
This content originally appeared on DEV Community and was authored by Adit Modi
Having the ability to process and analyze this data in real-time is essential to do things such as continuously monitor your applications to ensure high service uptime and personalize promotional offers and product recommendations.
Real-time and near-real-time processing can also make other common use cases, such as website analytics and machine learning, more accurate and actionable by making data available to these applications in seconds or minutes instead of hours or days.
Common near-real-time use cases include analytics on data stores for data science and machine learning (ML).

Streaming data solutions on AWS is a series containing different articles that review several scenarios for streaming workflows. In these scenarios, streaming data & processing it provides the example companies with the ability to add new features and functionality. By analyzing data as it gets created, they can gain insights into what their business is doing.
- AWS streaming services enable you to focus on your application to make time-sensitive business decisions, rather than deploying and managing the infrastructure.
Scenario 2: Near-real-time data for security teams
Company "ABC2Badge" provides sensors and badges for corporate or large-scale events such as AWS re:Invent. Users sign up for the event and receive unique badges that the sensors pick up across the campus. As users pass by a sensor, their anonymized information is recorded into a relational database.
In an upcoming event, due to the high volume of attendees, "ABC2Badge" has been requested by the event security team to gather data for the most concentrated areas of the campus every 15 minutes.
This will give the security team enough time to react and disperse security personal proportionally to concentrated areas. Given this new requirement from the security team and the inexperience of building a streaming solution, to process date in near-real-time, "ABC2Badge" is looking for a simple yet scalable and reliable solution.
Their current data warehouse solution is Amazon Redshift. While reviewing the features of the Amazon Kinesis services, they recognized that Amazon Kinesis Data Firehose can receive a stream of data records, batch the records based on buffer size and/or time interval, and insert them into Amazon Redshift.
They created a Kinesis Data Firehose delivery stream and configured it so it would copy data to their Amazon Redshift tables every five minutes. As part of this new solution, they used the Amazon Kinesis Agent on their servers.
Every five minutes, Kinesis Data Firehose loads data into Amazon Redshift, where the business intelligence (BI) team is enabled to perform its analysis and send the data to the security team every 15 minutes.

New solution using Amazon Kinesis Data Firehose
Amazon Kinesis Data Firehose
Amazon Kinesis Data Firehose is the easiest way to load streaming data into AWS. It can capture, transform, and load streaming data into Amazon Kinesis Data Analytics, Amazon Simple Storage Service (Amazon S3), Amazon Redshift, Amazon OpenSearch Service (OpenSearch Service), and Splunk.
Additionally, Kinesis Data Firehose can load streaming data into any custom HTTP endpoint or HTTP endpoints owned by supported third-party service providers.
Kinesis Data Firehose enables near-real-time analytics with existing business intelligence tools and dashboards that you’re already using today.
It’s a fully managed serverless service that automatically scales to match the throughput of your data and requires no ongoing administration. Kinesis Data Firehose can batch, compress, and encrypt the data before loading, minimizing the amount of storage used at the destination and increasing security.
It can also transform the source data using AWS Lambda and deliver the transformed data to destinations. You configure your data producers to send data to Kinesis Data Firehose, which automatically delivers the data to the destination that you specify.
Sending data to a Firehose delivery stream
To send data to your delivery stream, there are several options. AWS offers SDKs for many popular programming languages, each of which provides APIs for Amazon Kinesis Data Firehose.
AWS has a utility to help send data to your delivery stream. Kinesis Data Firehose has been integrated with other AWS services to send data directly from those services into your delivery stream.
Using Amazon Kinesis agent
Amazon Kinesis agent is a standalone software application that continuously monitors a set of log files for new data to be sent to the delivery stream. The agent automatically handles file rotation, checkpointing, retries upon failures, and emits Amazon CloudWatch metrics for monitoring and troubleshooting of the delivery stream.
Additional configurations, such data pre-processing, monitoring multiple file directories, and writing to multiple delivery streams, can be applied to the agent.
The agent can be installed on Linux or Windows-based servers such as web servers, log servers, and database servers. Once the agent is installed, you simply specify the log files it will monitor and the delivery stream it will send to. The agent will durably and reliably send new data to the delivery stream.
Using API with AWS SDK and AWS services as a source
The Kinesis Data Firehose API offers two operations for sending data to your delivery stream. PutRecord sends one data record within one call. PutRecordBatch can send multiple data records within one call, and can achieve higher throughput per producer. In each method, you must specify the name of the delivery stream and the data record, or array of data records, when using this method.
For more information and sample code for the Kinesis Data Firehose API operations, see Writing to a Firehose Delivery Stream Using the AWS SDK.
Kinesis Data Firehose also runs with Kinesis Data Firehose, CloudWatch Logs, CloudWatch Events, Amazon Simple Notification Service (Amazon SNS), Amazon API Gateway, and AWS IoT. You can scalably and reliably send your streams of data, logs, events, and IoT data directly into a Kinesis Data Firehose destination.
Processing data before delivery to destination
In some scenarios, you might want to transform or enhance your streaming data before it is delivered to its destination. For example, data producers might send unstructured text in each data record, and you need to transform it to JSON before delivering it to OpenSearch Service. Or you might want to convert the JSON data into a columnar file format such as Apache Parquet or Apache ORC before storing the data in Amazon S3.
Kinesis Data Firehose has built-in data format conversion capability. With this, you can easily convert your streams of JSON data into Apache Parquet or Apache ORC file formats.
Data transformation flow
- To enable streaming data transformations, Kinesis Data Firehose uses a Lambda function that you create to transform your data. Kinesis Data Firehose buffers incoming data to a specified buffer size for the function and then invokes the specified Lambda function asynchronously. The transformed data is sent from Lambda to Kinesis Data Firehose, and Kinesis Data Firehose delivers the data to the destination.
Data format conversion
- You can also enable Kinesis Data Firehose data format conversion, which will convert your stream of JSON data to Apache Parquet or Apache ORC. This feature can only convert JSON to Apache Parquet or Apache ORC. If you have data that is in CSV, you can transform that data via a Lambda function to JSON, and then apply the data format conversion.
Data delivery
- As a near-real-time delivery stream, Kinesis Data Firehose buffers incoming data. After your delivery stream’s buffering thresholds have been reached, your data is delivered to the destination you’ve configured. There are some differences in how Kinesis Data Firehose delivers data to each destination, which this paper reviews in the following sections.
Amazon S3
- Amazon S3 is object storage with a simple web service interface to store and retrieve any amount of data from anywhere on the web. It’s designed to deliver 99.999999999% durability, and scale past trillions of objects worldwide.
Data delivery to Amazon S3
For data delivery to Amazon S3, Kinesis Data Firehose concatenates multiple incoming records based on the buffering configuration of your delivery stream, and then delivers them to Amazon S3 as an S3 object. The frequency of data delivery to S3 is determined by the S3 buffer size (1 MB to 128 MB) or buffer interval (60 seconds to 900 seconds), whichever comes first.
Data delivery to your S3 bucket might fail for various reasons. For example, the bucket might not exist anymore, or the AWS Identity and Access Management (IAM) role that Kinesis Data Firehose assumes might not have access to the bucket.
Under these conditions, Kinesis Data Firehose keeps retrying for up to 24 hours until the delivery succeeds. The maximum data storage time of Kinesis Data Firehose is 24 hours. If data delivery fails for more than 24 hours, your data is lost.
Amazon Redshift
Amazon Redshift is a fast, fully managed data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing BI tools.
It enables you to run complex analytic queries against petabytes of structured data using sophisticated query optimization, columnar storage on high-performance local disks, and massively parallel query running.
Data delivery to Amazon Redshift
For data delivery to Amazon Redshift, Kinesis Data Firehose first delivers incoming data to your S3 bucket in the format described earlier. Kinesis Data Firehose then issues an Amazon Redshift COPY command to load the data from your S3 bucket to your Amazon Redshift cluster.
The frequency of data COPY operations from S3 to Amazon Redshift is determined by how fast your Amazon Redshift cluster can finish the COPY command. For an Amazon Redshift destination, you can specify a retry duration (0–7200 seconds) when creating a delivery stream to handle data delivery failures.
Kinesis Data Firehose retries for the specified time duration and skips that particular batch of S3 objects if unsuccessful. The skipped objects' information is delivered to your S3 bucket as a manifest file in the errors/ folder, which you can use for manual backfill.
Following is an architecture diagram of Kinesis Data Firehose to Amazon Redshift data flow. Although this data flow is unique to Amazon Redshift, Kinesis Data Firehose follows similar patterns for the other destination targets.
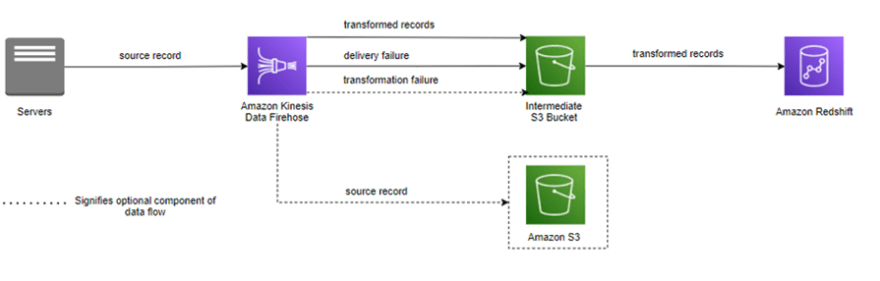
Data flow from Kinesis Data Firehose to Amazon Redshift
Amazon OpenSearch Service (OpenSearch Service)
- OpenSearch Service is a fully managed service that delivers the OpenSearch easy-to-use APIs and real-time capabilities along with the availability, scalability, and security required by production workloads. OpenSearch Service makes it easy to deploy, operate, and scale OpenSearch for log analytics, full text search, and application monitoring.
Data delivery to OpenSearch Service
For data delivery to OpenSearch Service, Kinesis Data Firehose buffers incoming records based on the buffering configuration of your delivery stream, and then generates an OpenSearch bulk request to index multiple records to your OpenSearch cluster.
The frequency of data delivery to OpenSearch Service is determined by the OpenSearch buffer size (1 MB to 100 MB) and buffer interval (60 seconds to 900 seconds) values, whichever comes first.
For the OpenSearch Service destination, you can specify a retry duration (0–7200 seconds) when creating a delivery stream. Kinesis Data Firehose retries for the specified time duration, and then skips that particular index request. The skipped documents are delivered to your S3 bucket in the elasticsearch_failed/ folder, which you can use for manual backfill.
Amazon Kinesis Data Firehose can rotate your OpenSearch Service index based on a time duration. Depending on the rotation option you choose (NoRotation, OneHour, OneDay, OneWeek, or OneMonth), Kinesis Data Firehose appends a portion of the Coordinated Universal Time (UTC) arrival timestamp to your specified index name.
Custom HTTP endpoint or supported third-party service provider
- Kinesis Data Firehose can send data either to Custom HTTP endpoints or supported third-party providers such as Datadog, Dynatrace, LogicMonitor, MongoDB, New Relic, Splunk, and Sumo Logic.
Custom HTTP endpoint or supported third-party service provider
For Kinesis Data Firehose to successfully deliver data to custom HTTP endpoints, these endpoints must accept requests and send responses using certain Kinesis Data Firehose request and response formats.
When delivering data to an HTTP endpoint owned by a supported third-party service provider, you can use the integrated AWS Lambda service to create a function to transform the incoming record(s) to the format that matches the format the service provider's integration is expecting.
For data delivery frequency, each service provider has a recommended buffer size. Work with your service provider for more information on their recommended buffer size. For data delivery failure handling, Kinesis Data Firehose establishes a connection with the HTTP endpoint first by waiting for a response from the destination.
Kinesis Data Firehose continues to establish connection, until the retry duration expires. After that, Kinesis Data Firehose considers it a data delivery failure and backs up the data to your S3 bucket.
Summary
Kinesis Data Firehose can persistently deliver your streaming data to a supported destination. It’s a fully-managed solution, requiring little or no development. For Company ABC2Badge, using Kinesis Data Firehose was a natural choice.
They were already using Amazon Redshift as their data warehouse solution. Because their data sources continuously wrote to transaction logs, they were able to leverage the Amazon Kinesis Agent to stream that data without writing any additional code.
Now that company ABC2Badge has created a stream of sensor records and are receiving these records via Kinesis Data Firehose, they can use this as the basis for the security team use case.
Hope this guide helps you understand how to Design a Streaming Data Solution on AWS for a "Near-real-time data for security teams" scenario.
Let me know your thoughts in the comment section 👇
And if you haven't yet, make sure to follow me on below handles:
👋 connect with me on LinkedIn
🤓 connect with me on Twitter
🐱💻 follow me on github
✍️ Do Checkout my blogs
Like, share and follow me 🚀 for more content.

This content originally appeared on DEV Community and was authored by Adit Modi
Adit Modi | Sciencx (2022-02-03T03:23:46+00:00) Streaming Data Solutions on AWS – Part 2. Retrieved from https://www.scien.cx/2022/02/03/streaming-data-solutions-on-aws-part-2/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.