invocations.
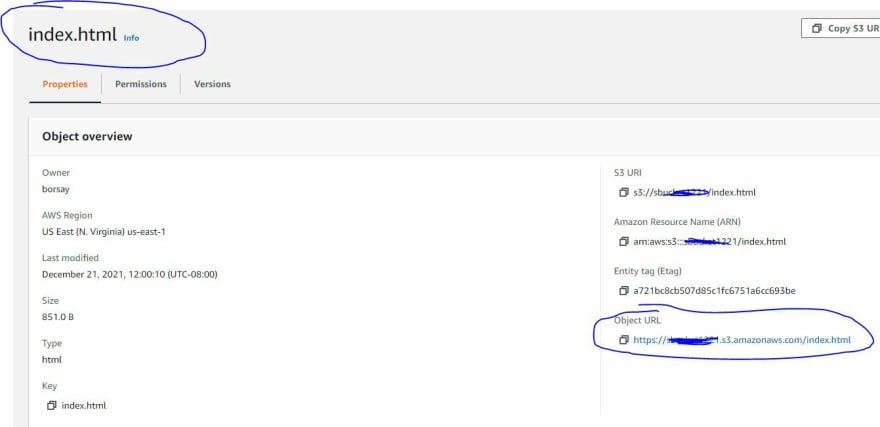
Now is a good time to initiate your static webhost by opening a new web browser tab with your static website URL. The address of your website can be found by going to the “index.html” object in your bucket and opening the 'Object URL.' Clicking this URL will bring up your website.
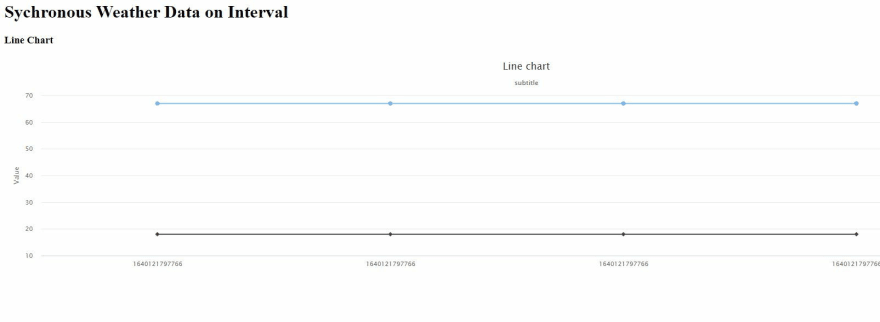
Don't worry if you see a couple of straight lines for temperature and humidity on your website. The visualization is simply extending the last test IoT data point you manually published from the MQTT test client. You will know the data point is stale as the timestamp is duplicated across the X-axis of the chart.
✅ Step 6 - Populating the visualization using an automated IoT data producer
For this last step we have three ways to populate the visualization from IoT Core to our webhost.
A) Use a device to publish IoT JSON payloads under our topic name.
B) Manually publish JSON data payloads from the MQTT test client in IoT Core as demonstrated earlier in the tutorial.
C) Use a test script to publish IoT data to our topic automatically at a set interval.
For option A you can simply program your device to publish data to IoT core as I instruct in my course. For option B you would have to spend some time manually altering then publishing JSON payloads in the MQTT test client to generate the line chart in the visualization.
For this tutorial I will explain 'option C.' For this option you need the AWS CLI installed. It’s easy to install with the directions listed here:
https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html
This bash IoT data producer script was provided by AWS and can be originally found on https://github.com/aws-samples. I have already altered the test script to send just temperature and humidity data. Simply insert your AWS region and MQTT topic name (outTopic) into the test script where indicated. The bash script uses your AWS CLI to deliver the payload to IoT Core (using your SigV4 credentials from the AWS CLI). You can also change the number of payloads published (iterations) and wait time between each publish (interval) to produce as much fake IoT data as you like.
#!/bin/bash
mqtttopic='<Insert-Your-IoT-Topic-Here>'
iterations=10
wait=5
region='<Insert-Your-AWS-Test-Region-Here>'
profile='default'
for (( i = 1; i <= $iterations; i++)) {
#CURRENT_TS=`date +%s`
#DEVICE="P0"$((1 + $RANDOM % 5))
#FLOW=$(( 60 + $RANDOM % 40 ))
#TEMP=$(( 15 + $RANDOM % 20 ))
#HUMIDITY=$(( 50 + $RANDOM % 40 ))
#VIBRATION=$(( 100 + $RANDOM % 40 ))
temperature=$(( 15 + $RANDOM % 20 ))
humidity=$(( 50 + $RANDOM % 40 ))
# 3% chance of throwing an anomalous temperature reading
if [ $(($RANDOM % 100)) -gt 97 ]
then
echo "Temperature out of range"
TEMP=$(($TEMP*6))
fi
echo "Publishing message $i/$ITERATIONS to IoT topic $mqtttopic:"
#echo "current_ts: $CURRENT_TS"
#echo "deviceid: $DEVICE"
#echo "flow: $FLOW"
echo "temperature: $temperature"
echo "humidity: $humidity"
#echo "vibration: $VIBRATION"
#use below for AWS CLI V1
#aws iot-data publish --topic "$mqtttopic" --payload "{\"temperature\":$temperature,\"humidity\":$humidity}" --profile "$profile" --region "$region"
#use below for AWS CLI V2
aws iot-data publish --topic "$mqtttopic" --cli-binary-format raw-in-base64-out --payload "{\"temperature\":$temperature,\"humidity\":$humidity}" --profile "$profile" --region "$region"
sleep $wait
}
You have to change fields at the top of the page in the bash script to customize it for your MQTT topic name (outTopic) and AWS region ('us-east-1 or other) in which you developed your AWS services for this tutorial. The other two fields, 'iterations' and 'wait time', are optional to edit.
- mqtttopic=''
- iterations (number of payloads to send)
- wait time (number of seconds between transmissions)
- region=''
Now save the above code, giving it a name like "iot_tester.sh". You can run the script by simply installing the bash script locally on your computer and then from the command prompt typing the name of the bash script. Bash scripts should work on any operating system. Activating the test script in MS Windows looks like this:

You can now return to your websites index page and see you visualization getting populated by new data points on the delay of your setInterval() function in 'main.js.'
A few troubleshooting tips for most common issues.
Did you keep your S3 bucket and other AWS services all in the same region?
Does your web browsers cache refresh automatically. On my computer Chrome doesn't inherently refresh upon each new data point, thus I get stale data from S3 resulting in a flat chart. My other five browsers refresh by default for new data. Try the index page on other browsers if you are not getting data point updates for your visualization in your current browser.
😀 🏁
Congratulations! You finished the first tutorial in the series and created the World's Simplest Synchronous Serverless IoT Dashboard. I bet all your friends will be impressed. Make sure to stay tuned for parts two, three, and four of this hands-on tutorial series as we get more advanced with Serverless IoT on AWS.
This content originally appeared on DEV Community and was authored by Stephen Borsay
Stephen Borsay | Sciencx (2022-01-07T20:20:44+00:00) World’s Simplest Synchronous AWS IoT Dashboard. Retrieved from https://www.scien.cx/2022/01/07/worlds-simplest-synchronous-aws-iot-dashboard/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.