
This content originally appeared on DEV Community and was authored by Vivek0712
A Data Scientist's worst nightmare is seeing his Machine Learning model deployment fail at production. But how do we really ensure that the deployment targets are resilient enough to handle the incoming prediction traffic? This blog walks you through applying Chaos Engineering approaches in Machine Learning Operations (MLOps) to establish a well-architected Azure solution.
The blog covers three main sections
- Introduction to Chaos Engineering
- Deploying ML Model to AKS Cluster in Azure
- Create and Run Chaos experiment on AKS in Azure
Let's get started!
Introduction to Chaos Engineering
Remember when we were kids, we used to take wooden sticks from ground and try to break them into two halves by bending them. Sometimes, we try to shatter the complete stick by hammering them. Most importantly, we are more curious to know "the point" when the stick breaks. The point actually represents the strength of the stick to withstand the stress and pressure.
This is exactly what Chaos Engineering means. Let's try to understand the analogy here
Start with hypothesis - Measuring the strength of wooden stick
Measure baseline behavior - Typical strength of stick
Inject a fault or faults - Break / Hammer the stick
Monitor the resulting behavior - Observing the point when stick breaks
The goal is to observe, monitor, respond to, and improve our system's reliability under adverse circumstances.
Coming to our use case, we will observe our Machine Learning deployment target - Azure Kubernetes Cluster by inject faults and validate that the service is able to handle faults gracefully.
Deploying ML Model to AKS Cluster in Azure
To keep things simple for the sake of blog, we will be using the existing Azure Quickstart Jupiter Notebook for the deployment of Machine Learning to AKS Cluster. Let's follow simple steps to get it done.
- Create a Machine Learning Workspace.
In Azure Portal, search for Machine Learning resource and create one!

- Create a compute instance
Launch the Machine Learning Studio and create a compute instance from Compute Tab. Select suitable Compute VM.

- Clone the Quickstart
Once the compute instance is up and running, click Jupyter. Then Jupyter is launched, navigate to Sample tabs and search for "Production Deploy to AKS" Quickstart.
Follow the code sample of the production-deploy-to-aks.ipynb to deploy your model to AKS.
Once the model is successfully deployed as web service in AKS, we will be able to make predictions using Run method or HTTP calls.

Create and Run Chaos experiment on AKS in Azure
The main objective of the performing chaos experiment on our Machine Learning deployment target is to observe, monitor the resilient feature of AKS to ensure it can handle service faults in production.
Let's head over to Chaos Studio in Azure Portal. There are two main terminologies we need to understand before proceeding.
Targets - The service which you want test.
Experiment - Designing the fault that needs to be applied on the target service.
Now we will be creating a chaos experiment that uses a Chaos Mesh fault to fail and kill AKS pods with the Azure portal.
Let's follow the Microsoft documentation to fail our AKS machine learning deployment pods. Link here

The JsonSpec of the experiment is as follows:
{"action":"pod-failure","mode":"one","duration":"30s","selector":{"namespaces":["default"]}}
We can see the experiment details as follows in the Chaos Studio Experiment:
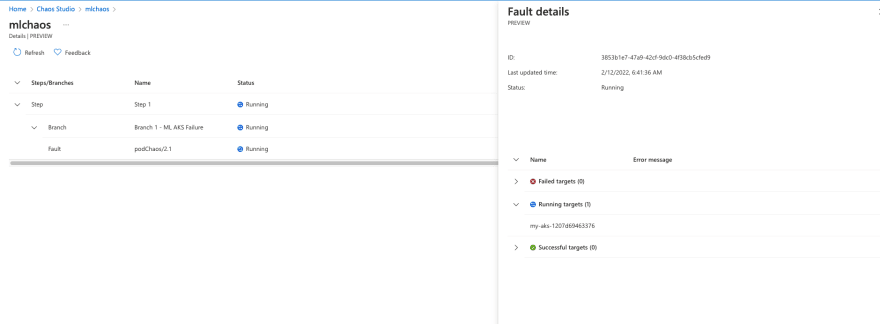
Once the experiment has started we can observe the live pod health status in CLI or AKS Cluster Overview in Portal.

We can observe the pod has restarted when the pod was killed as result of Chaos Experiment. The prediction service is uninterrupted.

Observation and Inference of Chaos Experiment:
Observation
We noticed that we were able to successfully inject pod failure in our AKS Machine Learning Deployment. The failed pod restarted immediately.
Inference
If AKS finds multiple unhealthy nodes during a health check, each node is repaired individually before another repair begins. Thus, the model prediction services remain uninterrupted.
To summarise, we had deployed a Machine Learning on AKS service cluster. We performed Chaos Engineering experiment in which we injected faults in the deployment targets to test the resilience of the service.
By conducting fault-injection experiments, you can confirm that monitoring is in place and alerts are set up, the directly responsible individual (DRI) process is effective, and your documentation and investigation processes are up to date.
In future blogs, we will try to inject Chaos Engineering in different process of MLOps to understand how we can ensure that our production service meet our exceptions.
This content originally appeared on DEV Community and was authored by Vivek0712
Vivek0712 | Sciencx (2022-02-12T11:39:52+00:00) Introducing Chaos Engineering to Machine Learning deployments. Retrieved from https://www.scien.cx/2022/02/12/introducing-chaos-engineering-to-machine-learning-deployments/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.