
This content originally appeared on Level Up Coding - Medium and was authored by Vadym Barylo
In part1 of this journey, we designed the initial stage of the strategy verification pipeline that focused on internal behavioral checks and overall vacuum strategy profitability measurement.
These include:
- strategy class definition matches code quality rules defined by the development team (linting)
- strategy behavioral characteristics match predefined use cases (unit testing)
- strategy execution on historical data match defined profitability threshold
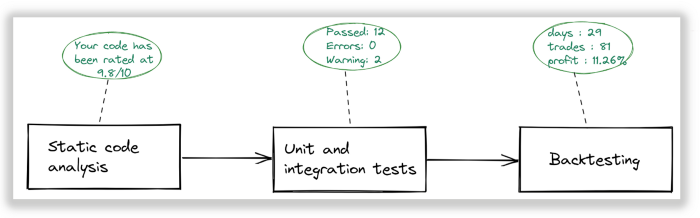
But just to remind — why do we do all this, if we can just begin trading and see strategy profitability? Exactly because of the opposite reason — avoid trading using inefficient algorithms. Inefficient here means — an algorithm that didn’t pass check from stakeholders and subject matter experts and shows the results below the defined thresholds.
Once the feature proposal is accepted, the next stage is to promote it to a prod-like environment using a release train for a more robust verification. It is needed to ensure that “vacuum” verification meets the challenges of the real world.
Release train
The necessity of release train is to automate code promotion from multiple distributed teams to the defined environment with minimal development and cross-team agreement costs. In our case “code” can be read as “strategy”.
Also, topic sensitivity requires a human error-free promotion process avoiding sensitive data exposition and misconfiguration.
We need at least 3 environments for a new strategy to move through to be fully adopted. “Adopted” here means the strategy design that we can trust for the long run.
These environments are:
- Test: strategy is running in “dry-run” mode with no actual portfolio connected
- Sandbox: strategy is running in “live” mode with significantly reduced portfolio weight (smaller stake amount and smaller open trades limit)
- Prod: strategy is running in “live” mode with a required portfolio weight in a more stable and highly secured environment (increased resources and better cloud availability characteristics, private virtual network with limited role-based access, and zero-trust architecture in mind).
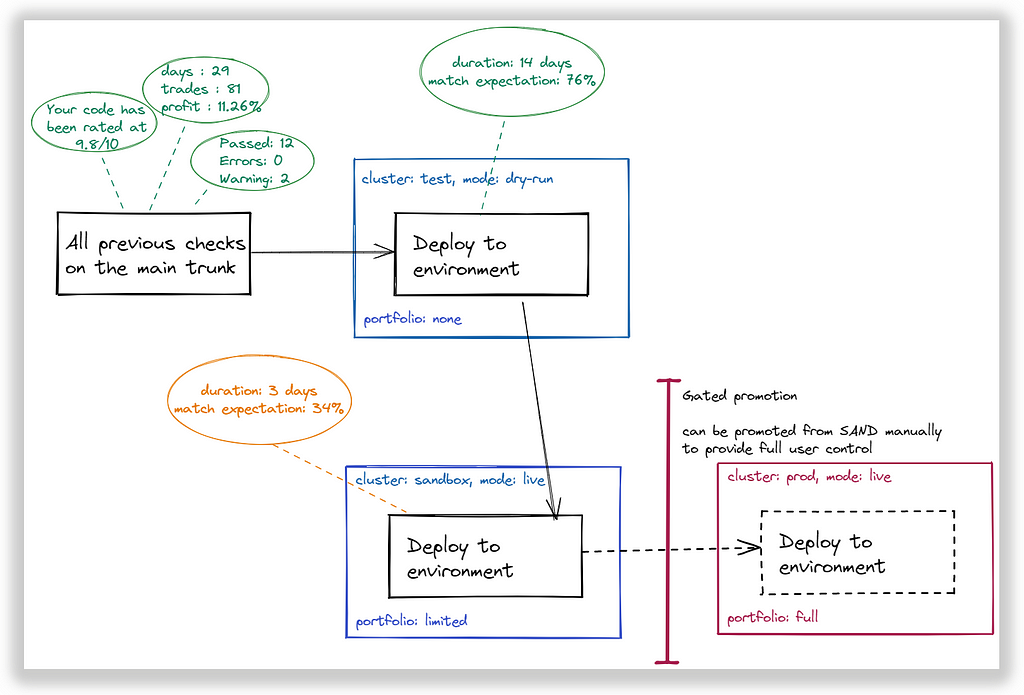
Obviously, our final goal is to have a strategy to be promoted to PROD environment for long-running execution. This can happen automatically (through monitoring actual execution during a specified timeframe) or manually.
Each environment monitors strategy effectiveness and uses this statistic for making decisions about its destiny — be promoted further or be rolled back.
Promote to test environment
Once a new strategy proposal matches all quality requirements — created pull request is available to be merged in the main branch and the “merge” button is activated.
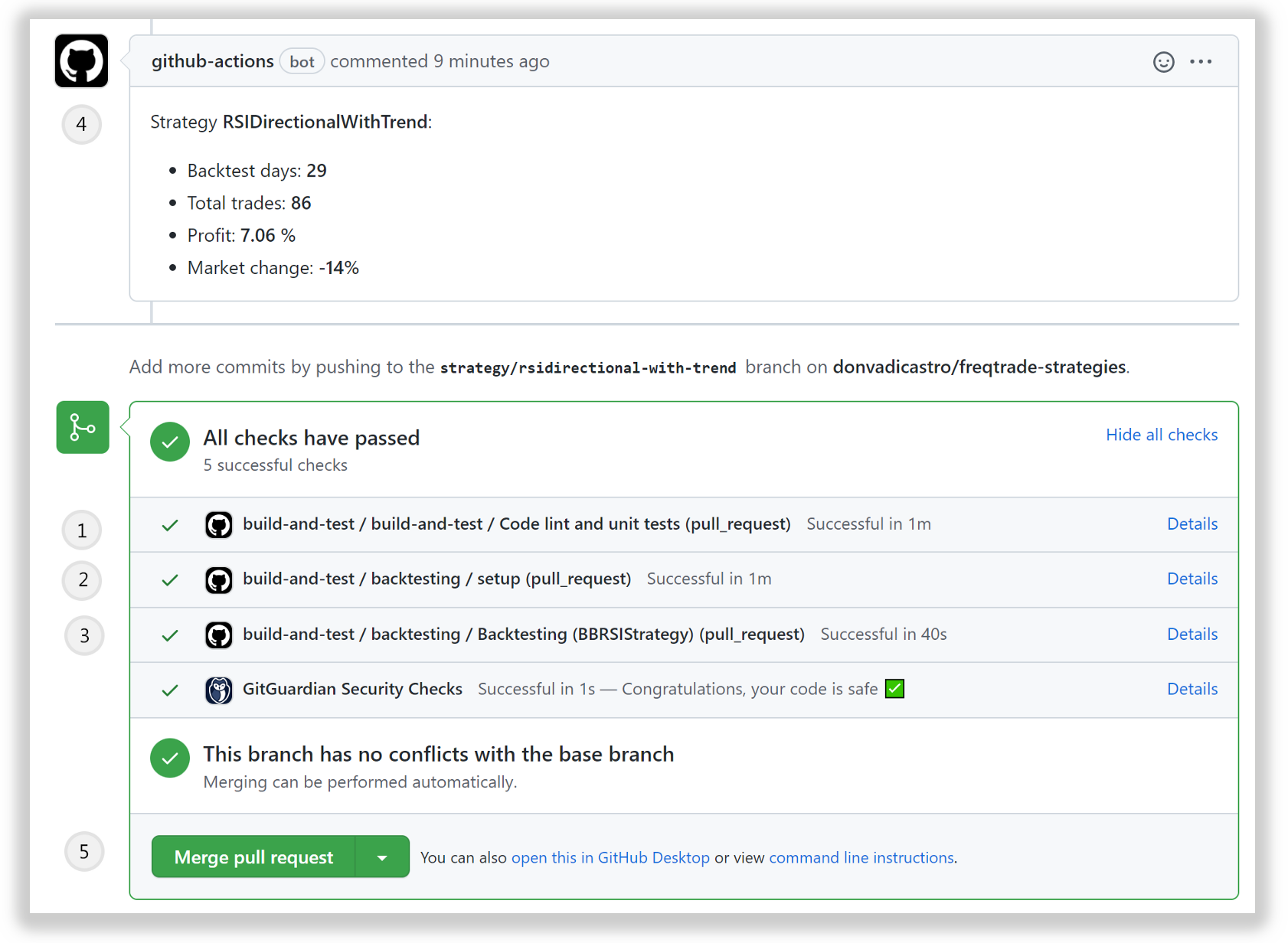
Let’s do a merge and this will trigger the start of the next stage in this CD pipeline — deploy to test environment.
Accepting the sensitivity of this topic and the dramatic consequences of security requirements violations (possible money loss) — we would avoid using the public cloud infrastructure to bootstrap the test platform. Let’s design a solution of a zero-trust network for digital assets trading in one of the next posts, but keep it fully isolated from external access for now.
Fortunately, github actions can help with this by providing support for internal platforms to be used as executable actors. We can register our own runner in our private infrastructure that will receive execution requests once an appropriate repository event will be triggered (in our case merge code to the main production branch).
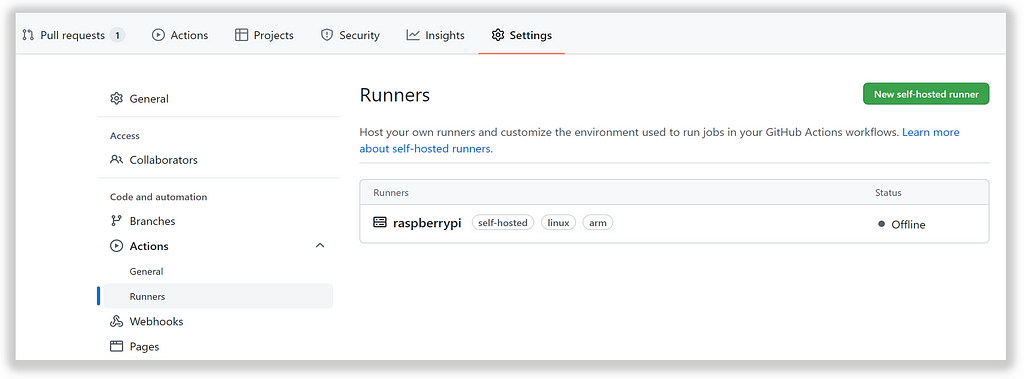
I will use my RaspberryPi device with docker bootstrapped on it. Additionally need to be installed job runner following detailed instructions.
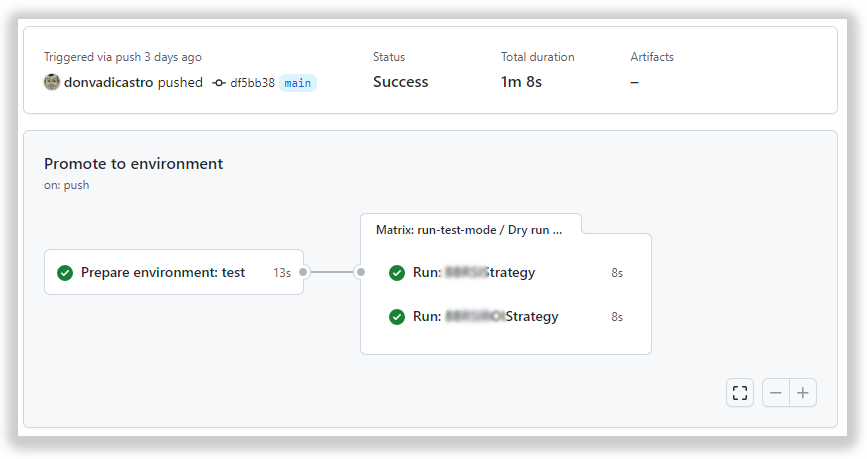
But how to differentiate — what particular strategy configuration will be used for a particular running environment. The last thing we want is to hardcode environment-specific config and store it in the repository — this is at least insecure.
let’s follow the 12-factor methodology and use the separate configuration per environment with a single config-free codebase deployed for all. Github can help to fulfill this requirement by using environments support for public (or paid private) repositories.
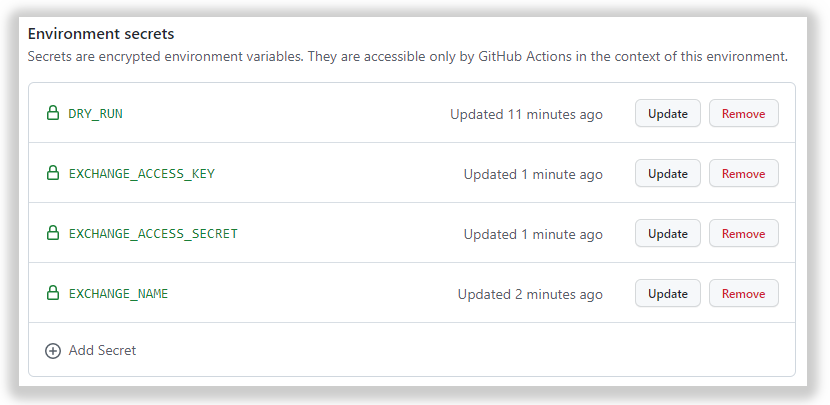
After creating a test environment, we can declare environment-specific config options that will be accessed on the custom runner through environment variables. We need at least this bare minimum of config options:
- dry-run — running mode, TRUE indicates that strategy is connected to the virtualized portfolio (no actual user account is used)
- exchange-access-key — user portfolio access key
- exchange-access-secret — user portfolio access secret
- exchange-name — self explanatory
Promote to the sandbox environment
So far so good. We have a strategy deployed to a test environment that has been running in dry-run mode to collect its own profitability metrics. Another “good” — all diffs between environments are in their configuration but not in environment-specific strategy design.
We can now inspect running statistics to make a decision to promote it further in release train or rollback to review and improve.
As a sandbox environment is already a place where you can lose your money because it requires some portfolio to be connected, the preferred way is to avoid automatic promotion, but put responsibility for this decision to the product owner. Anytime later promotion procedure can be fully automated.
So what is a good event to start promotion? I would choose “release tag created” as an event to react to. It has next benefits:
- the new release tag indicates that the solution passed all requirements checks
- it can be secured for particular roles only (e.g. only users in “ProjectAdmin”) to put the responsibility to a specific group of people only.
- as it requires a manual act, so it indicates some state of trust for delivered code increment based on other observations
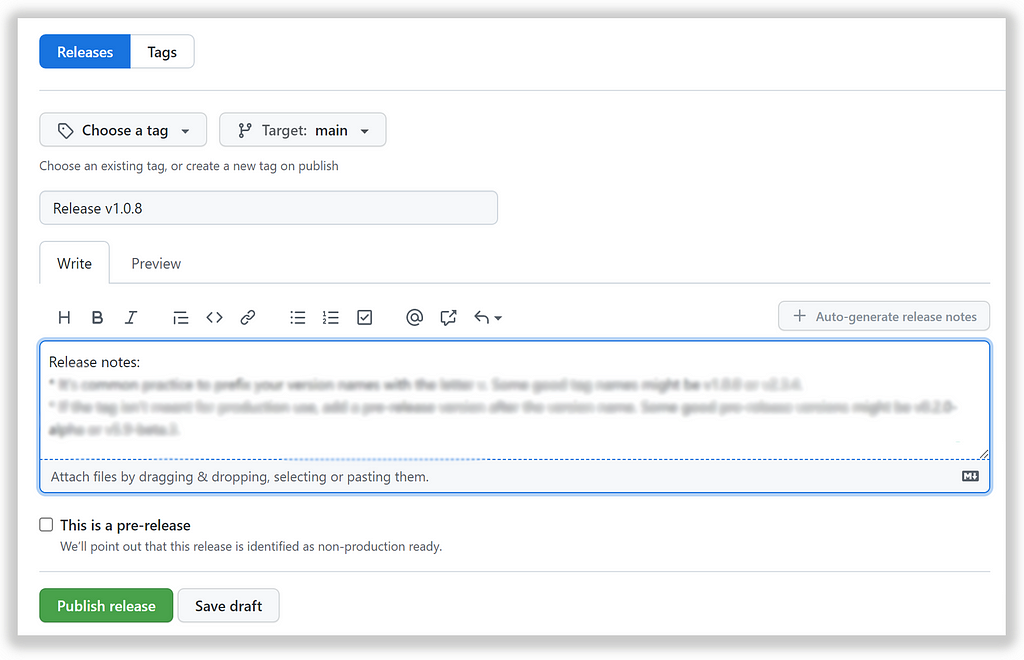
Release creation event will trigger a promotion pipeline that will use current artifacts as a source for strategy runner on the sandbox environment.
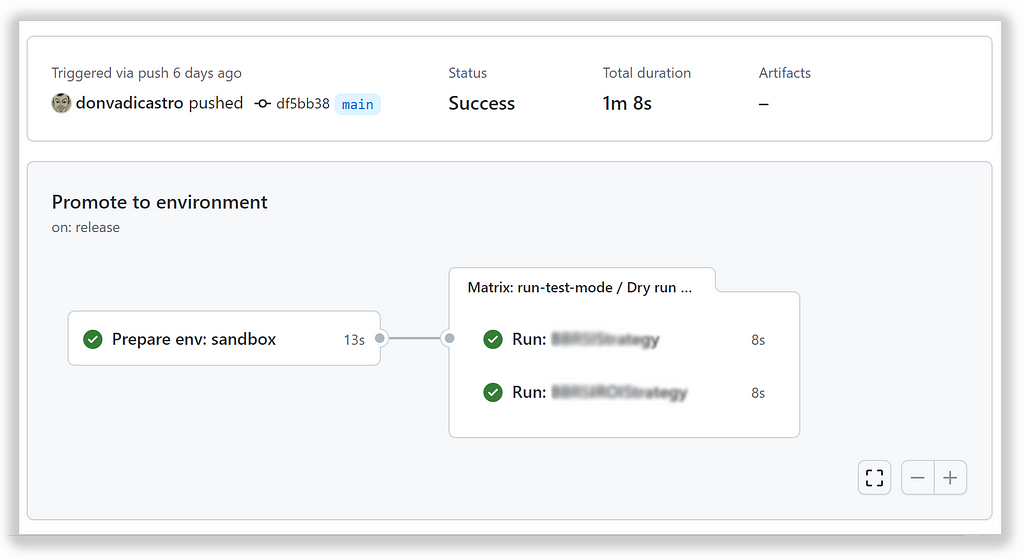
We are using the same runner, the only another configuration applied: live run with valid user credentials to access exchange API.
Voila, strategies are started in a while in production-like environment and signaled about their health status in telegram.
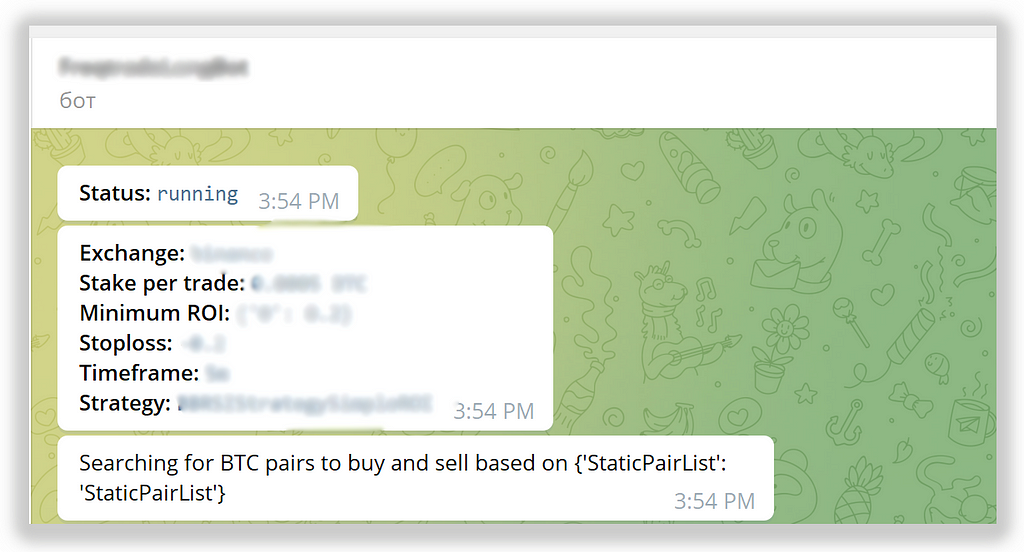
Toolset:
- Freqtrade in docker for strategy execution
- https://github.com/features/actions to automate the delivery
- https://github.com for collaborative development model
- RaspberryPI with docker engine installed
- Telegram bot to communicate with strategies runtime
Step5: observability (monitoring and alerting)
We can already relax and observe strategy execution. It requires some time to collect historical data to prove or object its efficiency.
But what about collecting this data automatically as data points and then aggregating them to visualize strategy efficiency in some monitoring tool?
Its effectiveness can be measured as a function of time. If we can define it (e.g. balance over time, percentage of wins over time, etc.), then we can collect data points, calculate results, and visualize its profitability as a function over this data.
Also, defined business metrics can help to make decisions to move strategy backward or forward in environments stack (e.g. from “SAND” to “PROD” if results are stable during a specified timeframe). Versatile monitoring and improved health check is also a prerequisite to keep strategy runner in a healthy state.
But let’s do a pause here as the post becomes too large and oversaturated with a different aspect.
CI/CD practices in crypto trading (part 2) was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.
This content originally appeared on Level Up Coding - Medium and was authored by Vadym Barylo
Vadym Barylo | Sciencx (2022-02-21T18:35:38+00:00) CI/CD practices in crypto trading (part 2). Retrieved from https://www.scien.cx/2022/02/21/ci-cd-practices-in-crypto-trading-part-2/
Please log in to upload a file.
There are no updates yet.
Click the Upload button above to add an update.